




Bridge Queries in Redpanda SQL
Have your real-time cake and eat your analytics too
What they are, pros and cons, and how to deploy them









Redpanda provides several options to optimize for a multi-region cluster, including leader pinning. Leader pinning is a feature in Redpanda that lets you specify preferred locations for topic partition leaders. This can help minimize the latency and throughput impact if the partition leader is in the same region as the producer or consumer.
Multi-region Redpanda clusters are a deployment topology that allows customers to run a single Redpanda cluster across multiple data centers or cloud regions. This is often referred to as a stretch cluster, where a single cluster stretches across multiple geographic regions with data distributed across all deployment regions. Data is replicated synchronously via raft protocol between brokers distributed across multiple regions and is also accessible from various points globally.
Key performance considerations when deploying a multi-region Redpanda cluster include network latency, data replication overhead, cross-region bandwidth costs, client-side routing and proximity, and consistency vs. availability tradeoffs. Network latency can result in higher latency for cross-region writes and reads and slower response times. Data replication overhead can increase network traffic and resource utilization. Cross-region bandwidth costs can lead to higher operational costs and potential bottlenecks. Improper client-side routing can lead to increased latency and higher load on certain regions. Strong consistency may result in higher latency for cross-region writes, while eventual consistency can improve performance but may lead to stale reads.
The major benefits of deploying multi-region Redpanda clusters include high availability and disaster recovery, performance, and simplified operations. Multi-region clusters offer superior resilience against region-specific failures because data is distributed across multiple regions. By placing data closer to users, you can reduce the time it takes for data to travel across the network, resulting in faster response times. Managing a single stretch cluster, despite its geographic spread, can be more cost-effective and less complex than maintaining multiple independent clusters.
In a multi-region Redpanda cluster, Raft ensures strong consistency in achieving quorum during writes. This ensures the maximum replicas across all regions have the same data simultaneously, which can increase latency. If strong consistency is not an absolute requirement but availability is, at the expense of slightly older data, multiple independent Redpanda clusters across different regions with MM2 replication can be set up. This prioritizes cluster availability allowing regions to operate independently but can lead to slightly older data that is a factor of how quickly replication can occur.
Welcome to part four of our series on high availability (HA) and disaster recovery (DR) with Redpanda. Part one focuses on failure scenarios and fundamental concepts, such as partition leadership/rebalancing and rack awareness.
Part two focuses on achieving the highest availability possible within a single-availability zone, using either Partition Placement Groups, Flexible Scale Sets, or Instance Placement Policies, depending on which cloud provider you use.
Part three focuses on considerations when deploying a cluster in multiple availability zones, also known as multi-AZ, and how AZ-level resiliency is achieved by spreading partition replicas across multiple availability zones.
In this fourth blog post, we discuss multi-region stretch clusters in Redpanda that provide the highest resiliency and availability. We will also discuss the pros and cons of this deployment architecture and architectural considerations while deploying multi-region Redpanda clusters.
Although data centers and public clouds have come a long way, regional outages can still happen. For example, in the recent LA fires — if there were an us-west region in the Palisades area, the chances of that data center region surviving would be very low. Most calamities are unpredictable, so making systems resilient and tolerant to even the wildest failures is the only way to ensure business continuity.
Furthermore, businesses are no longer confined to a single geographic location in today's fast-paced, data-driven world. With users and services spread across the globe, the need for highly available and resilient data systems has never been greater.
A multi-region Redpanda cluster is a deployment topology that allows customers to run a single Redpanda cluster across multiple data centers or multiple cloud regions. It’s often referred to as a stretch cluster, where a single cluster stretches across multiple geographic regions with data distributed across all deployment regions. Data is replicated synchronously via raft protocol between brokers distributed across multiple regions and also accessible from various points globally.

Major benefits of this deployment topology include:
High availability and disaster recovery: Multi-region clusters offer superior resilience against region-specific failures because data is distributed across multiple regions. This design is vital for mission-critical applications where downtime directly impacts reputation and revenue.
Unlike in asynchronous replication, where you have two separate clusters with MirrorMaker2 replication between them and a non-zero RPO, multi-region clusters have RPO=0 and very low RTO when there is a region-level outage. This is because new leaders are automatically elected — as part of the Raft protocol — in the surviving regions when any region goes down. The replication factor on the cluster or topics tells you how many region failures can be tolerated for the cluster to continue to serve the application layer.
Performance: By placing data closer to users, you can reduce the time it takes for data to travel across the network, resulting in faster response times. Data can be located closer to users via adopting architecture patterns, such as read replicas, follower fetching, or leadership pinning. Latency is reduced, ensuring faster access to data. This is super useful in Fintech, like real-time fraud detection, which has global users and requires low latency for a smooth user experience.
Simplified operations: Managing a single stretch cluster, despite its geographic spread, can be more cost-effective and less complex than maintaining multiple independent clusters. This is especially true if you're attempting to cover a region-level outage, and not concerned with a coordinated failure of the entire cluster.
When deploying a multi-region cluster, the following factors can impact performance.
Network latency is the time it takes for data to travel between regions. In a multi-region setup, producers and consumers may be located in different regions, which can increase the time it takes for data to be written or read.
Implications:
Replicating data across regions requires additional network bandwidth and computational resources. This overhead can impact the overall throughput and latency of the system.
Implications:
Transferring data between regions can incur significant bandwidth costs, especially in cloud environments where cross-region data transfer is billed separately. Some of these costs can be mitigated with Follower Fetching or Leadership Pinning.
Implications:
Learn how to calculate cloud data transfer costs and different techniques to minimize them.
Producers and consumers need to connect to the nearest region to minimize latency. However, improper routing can lead to sub-optimal performance.
Implications:
Raft ensures strong consistency in achieving quorum during writes in a multi-region setup. This ensures the maximum replicas across all regions have the same data simultaneously, which can increase latency.
If strong consistency is not an absolute requirement but availability is, at the expense of slightly older data, multiple independent Redpanda clusters across different regions with MM2 replication can be set up. This prioritizes cluster availability allowing regions to operate independently but can lead to slightly older data that is a factor of how quickly replication can occur.
Implications:
Reads and writes in Redpanda by default go to the partition leader. In a multi-region stretch cluster, the leader partitions could end up in any region, forcing a cross-region read or write depending on where the client is. The latency and throughput impact is minimized if the partition leader is in the same region as the producer or consumer.
Redpanda provides several options to optimize for a multi-region cluster:
Leader pinning is a feature in Redpanda that lets you specify preferred locations for topic partition leaders and pin to specific regions in a multi-region cluster. Leader pinning ensures a topic's partition leaders are geographically closer to clients. This helps decrease networking costs and guarantees lower latency by routing produce/consume requests to brokers located in specific regions.

Leader pinning is an enterprise feature that requires a valid license. It's available for both Self-Managed Redpanda clusters and Redpanda Cloud.
For scenarios where produce latency exceeds requirements, you can configure producers to use acks=1 instead of acks=all. This reduces latency by only waiting for the leader to acknowledge rather than the replication factor and quorum of brokers. However, this comes at the cost of potentially decreased message durability.
Additional producer configurations, such as batch.size and linger.ms, can be tuned along with the acks configuration to achieve the best performance.
To learn more about performance configurations in Redpanda, check out our blog series on batch tuning in Redpanda for optimized performance.
Follower fetching is a feature in Redpanda that allows consumers to fetch records from the closest replica of a topic partition, regardless of whether it's a leader or a follower. This feature is particularly beneficial for Redpanda clusters in multi-region or multi-AZ deployments.

Follower fetching helps reduce latency and potential costs associated with multi-region deployments by allowing consumers to read from geographically closer followers. Follower fetching can also help reduce network transfer costs and lower end-to-end latency in multi-region deployments.
To dive deeper into this feature, read our blog on understanding follower fetching in Redpanda.
A Remote Read Replica topic is a read-only topic that mirrors a topic on a different cluster. It works with both Tiered Storage and archival storage.
Remote Read Replicas allow you to create a separate remote cluster for consumers of a specific topic, populating its topics from remote storage. This can serve consumers without increasing the load on the origin cluster. These read-only topics access data directly from object storage instead of the topics' origin cluster, which means there's no impact on the performance of the original cluster. Topic data can be consumed within a region of your choice, regardless of where it was produced.
To learn more about this feature, read our blog post on Remote Read Replicas: Read-only topics in tiered storage.
Multi-region Redpanda clusters are currently available in Self-Managed deployments on VMs, bare metal or cloud compute instances. Redpanda Cloud, both Dedicated and BYOC offerings. Self-Managed on K8s currently supports only multi-AZ deployments in all the cloud providers.
For Self-Managed, you can manually deploy such a cluster or create a cluster using our Ansible collection. Once you create the VMs in the regions of your choice, you can create a hosts.ini file with the region information specified as rack information per broker. Then, run the Ansible install to create a multi-region Redpanda cluster.
Here’s a snapshot of the steps involved in using Ansible install:
# Verify that the racks have been correctly specified in the host.ini file:
export HOSTS=$(find . -name hosts.ini)
head -4 $HOSTS
[redpanda]
34.110.102.41 ansible_user=adminpanda ansible_become=True private_ip=10.168.0.41 rack=us-west-2
35.236.35.49 ansible_user=adminpanda ansible_become=True private_ip=10.168.0.39 rack=us-east-2
35.114.39.36 ansible_user=adminpanda ansible_become=True private_ip=10.168.0.40 rack=eu-west-2
# Install Ansible Galaxy Roles
ansible-galaxy install -r ./requirements.yml
# Provision the cluster with Ansible
ansible-playbook ansible/provision-basic-cluster.yml -i $HOSTS
### Verify that Rack awareness is enabled
# SSH into a cluster node substituting the username and hostname from the values above
ssh -i ~/.ssh/id_rsa <username>@<hostname of redpanda node>
# Check rack awareness is enabled
rpk cluster config get enable_rack_awareness
true
# Check the brokers are assigned to distinct racks
rpk cluster status | grep RACK -A3
ID HOST PORT RACK
0* 34.110.102.41 9092 us-west-2
1 35.236.35.49 9092 us-east-2
2 35.114.39.36 9092 eu-west-2To performance test a multi-region Redpanda cluster and avoid the expenses associated with it, you might want to skip setting up an actual multi-region cluster. Alternatively, you can use our OpenMessaging Benchmark (OMB) repo on GitHub, which allows you to benchmark any Redpanda cluster.
To simulate a multi-region Redpanda cluster, we set up a 3-node Redpanda cluster with i3en.xlarge VMs. These VMs have four cores per node with 32 MB of memory each, and simulate a Tier-2 Redpanda Cloud cluster. We used tc to only add network latency between Redpanda brokers. No network latency was added between the OMB worker nodes and Redpanda broker nodes to simulate leader pinning.
In your environment, you can use leader pinning to configure and pin partition leaders to the region of your choice.
name: Redpanda+3xi3en.xlarge
driverClass: io.openmessaging.benchmark.driver.redpanda.RedpandaBenchmarkDriver
replicationFactor: 3
reset: true
topicConfig: |
commonConfig: |
bootstrap.servers=<ip1>:9092,<ip2>:9092,<ip3>:9092
request.timeout.ms=300000
producerConfig: |
acks=all
linger.ms=1
batch.size=131072
consumerConfig: |
auto.offset.reset=earliest
enable.auto.commit=falsename: 50MB/s rate; 4 producers 4 consumers; 1 topic 144 partitions
topics: 1
partitionsPerTopic: 144
messageSize: 1024
useRandomizedPayloads: true
randomBytesRatio: 0.5
randomizedPayloadPoolSize: 1000
subscriptionsPerTopic: 1
producersPerTopic: 4
consumerPerSubscription: 4
producerRate: 50000
consumerBacklogSizeGB: 0
testDurationMinutes: 5
warmupDurationMinutes: 5The graph below showcases how the latency is impacted at different “stretch” configurations for various ack values. All runs were on a Tier-2 cluster and achieved a throughput of 50 MBps.
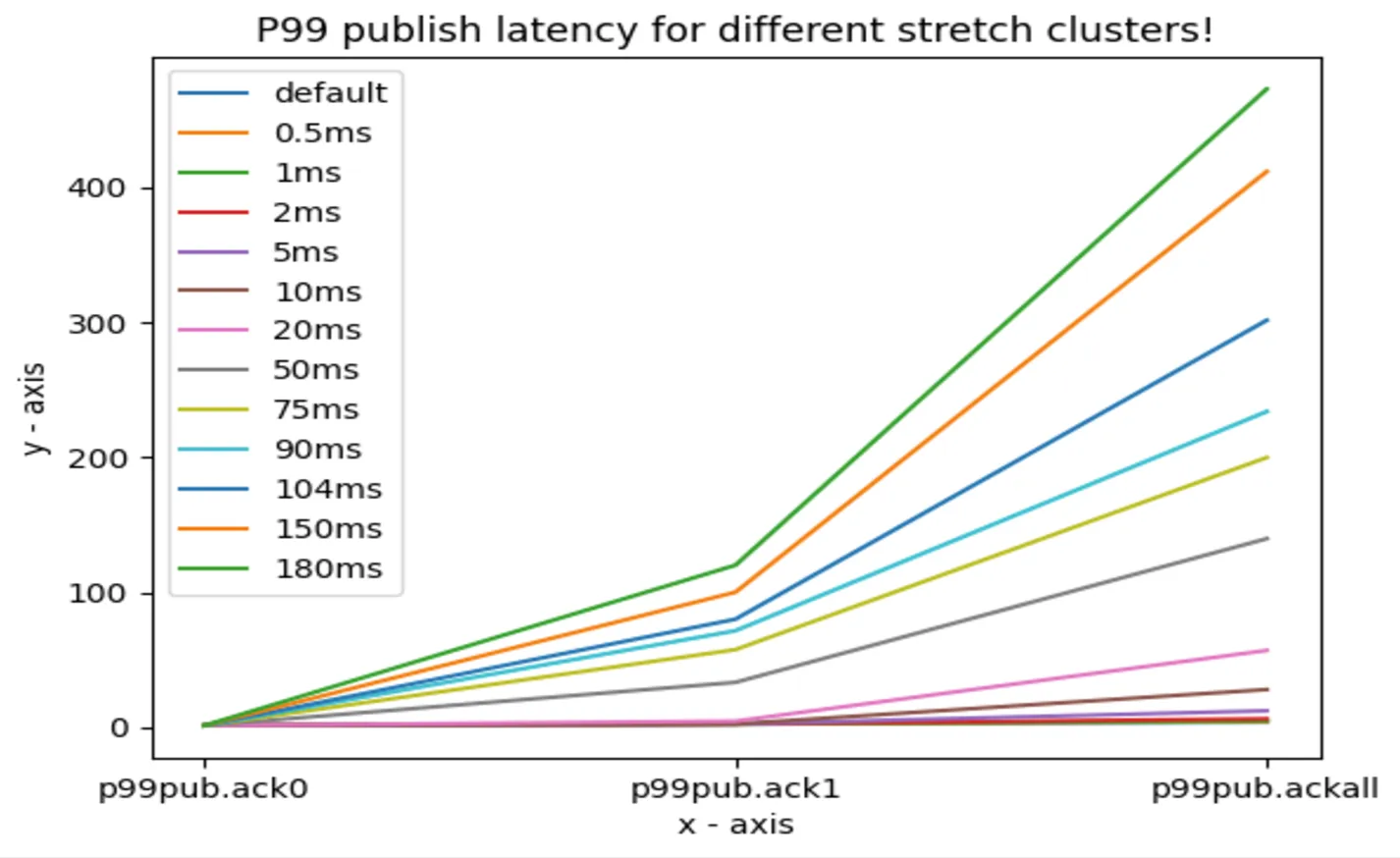
Redpanda’s multi-region clusters empower developers and organizations to build robust and resilient globally distributed, scalable, and highly available data streaming systems. With its performance-first architecture, simplified operations, and Kafka API compatibility, Redpanda is the ideal choice for modern streaming workloads.
Whether you’re building a global gaming platform, a financial trading system, or an IoT network, Redpanda’s multi-region capabilities ensure your data is where it needs to be — delivering high performance, low latency, and high availability, even in geographically distributed environments.
To get started with Redpanda, sign up for a free trial or get in touch for a demo and our team will lead the way.
Subscribe to our VIP (very important panda) mailing list to pounce on the latest blogs, surprise announcements, and community events!
Opt out anytime.

