





Deploy agents you can trust with centralized AI governance
You can't scale what you can't trust. A governance layer fixes that.

The “secret” ingredient to building faster, safer, low-cost streaming data applications at scale








Data streaming is increasingly mission-critical for teams that need instant insights from real-time events and transactions. But streaming at scale also brings real challenges: retention pressure, reliability requirements, and cloud costs that can surprise you once throughput and availability enter the picture.
Redpanda is a streaming data platform that offers a different approach: a cloud-first storage model that takes advantage of the elasticity and economics of high-bandwidth object storage.
In this post, we'll walk through how Redpanda's cloud-first storage model reduces the total cost of ownership (TCO) for streaming data by simplifying deployment, keeping performance predictable, and enabling new ways to use the same streams—without bolting on more infrastructure.
Redpanda's data storage architecture uses a cloud-first model that decouples compute from storage. Unlike legacy streaming systems that force you to provision expensive compute nodes just to store historical data, Redpanda clusters keep recent data on fast local disks while using cost-efficient cloud object stores (like S3) to scale retention well beyond the physical capacity of the brokers.
This model relies on Tiered Storage to transparently move and manage data across local drives and cloud storage buckets. You get low-latency access for hot data, plus practical "keep it as long as you need" retention for historical reads and downstream analysis.

The architecture is built on three core pillars:
With the Redpanda v22.3 release, the cloud became the default storage tier for Redpanda clusters, and we continue to invest in making cloud object storage a first-class tier for long retention and portability, while allowing existing Kafka applications to run unchanged as the storage layer works behind the scenes.
Redpanda's cloud-first approach helps organizations tap into the capacity, availability, and cost profile of cloud object stores. The result is a cleaner architecture: fewer "retention-driven" clusters, simpler operations, and lower costs, without sacrificing real-time performance where it matters.
Let's dig into the benefits.
Redpanda's Tiered Storage capability uses two storage tiers:
Tiered Storage lets Redpanda scale past the finite capacity of any given cluster. In traditional Apache Kafka deployments, increasing retention often means adding more brokers just for their disk space—a costly inefficiency known as "retention-driven scaling." Because object storage is typically much cheaper than SSD/NVMe-based instances, Redpanda lets you reduce cloud costs and avoid the operational burden of running a large broker fleet sized mostly for retention.
Built-in Tiered Storage asynchronously offloads older log segments from local storage to S3-compatible object stores, such as Amazon S3, GCS, and Azure Blob Storage. When clients need older data, Redpanda fetches it and serves it transparently. In practice, it's a straightforward way to pair fast local access with long-term retention.
This model also enables long-lived historical datasets in the cloud, unlocking AI/ML workflows. For example, you might use real-time streams for fraud detection while using historical data for offline model training. Redpanda lets consumers access both through the same Kafka-compatible interface, so you don't have to treat streaming as "just a transport layer" that constantly copies data elsewhere.
In our Redpanda vs. Kafka TCO benchmark report, we ran Redpanda Enterprise, Commercial Kafka, Redpanda Community Edition, and Kafka without Tiered Storage. For each workload, we evaluated the potential infrastructure cost at one, two, and three days' worth of retention.
The table below summarizes the results across all of the workloads.

The cost savings of an Enterprise subscription can range from $70K up to $1.2M or higher for bigger workloads or retention requirements.
[CTA_MODULE]
Tiered Storage is a big lever on storage cost. But for high-throughput workloads in the public cloud, networking can become just as painful—especially when data replicates across availability zones (AZs) for high availability.
Cloud Topics (currently in beta for Redpanda Enterprise) take a different approach. Instead of retaining data on broker disks and then offloading older segments, Cloud Topics persist topic data directly to cloud object storage.
While the Kafka community is still discussing "diskless topics" and follower-fetching-style proposals to address these costs, Redpanda Cloud Topics deliver this architecture today. This offers distinct advantages for cost-conscious teams:
Remote Read Replicas act like a "CDN" for your streaming data. They let you project data globally without standing up expensive, always-on replication infrastructure everywhere you have consumers.
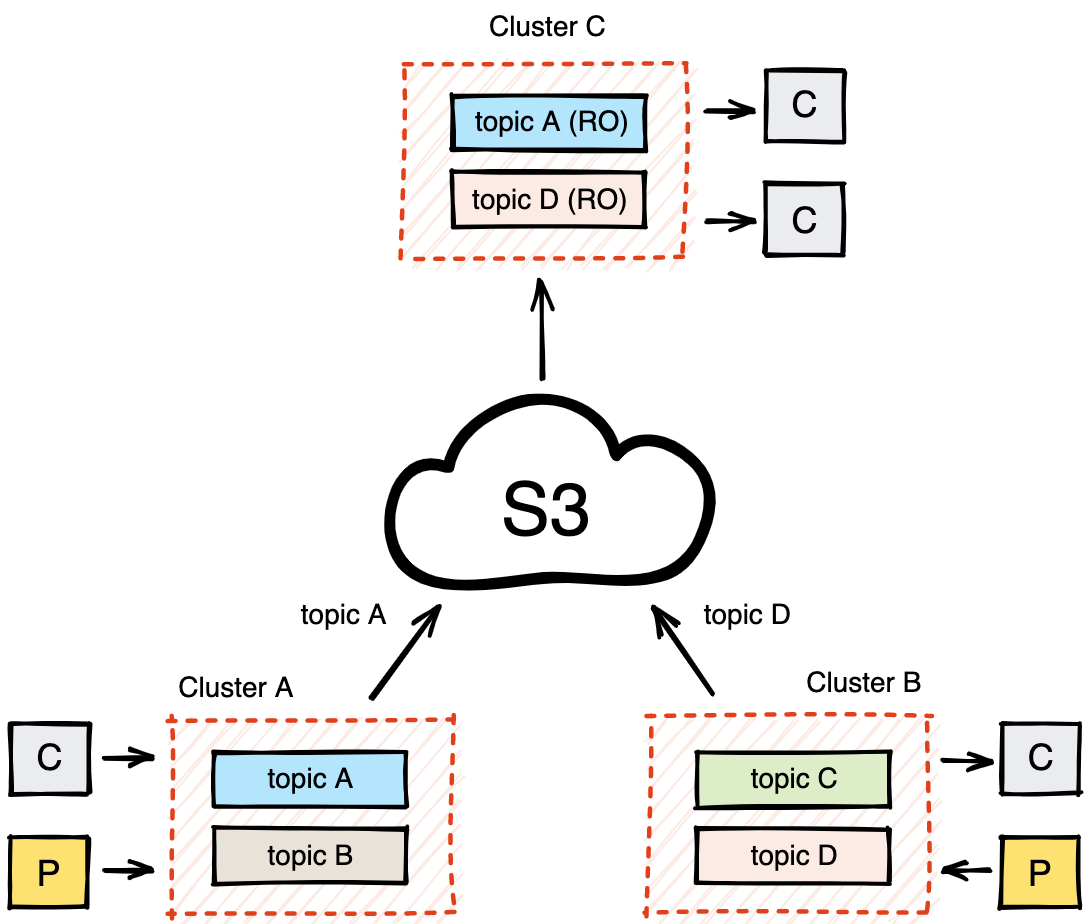
Redpanda's storage engine makes topic data portable and self-contained. Because the remote store includes both log segments and manifests describing topic/partition state, a remote cluster can "rehydrate" a read-only view of a topic simply by reading from the bucket. This eliminates the need for external replication tools like MirrorMaker 2 for common read-scaling and distribution patterns, which often introduce operational complexity and offset translation headaches.
This capability maps directly to high-level business goals:
Tiered Storage makes long retention practical. The next question is what you can do with that retained data without building and operating a second pipeline.
Iceberg Topics let you persist streaming topic data to cloud object storage in the Apache Iceberg™ table format. This provides a structured table view for SQL analytics engines like Snowflake, Databricks, Spark, and DuckDB.
Iceberg Topics are generally available as of Redpanda 25.1, and can be used in Redpanda Enterprise (self-managed) and Redpanda Cloud BYOC deployments across AWS, Azure, and GCP.
From a TCO perspective, this reduces the need to babysit brittle ETL jobs or manage a separate Kafka Connect cluster just to get SQL access. You cut duplicated data movement and operational overhead while keeping streaming and analytical views aligned to the same underlying data.
Disaster recovery (DR) isn't one-size-fits-all. Redpanda supports multiple strategies so you can match Recovery Time Objectives (RTO) and Recovery Point Objectives (RPO) to the needs of the business.
Manual data management tends to turn into a long-term tax: tickets, firefights, and time spent tuning systems that should manage themselves. Redpanda's cloud-first storage model automates core tasks so teams spend less time on operations and more time building.
Today, the Unified Retention Controls feature lets you enforce retention policies for both local data and data in cloud storage buckets. That means one set of lifecycle rules across the whole system.
Additionally, Redpanda's Continuous Data Balancing constantly monitors cluster nodes, rack availability, and disk usage. It automatically balances partitions so locally stored data stays evenly distributed. Together, these features reduce the need for manual intervention—lowering operational costs over time.
The total cost of ownership (TCO) is a financial metric that measures the total costs associated with acquiring, operating, and maintaining a streaming data storage solution over its entire lifespan. TCO includes infrastructure, personnel, training, and subscription costs.
When we talk about how cloud-first storage reduces TCO, we focus on three cost factors:
Hopefully now you're familiar with how Redpanda's cloud-first approach addresses these factors through cost-effective retention, Remote Read Replicas as a global CDN, Cloud Topics to reduce networking fees, Iceberg Topics to minimize ETL, flexible DR options, and automated data management.
The fastest way to blow a streaming budget isn't by overprovisioning disks, it's treating streaming like a short-lived transport layer that continuously feeds other systems and pipelines. Cloud-first storage changes that model. With Tiered Storage, Cloud Topics, Remote Read Replicas, Iceberg Topics, and Shadowing, you can choose where data lives, how long you keep it, and how you recover when things go wrong.
In a nutshell: Redpanda's storage model reduces TCO across data storage, data transfer, and data management, while also improving resource efficiency and resilience.
Interested in trying Redpanda for yourself? Take Redpanda for a spin! If you get stuck, have a question, or want to compare notes with other streaming practitioners, join our Redpanda Community on Slack.
You can't scale what you can't trust. A governance layer fixes that.

What is it, why enterprises need it, and how to evaluate one

Enterprise agents need governance infrastructure, not just better models
Subscribe to our VIP (very important panda) mailing list to pounce on the latest blogs, surprise announcements, and community events!
Opt out anytime.