





Bridge Queries in Redpanda SQL
Have your real-time cake and eat your analytics too
Redpanda Platform and Redpanda Cloud get boosts to power, scale, cost-efficiency, operational simplicity, and Kafka ecosystem support.








In our recent Series C funding announcement, we noted our commitment to evolving Redpanda beyond the scope of legacy streaming data platforms, with a focus on empowering engineers to build the next generation of data applications and pipelines.
We’re happy to now release Redpanda 23.2, bringing the next stage of our evolution with even more power, scale, cost-efficiency, operational simplicity, and Kafka ecosystem support. The new capabilities detailed in this blog are generally available for both the self-hosted Redpanda Platform and fully-managed Redpanda Cloud deployments (except where otherwise specified).
Let’s take a closer look at what’s packed into this new release.
Our goal with Redpanda is to offer a streaming data platform with no tradeoffs between performance and reliability when running at GBps+ scale. The 23.2 release continues to move the needle in that direction.
Last year, we introduced Redpanda Tiered Storage—with S3-compatible cloud object storage as the default storage tier—to reduce data retention costs by up to 10x and provide unified access to both historical and real-time data using the same API. Today, we’re enhancing Redpanda Tiered Storage to be even more seamless, automated, and efficient when scaling for large workloads in the cloud. These updates have the added benefit of helping to lower your cloud storage bill!
Here’s what changed:
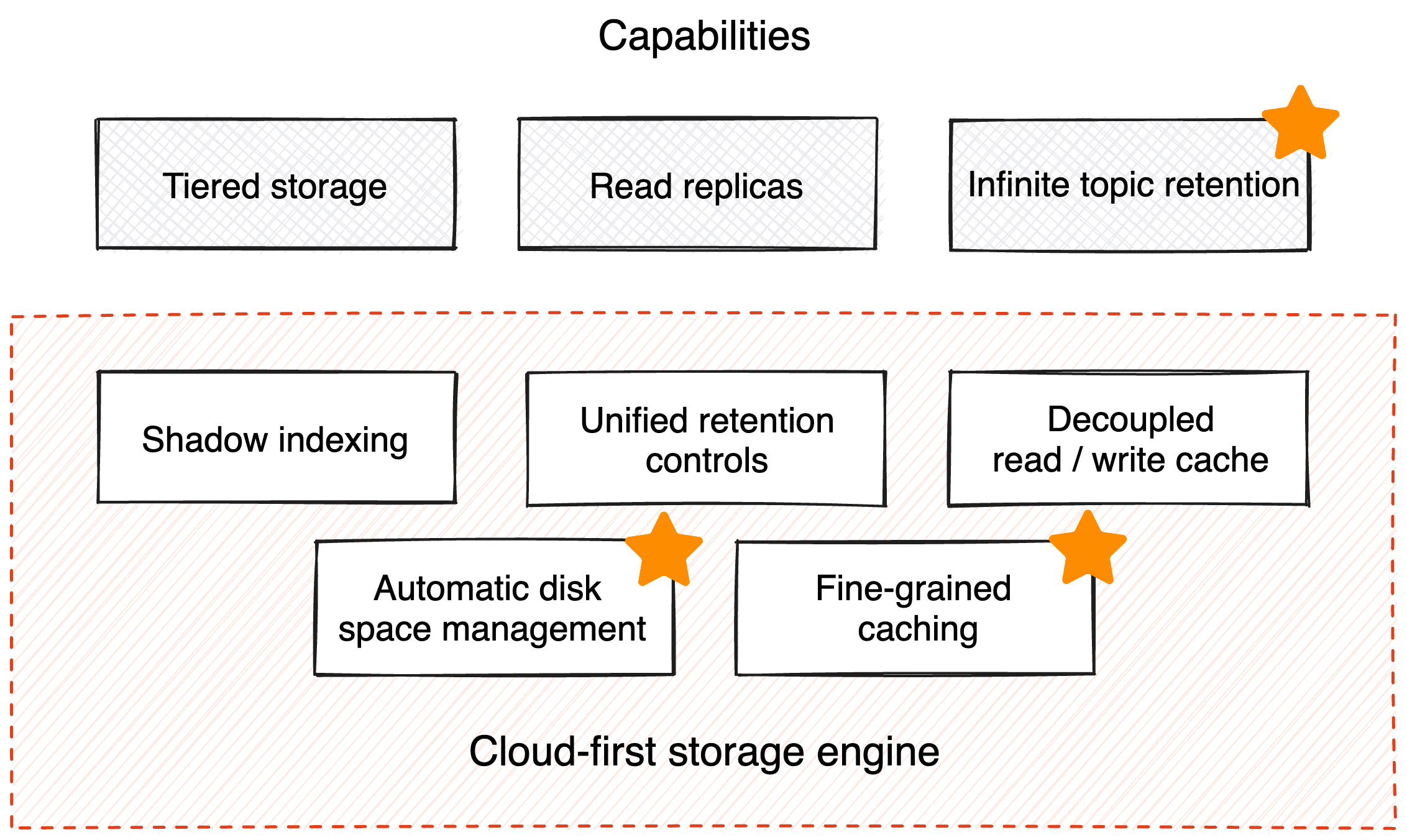
We’ve also added a number of improvements to make Redpanda more robust and powerful by preventing hotspots, improving efficiency, and optimizing performance for high-throughput workloads. These improvements include:
[CTA_MODULE]
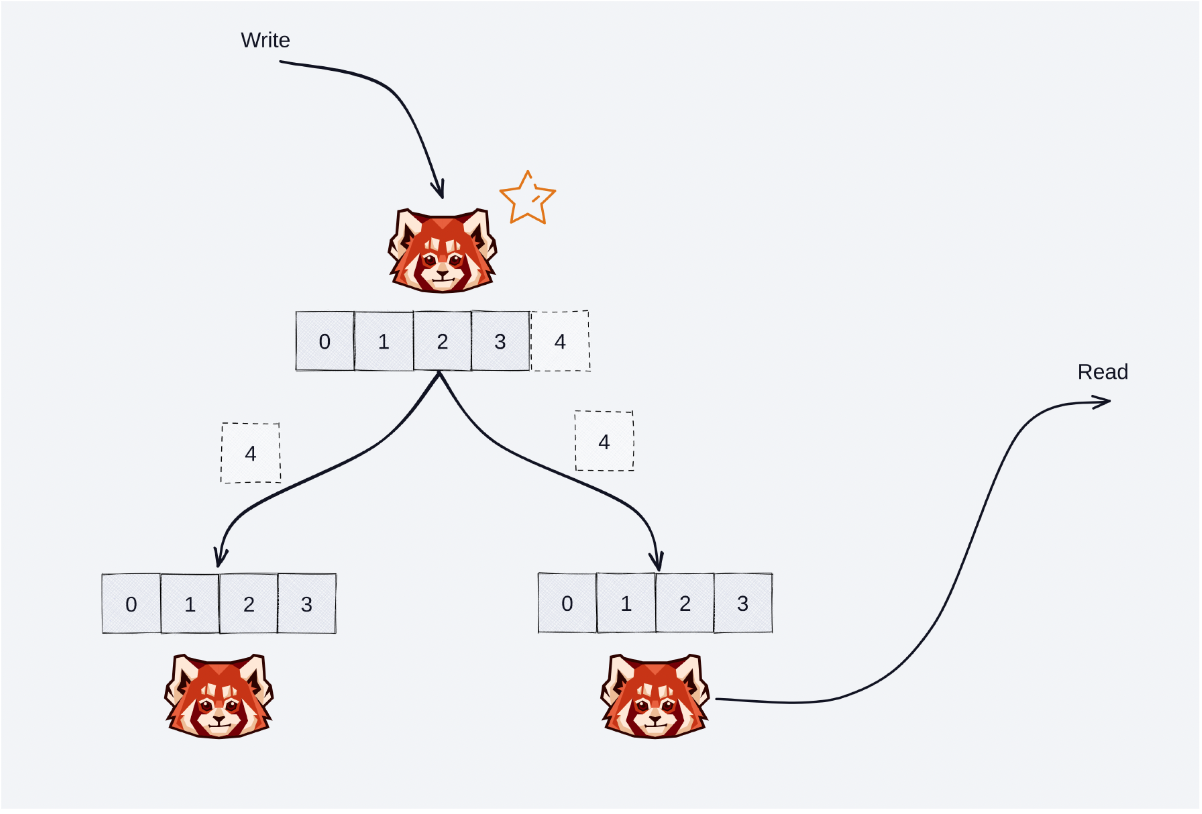
In June, we announced follower fetching as an upcoming feature. Today we’re happy to share that it’s generally available for Redpanda self-hosted and Redpanda Cloud users.
Follower fetching enables your Redpanda consumers to fetch records from the closest physical replica of a topic partition, regardless of whether it’s a leader or a follower, to reduce network traffic for cross-AZ and cross-rack deployments. Ultimately, this can save you up to 50% on your infrastructure costs for read-heavy workloads in certain public clouds (check out the beta announcement blog to see a real-world example of cost savings on AWS).
In addition to cost savings, with follower fetching you can also reduce read latency for consumers and support additional read throughput via more efficient use of network bandwidth by all nodes in the cluster.
rpk, Redpanda Console, K8s, Ansible, TerraformRedpanda 23.2 includes a revamp of rpk—the command line experience—to help accelerate complex streaming data projects and improve cloud integration, including cluster profiles, Tiered Storage insights, and autocompletion.
rpk, our command line interface (CLI) utility, helping to standardize and accelerate work happening across different clusters. Users can create multiple profiles for multiple clusters and swap between them with rpk profile use.rpk topic describe-storage, including detailed information on local and cloud storage usage, and time of last write to object storage.rpk command and then use the tab key to complete it automatically—just like with a search engine or word processor.Here's a peek at the new and improved rpk — simplifying admin across multiple environments:

For a full breakdown of the new rpk functionality, check out the Redpanda documentation.
For self-hosted deployments, it is now easier to integrate with your identity and access management (IAM) and encryption infrastructure with Redpanda Console, our powerful GUI for managing and troubleshooting applications, thanks to the following updates:
We’re also making it easier than ever for Redpanda developers and administrators to deploy and manage self-hosted Redpanda clusters in cloud-native environments, with our improved Kubernetes (K8s) operator, and new Ansible and Terraform capabilities:
Redpanda functions as a drop-in replacement for Apache Kafka®, and to that end, we’re dedicated to ensuring API compatibility with the Kafka ecosystem. In addition to follower fetching, we’ve also added support for the Kafka deleteRecords API.
If you’re not familiar with deleteRecords, it’s exactly what it sounds like—it lets you delete records from a topic, from the beginning of a partition up to a specific offset. This is helpful if you need to free up disk space. For example, if your producers are pushing more data than anticipated, or if you want to trim the data that’s available to clients based on a specific business event (represented by the offset).
And last but certainly not least: we’re bringing schema ID validation to Redpanda so developers can easily validate messages against known data types registered in the Redpanda schema registry. Schema validation uses policies that define exactly where to expect certain data types within messages sent to topics. This means you get value out of real-time data more quickly with less manual filtering work, and ensures that only valid data reaches downstream consumers.
Plus, Redpanda schema validation supports the Confluent Serdes wire format so it’s now super simple to migrate existing applications that use Confluent Serdes libraries and validation over to Redpanda. No code changes required.
Other improvements to Redpanda’s Kafka ecosystem compatibility include a richer built-in Protobuf type system and enhanced support for Avro formats.
Phew, talk about a well-rounded release. We trust that all our work over the last number of months will help accelerate your streaming data projects and ensure that Redpanda is your real-time engine of choice, regardless of workload type or size.
All of these summer updates are available today, so request a free trial of Redpanda Enterprise or Cloud, or grab the free Community Edition from our Redpanda GitHub repo.
By the way, did you know that Redpanda is proven to help you reduce your streaming data costs by up to 6x? If you have questions about how much we can reduce your cloud bill, join the Redpanda Community on Slack, or get in touch with one of our experts.
Subscribe to our VIP (very important panda) mailing list to pounce on the latest blogs, surprise announcements, and community events!
Opt out anytime.

