




Bridge Queries in Redpanda SQL
Have your real-time cake and eat your analytics too
Two streaming data integration options. One winner for your real-time data pipelines









When looking for streaming data integration options, Kafka Connect is often the first solution you'll find. Since its release in 2016, Kafka Connect has been a popular choice for moving data between Apache Kafka® and various data sources.
However, Kafka Connect has its limitations. From complex deployment requirements to limited debugging and monitoring tools and rigid configurations, Kafka Connect is notoriously challenging to scale and troubleshoot.
Enter Redpanda Connect—a fresh approach to data integration that solves many of Kafka Connect’s pain points. Redpanda Connect simplifies deployment, configuration, and improves performance as a cloud-native, efficient alternative that’s fully compatible with Kafka API.
So, which one should you use in your real-time data pipelines? In this post, we’ll compare the key aspects of both options in terms of:
Let’s get started.
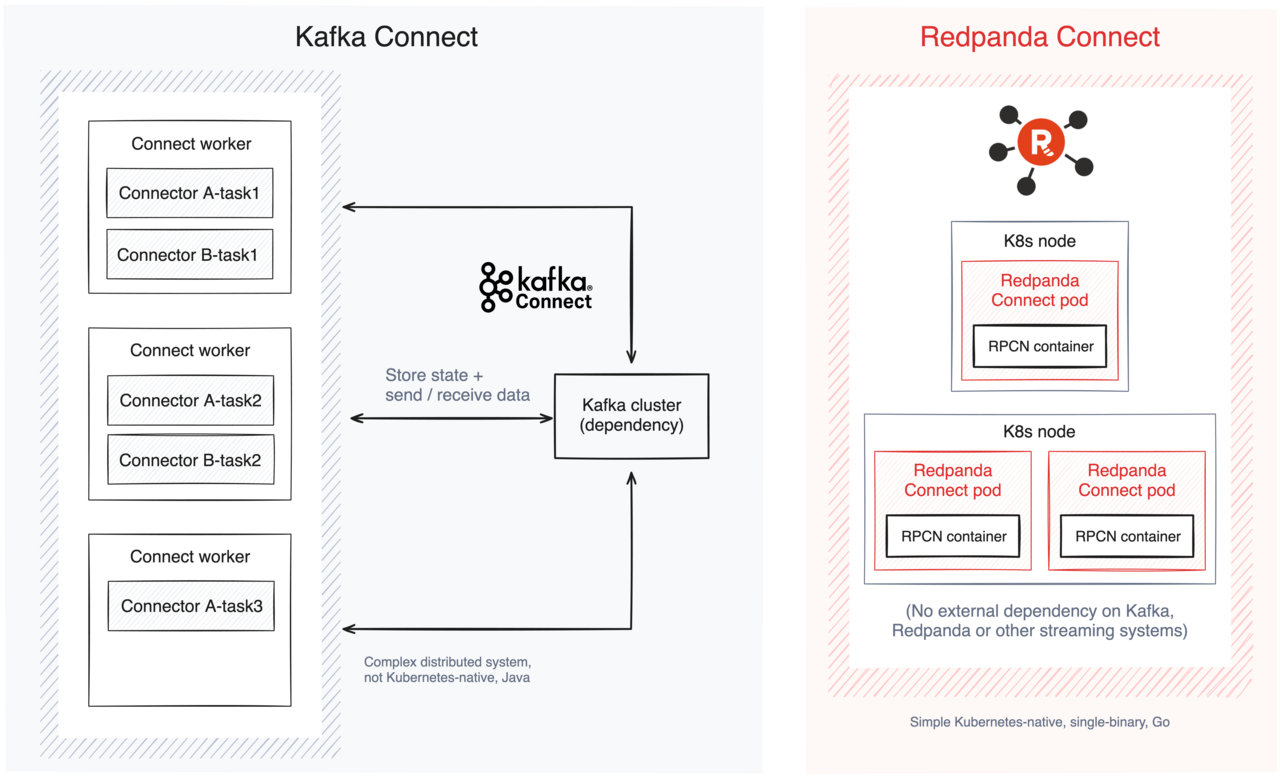
Kafka Connect runs on a Java-based distributed architecture, typically set up in “Distributed mode” for production environments. In this mode, multiple worker nodes manage the processing, and each connector’s work is split into tasks distributed across these workers. While this approach allows scalability and fault tolerance, it also introduces complexity.
Managing Kafka Connect’s distributed setup requires advanced configuration to ensure that each worker has the correct connectors, manages state consistently, and handles tasks in a fault-tolerant way. For example, you must thoroughly understand how to define a cluster with offset, configure status storage and stand up bootstrap servers, define worker replicas and each connector, etc.
Kafka Connect does offer a “Standalone mode” for simpler, single-node deployments, but this mode requires self-managing all necessary libraries and connectors, manually placing JAR files, configuring individual connectors, and restarting them with every change—limiting its feasibility for production environments.
Redpanda Connect, in contrast, skips the complexities of worker coordination, task rebalancing, and Kafka Connect's standalone configuration hurdles. Instead, it uses a cloud-native, single-binary setup and YAML configurations, removing the need for distributed node coordination, making it an ideal fit for serverless Kafka environments that prioritize simplicity and elasticity.
As a result, Redpanda Connect makes deployment straightforward. You can use Docker images or Kubernetes Pods to easily configure and redeploy connectors. Plus, Redpanda Connect’s unified architecture minimizes ongoing maintenance, reducing the technical burden and enabling quicker scaling without the intricate configuration Kafka Connect requires.
Kafka Connect includes single message transforms (SMTs) to handle basic data transformations within the pipeline, but setting up and testing SMTs can be error-prone. Kafka Connect offers only a handful of built-in transformations, so custom transformations often require creating from scratch in Java. Developing these custom SMTs is complex: you must write and compile Java code, then build, package, and upload the JAR file to the existing Kafka Connect image, which can be time-consuming and challenging, especially for teams without Java expertise.
Redpanda Connect simplifies data transformation with Bloblang, which is a powerful, built-in transformation language specifically designed for stream processing. Bloblang enables complex transformations directly within YAML configurations, removing the need for custom Java development. This approach not only makes transformations easier to read and test but also allows for quick iterations without the need for building or deploying JAR files. As a result, teams can create and refine transformations much faster, reducing overhead and enabling more agile development of data pipelines.
Kafka Connect’s distributed architecture in production often means that monitoring and debugging involve correlating logs from multiple sources, like different tasks, and installing additional infrastructures for log aggregation, like Elasticsearch, which can make troubleshooting difficult. Also, the log settings are stored separately from the rest of the configuration (connect-log4j.properties), making it annoyingly easy to lose track of critical logging details.
Redpanda Connect includes built-in observability components like tracing, logging, and metrics in the configuration integrated within the single-binary setup. This cohesive observability experience allows you to access real-time metrics and centralized logs, making it significantly easier to pinpoint issues without needing to trace logs across distributed systems. And, it supports StatsD, Prometheus, and other popular monitoring tools, with simple integration with existing observability stacks for real-time monitoring and debugging across environments.
{{featured-report="/components"}}
Happily enough, both Kafka Connect and Redpanda Connect support at-least-once delivery guarantees, but they achieve this in different ways.
Kafka Connect uses different state tracking mechanisms based on the mode that it's operating on. Standalone mode uses the local filesystem to track state, while the distributed mode tracks state inside of a using a Kafka Topic.
Redpanda Connect processes and acknowledges messages using an in-process transaction model with no need for any disk-persisted state, so when connecting to at-least-once sources and sinks, it guarantees at-least-once delivery even in the event of crashes, disk corruption, or other unexpected errors.
When using the Kafka protocol, offsets are stored using consumer groups, making scaling Redpanda Connect easy to scale and distribute work. However, other sources like GCP Pub/Sub or AWS SQS use the underlying primitives in those services to acknowledge work using the same unified in-memory transactional model.
Kafka Connect is purpose-built for streaming data pipelines and requires Kafka to act as either the source or the destination. Whereas Redpanda Connect supports modern AI-driven data pipelines.
We all know the transformative impact of generative AI, so Redpanda has introduced new AI connectors tailored for integration with major LLMs, whether hosted by cloud providers like AWS Bedrock, Google Vertex, or OpenAI or hosted in your own environment for data privacy/sovereignty requirements, (E.g., Llama, Cohere, etc). These connectors simplify data extraction so users can easily convert unstructured data into vector embeddings. You can also use them to stream these embeddings to various vector databases for GenAI agents and LLMs that rely on semantic understanding.
The bottom line is that Redpanda Connect acts as a powerful real-time data streaming agent/pipeline not only for traditional analytics but also for AI-enhanced insights and intelligent automation.
Kafka Connect is a solid choice with extensive connector compatibility and proven reliability. However, Redpanda Connect significantly improves scalability and data transformation flexibility, especially in environments where simplifying configuration, deployment, and maintenance is a priority. With native support for AI-driven data processing, Redpanda Connect offers a streamlined, future-focused alternative for real-time, intelligent data pipelines.
To start with Redpanda Connect, check out the documentation and the quickstart guide. If you have questions, drop into the Redpanda Community on Slack.
Subscribe to our VIP (very important panda) mailing list to pounce on the latest blogs, surprise announcements, and community events!
Opt out anytime.

