





What is an Agentic Data Plane?
What is it, why enterprises need it, and how to evaluate one
Command Query Responsibility Segregation (CQRS)—simplified








The world we all live in is event-driven. We respond to stimuli and take action every day. Event-driven architecture lets us model our applications to closely reflect that real-world behavior, using technologies like Zilla and Redpanda to support reliable communication between event-driven microservices.
The Command Query Responsibility Segregation (CQRS) architectural pattern is still somewhat shrouded in mystery. Redpanda is “simplified Kafka”, and Zilla is simplified API connectivity to Kafka. This pairing makes it super simple to build a CQRS example with the two platforms! A great example among many industries that use Redpanda and Zilla is real-time, person-to-person (p2p) payments.
The Zilla open-source API Gateway extends the reach of Redpanda beyond backend, inter-microservice communication to web and mobile applications, solving for first and last mile security, at the same level of operational simplicity, performance, and scale that users expect from Redpanda.
Zilla acts as an on-ramp to Redpanda, unlocking migration of the architectural backbone to be fully event-driven while maintaining application-specific RESTful endpoints for compatibility. Zilla also supports application-specific streaming endpoints for the CQRS pattern, allowing both microservices and end-users to react to stimuli, just like in everyday life.
In this two-part series, we’ll first break down each of these components. In the second post, we’ll walk you through an example p2p payment application called StreamPay, so you can see CQRS, Zilla, and Redpanda in action.
That said, let’s get into the theory.
RESTful APIs are a traditional approach for web applications, providing a synchronous request-response interaction pattern between clients and RESTful endpoints.
Application architectures that combine both RESTful APIs and an event streaming platform, such as Redpanda, often keep their RESTful microservices segregated from event streaming patterns. Each RESTful microservice typically logs an event stream of API activity, which can additionally “fan out” to other downstream event-driven microservices, including analytics pipelines.
Extending the reach of event-driven architectures (EDA) beyond the cloud (or on-premise data center) to include the Web client requires a mechanism to notify the client when a relevant event occurs. HTTP polling works, but puts unnecessary load on the system, even when there’s nothing to report. Alternatively, HTML5-friendly techniques, such as Server-Sent Events (SSE) and WebSockets bidirectional streaming are much more efficient.
Using these techniques to evolve beyond REST opens the possibility for more EDA patterns, such as CQRS.
CQRS (Command Query Responsibility Segregation) is a complicated name for a simple idea – allow the “read” data model and the “write” data model to differ, so that reads and writes can be optimized independently. Decoupling the reads from the writes allows for independent choice of technology for reads, best suited for the application use-case. Then the reads can be scaled independently and handled closer to the end user for an improved user experience.
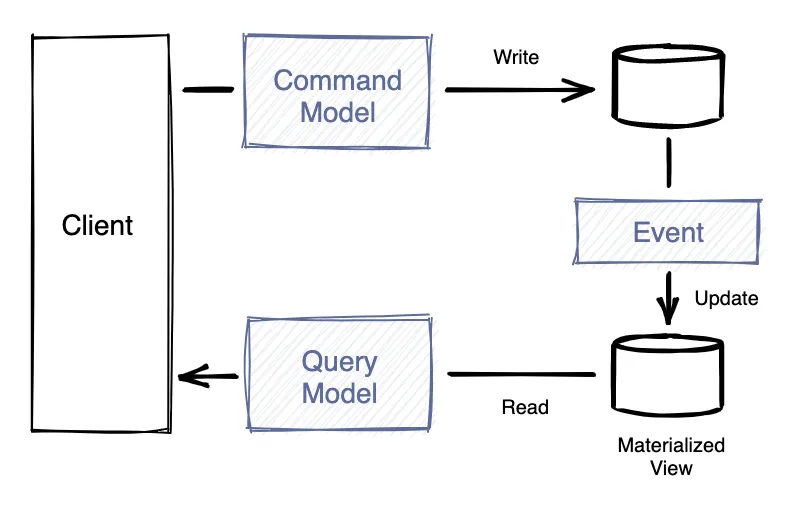
To put it simply:
Commands map naturally to a request-response interaction from the client. Zilla maps HTTP requests to a Redpanda commands topic, returning correlated responses from a Redpanda replies topic. An event-driven microservice handles inbound command messages by either processing or rejecting the requested mutation.
Queries can be satisfied by a read data model that’s better suited to the structure of query results needed by the client, which often differs from the structure of the write data model. An added bonus is that queries can also be served closer to the edge of the network to further reduce latency.
However, the read data model is derived from the write data model, so changes to the write data model need to be reflected in the read data model, albeit with a potentially different structure and at one or more different edge locations. This is commonly referred to as eventual consistency, where the read data model will reflect the write data model changes, but not in the same transaction, so there will be some delay. You might be thinking, “Eventual? How long will that take?!” Worry not, the delay can actually be imperceivable. Naturally, each application domain will have a different profile of how much latency is appropriate to reach consistency.
Reflecting the write data model changes at a remote read data model requires data distribution, which is where Redpanda comes in. Each event-driven microservice produces change events to a Redpanda topic for remote consumption. Zilla, as a consumer of Redpanda’s Kafka API, immediately consumes these changes from Redpanda, providing a continuously updated cache to satisfy client queries served from one or more edge locations.
Zilla can then use HTTP-based streaming protocols such as Server-Sent Events to deliver these change events to the client.
Now that you’ve seen how it all works, let’s touch on the challenges you might encounter when following a CQRS pattern.
Application architects typically face challenges when ensuring the correct handling of commands in the presence of unreliable networks or concurrent updates. And also when balancing the performance and freshness of query results. Here’s a breakdown of the most common challenges.
Commands are client requests to modify the write data model. If the network disconnects before the client receives a response, then it needs to retry the request so it’s not lost. Adding a unique idempotency-key header to the command request allows the command to be safely retried, but only if the service receiving the command can detect the duplicate and prevent a repeated action. This is often referred to as at-least-once delivery, with duplicate detection.
The main challenges for the server include how long to retain the knowledge of idempotency keys for previous commands to date by ct duplicates, and how to replay the original reply upon receiving a duplicate command.
Zilla and Redpanda combine to help solve both of these challenges. Here’s how it plays out:
replies topic determines how long the correlated reply message remains available.This approach makes duplicate detection simple and efficient for the event-driven microservice, with most of the heavy lifting being done by Zilla and Redpanda. Since Zilla is stateless, the duplicate command request can be detected and handled by any peer Zilla server in an auto-scaling group, such that idempotency remains straightforward even after a scale-out or scale-in of a Zilla server group.
When attempting concurrent updates on the same part of the write data model, you need to verify whether the context is still valid to either apply or reject the update.
Optimistic locking associates the object’s logical version with the command to modify the write data model. If the expected version matches the current version, the update is applied. If not, it’s rejected. It’s “optimistic” because all commands are accepted if there are no concurrent updates.
Zilla supports optimistic locking by generating an etag as part of the event identity for each message delivered on a Server-Sent Events stream. The remainder of each event identity is used for reliable delivery, allowing the client to recover the SSE stream successfully without loss, even after a network interruption.
When sending a command to update the write data model, the client can include an if-match header with the etag value from the SSE event identity, providing version context to the event-driven microservice to detect and reject a concurrent update. If another update arrives first, then the command can be rejected and the SSE stream will automatically receive a new message that reflects the first update.
Redpanda's native support for Kafka consumer groups allows us to shard the commands into different partitions, for example, based on a trusted end-user identity that can be injected by Zilla. This ensures that each part of the write data model is handled by a single consumer, so all commands for a given end user are handled in a predictable order, giving us the necessary precision to correctly enforce optimistic locking for each end user shard in the write data model.
In a CQRS-based approach, when a command is processed to update the write data model, there’s a delay while the change is propagated to the read data model(s). The acceptable amount of time for that delay will naturally vary depending on the business domain.
Zilla and Redpanda combine their high-performance streaming capabilities to instantaneously propagate these read data model changes from the microservice to a client. First via a Redpanda topic and then via a Zilla SSE stream.
As the number of clients grows, you may need to add more server resources to handle higher network connections and throughput, which can pose challenges. But, since all relevant CQRS state resides in Redpanda topics, there’s no affinity between a client and a specific Zilla server. This allows Zilla to work seamlessly even as servers are added or removed from an auto-scaling group of peer Zilla servers.
Zilla receives and validates all CQRS commands, ensuring that only valid commands are allowed to be processed by the event-driven microservices. This minimizes the overall load in the system to avoid bottlenecks. Zilla also receives all CQRS queries, serving query responses from a live cache that’s automatically synchronized with one or more topics in Redpanda. Similar to Redpanda, fanout is a first-class citizen at Zilla, so each message is delivered from Redpanda to Zilla only once, but can also be served to many different clients in parallel.
As the geographical distribution of clients increases, the combination of Zilla and Redpanda becomes even more powerful. With Zilla deployed at the edge and Redpanda’s Remote Read Replica clusters deployed in each availability zone or region for global data distribution.
Now that you’re familiar with the concepts of CQRS, we can put them in the context of a practical example so they can really sink in. In the next post, we dive into StreamPay — a p2p payments application built with Zilla and Repdanda that uses the CQRS pattern. We’ll cover both the setup and deployment of the application so you can experience CQRS for yourself!
In the meantime, you can dig into the documentation for Zilla and Redpanda. If you haven't already, try Redpanda for free and browse the Redpanda Blog for step-by-step tutorials. If you get stuck, have a question, or want to chat with the team and fellow Redpanda users, join the Redpanda Community on Slack.
What is it, why enterprises need it, and how to evaluate one

Enterprise agents need governance infrastructure, not just better models

A case study in keeping Redpanda topic names from drifting with contracts
Subscribe to our VIP (very important panda) mailing list to pounce on the latest blogs, surprise announcements, and community events!
Opt out anytime.