




Drag, drop, done: a visual composer for Redpanda Connect
Boxes and arrows for people who move billions of events a day. No per-row invoice required.

Walk through the thinking behind Redpanda and how it truly puts you in the driver’s seat








When people see your brilliant solution and start recommending it to others, it needs to be ready to scale. Perhaps you’ve already built something awesome with a simple request and response setup, and watched it crash under the pressure of too many incoming requests and events.
You should be able to start simple and not worry about massive traction crashing your app in the future. This is where asynchronous messaging comes in. Clients can send requests and spend their time doing something more fun than drumming their fingers until their updates are ready. Apache Kafka® is a popular solution. Its open-source platform takes events and writes them directly to the operating system’s memory cache. Kafka is good, but it can be slow.
That’s why we built Redpanda – an Apache Kafka-compatible streaming data platform designed from the ground up to be lighter, faster, and simpler to operate. There are no new binaries to install, no new services to deploy and maintain, and the default configuration just works.
So, how can you start making the most of your resources with Redpanda? In this post, I’ll walk you through the thinking behind Redpanda and how it truly puts you in the driver’s seat.
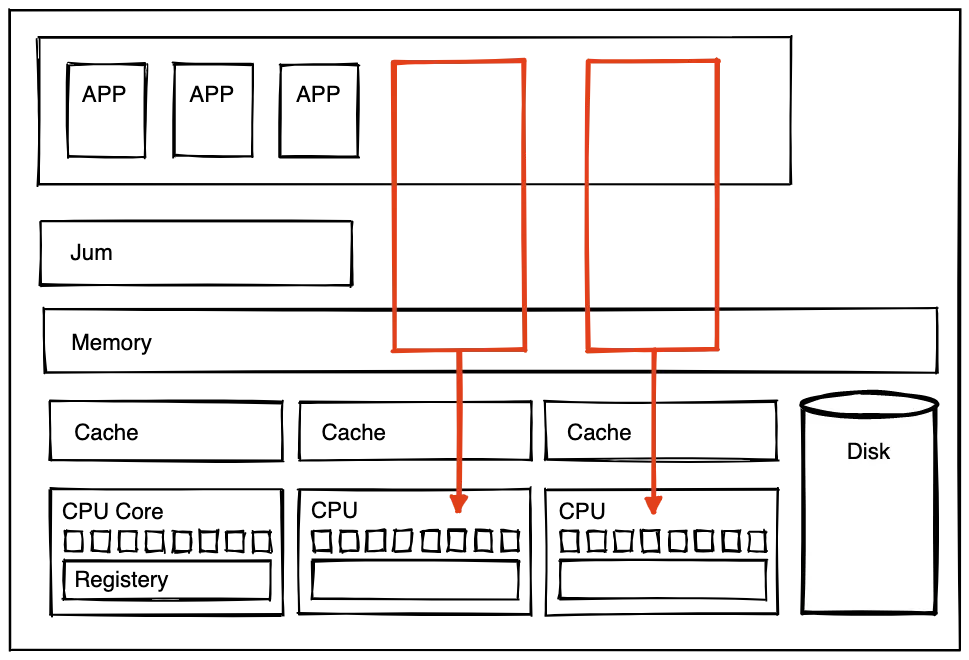
Modern computers are designed to handle various styles of applications and workloads. They reserve virtual memory for memory management and thread scheduling at the expense of their efficiency. This is useful when you’re dealing with unknown tasks, but not when you need dedicated computing power for particular purposes.
Kafka was created to bring the MapReduce approach to streaming on cheap spinning disks. Since Kafka came out in 2011, the bottlenecks in computing have changed. So Kafka introduced the Apache ZooKeeperTM framework to ease and centralize the management of configurations, which should help with coordinating the replication and scaling.
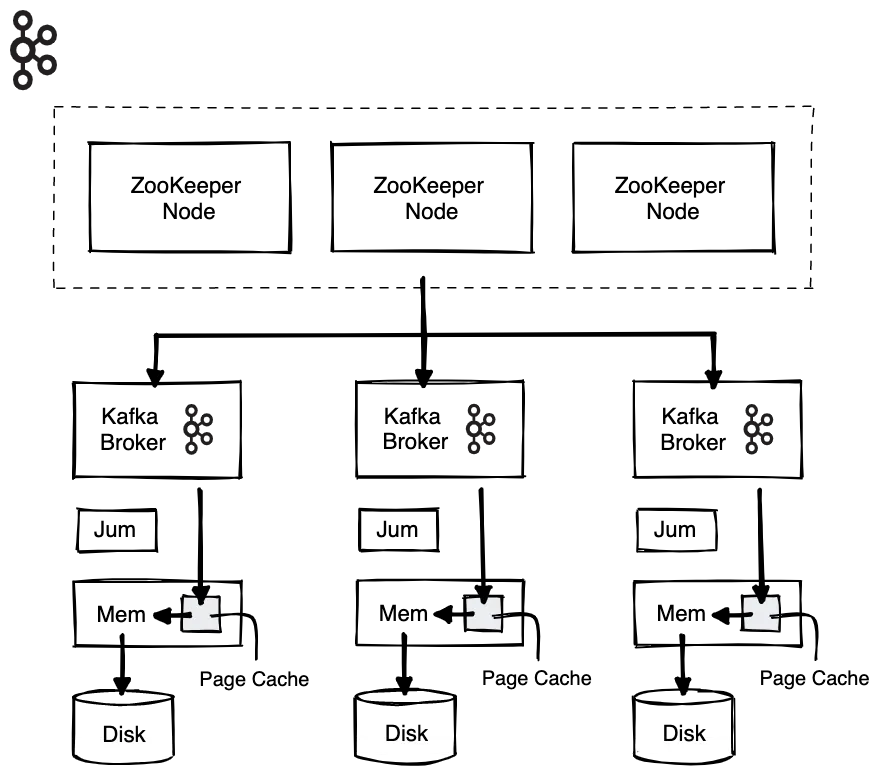
But with tons of devices, systems, applications,
and connectors jamming data into Kafka it still demands a lot of your computing resources. If you’ve been running real-time analytics in a distributed processing engine on top of all the other events, you’ve probably experienced some latency caused by heap management of Java Virtual Machine (JVM).
You can of course keep adding nodes and hardware to help with the workload. But this will drive up your costs exponentially.
Redpanda is an implementation of Kafka designed to optimize your multi-core computing resources so you can extract maximum performance from your hardware. Its core is written in C++, and it’s designed to rid you of the usual latency by making it perfectly clear what all your workloads are for.
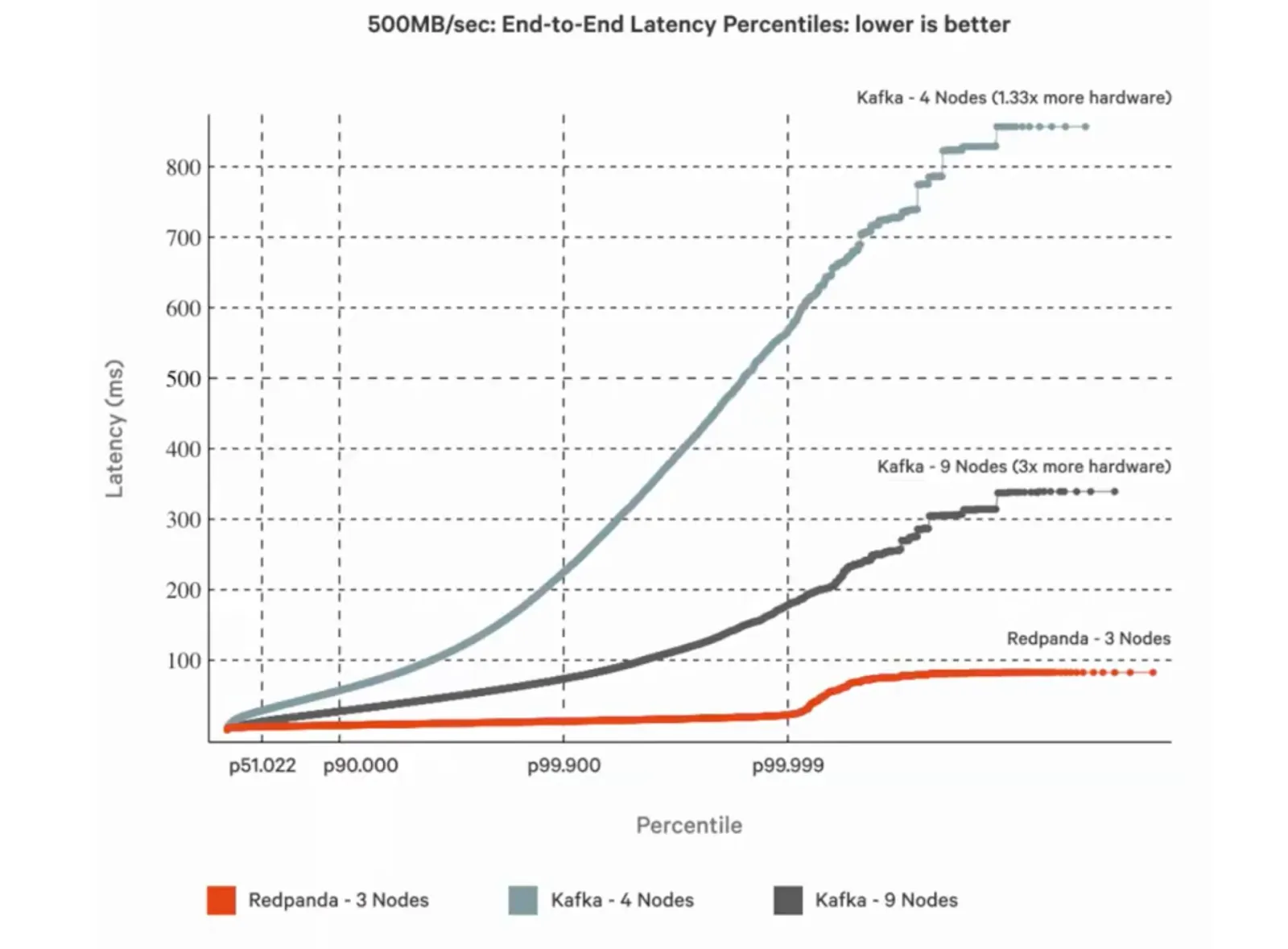
Because of the nature of how data is streamed, Redpanda can:
In short, Redpanda helps you harvest the most power from your available hardware. Its high-performing nature optimizes every last byte to give you 10x lower latencies, cut your cloud spend, and reduce your total costs by up to 6x compared to Kafka—all without sacrificing your data’s reliability or durability. It’s also JVM-free, ZooKeeper-free, Jepsen-tested, and source available.
If you’re using Kafka and want to make it more efficient, fast, and free from over-provisioning, I recommend switching to Redpanda. It’s as simple as leaving your old car on the congested highway and jumping into a new car that has a totally clear road ahead. We can’t recommend that you jump from your car to another one to avoid traffic—but that’s basically how you can use Redpanda to avoid queues, crashes, and unhappy users.
The gas pedal, steering wheel, and gear shifts are the same. But just listen to that powerful engine! It’s not a diesel-guzzling roar. It’s the sound of the energy-efficient Redpanda.
There are two Redpanda tools that I recommend in particular:
rpk): This is Redpanda’s command line interface (CLI) utility. You can use rpk to quickly spin up a Redpanda cluster. It has auto-completion commands to help you communicate, configure, and check cluster health. If you’re a visual learner, you’ll find it easier to see what’s going on in the cluster.When you switch from a diesel engine car to an electric one, you get double the trunk space. Suddenly you can place your most precious cargo where it suits you best. Similarly, Redpanda lets you deploy your clusters as you see fit.
Self-hosted Community edition
Run your Kafka-compatible clusters with all you need to get streaming. Our free edition meets basic needs for development and testing environments with support from the Redpanda Community Slack.
Self-hosted Enterprise edition
Store all the data you need at low costs and with full control. This makes it easy and fast to tailor your system to your needs. Redpanda Enterprise offers support with our 24x7 helpdesk, a direct Slack channel, a designated account manager, and access to solution experts. Try it for free.
Bring Your Own Cloud (BYOC) clusters
Host fully managed Redpanda clusters on your own cloud. You stay in control of your data and leave the administration of your clusters to us. This includes support for AWS and GCP as well as the same expert support as our Enterprise Edition. Try it for free.
Dedicated clusters
Deploy your fully managed Redpanda clusters on our dedicated resources in Redpanda Cloud. You get all the capabilities of Redpanda Enterprise, more time to focus on your business, and the same level of support as on the BYOC plan. Sign up for a free trial.
With Redpanda, there’s no need to add and deploy another set of management layers.
Stop worrying about dependencies
Redpanda is packaged and deployed as a single binary. Every single package is ready to run on your system (without any code changes). The brokers in the cluster handle configurations and replication with Raft – a distributed consensus algorithm, which is also being adopted by the Kafka community.
Better accuracy and endless possibilities for ML, testing models, and auditing
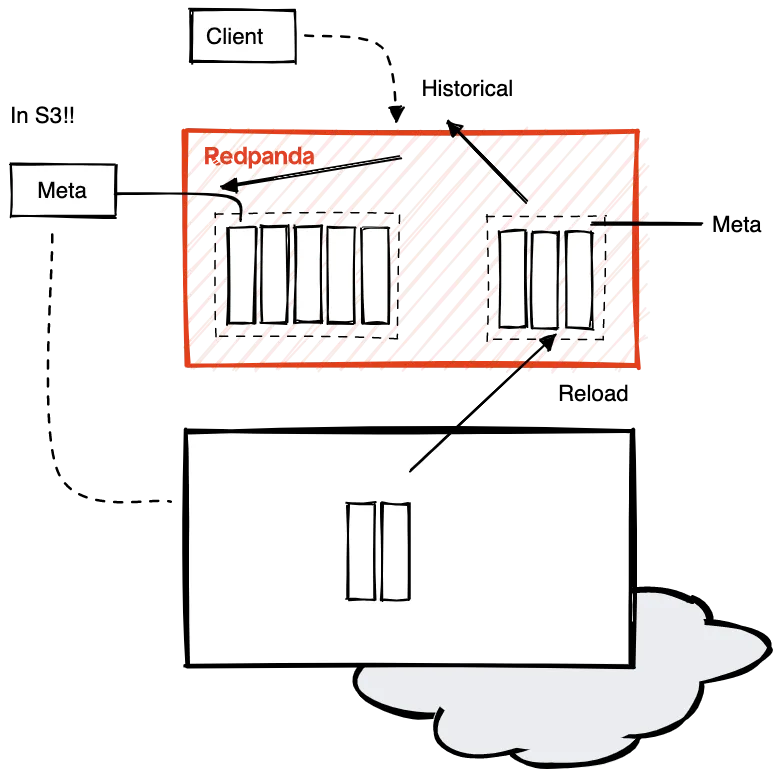
With its tiered storage support, Redpanda stores both real-time and historical data in object stores like Amazon S3, Google Cloud Storage, and Azure Blob Storage. This allows you to access them through a unified and standard access point – Kafka consumer API.
This is super handy for developers doing real-time analytics. You’ll be able to pull on both real-time input and historical data without sacrificing performance. This gives you more accurate results and endless possibilities for machine learning, testing models, and auditing.
Leave the tuning on autopilot
With Redpanda, you’ll benefit from (the very handy) auto-tuning. As you scale, it’s hard to predict how each broker will be hit with the load or unknown input sources. This could lead to imbalance and even idle nodes. Auto tuning makes sure replicas are distributed evenly and finely tunes your hardware.
Self-healing clusters
You can use Continuous Data Balancing to monitor the use and availability of nodes, racks, and disks. It also enables self-healing clusters that dynamically balance partitions.
Now you know that Redpanda is a Kafka-compatible streaming data platform with a C++ core. It drastically simplifies operations and can help you use the full power of your computers – virtual as well as bare metal – and storage.
Come join our Redpanda Community on Slack if you have any questions or need help running more workloads with fewer resources. Feel free to ping me @Christina Lin.
To keep learning about Redpanda and how it compares to what you’re using today, check out these posts:
Subscribe to our VIP (very important panda) mailing list to pounce on the latest blogs, surprise announcements, and community events!
Opt out anytime.

