




Bridge Queries in Redpanda SQL
Have your real-time cake and eat your analytics too
Learn the data streaming strategies to lay a solid foundation for AI









Welcome to the second post in our series about data streaming for AI in the financial services industry (FSI). In part one, I covered the primary obstacles holding back FSIs hoping to adopt a future-proof data streaming architecture.
In this second post, I will focus on how you can create order from the (data pipeline) chaos and set robust foundations for AI.
As systems become less centralized with microservices, domain-driven design (DDD), and the move to a cloud and container-first world—the way we process and provide data should also be decentralized and distributed to fit with the movement.
However, It’s unrealistic to completely revamp how data is distributed all at once. You’ll want to start by focusing on a specific domain, limit the scope, and be prepared for the challenge of shifting from a centralized data approach to a distributed one.
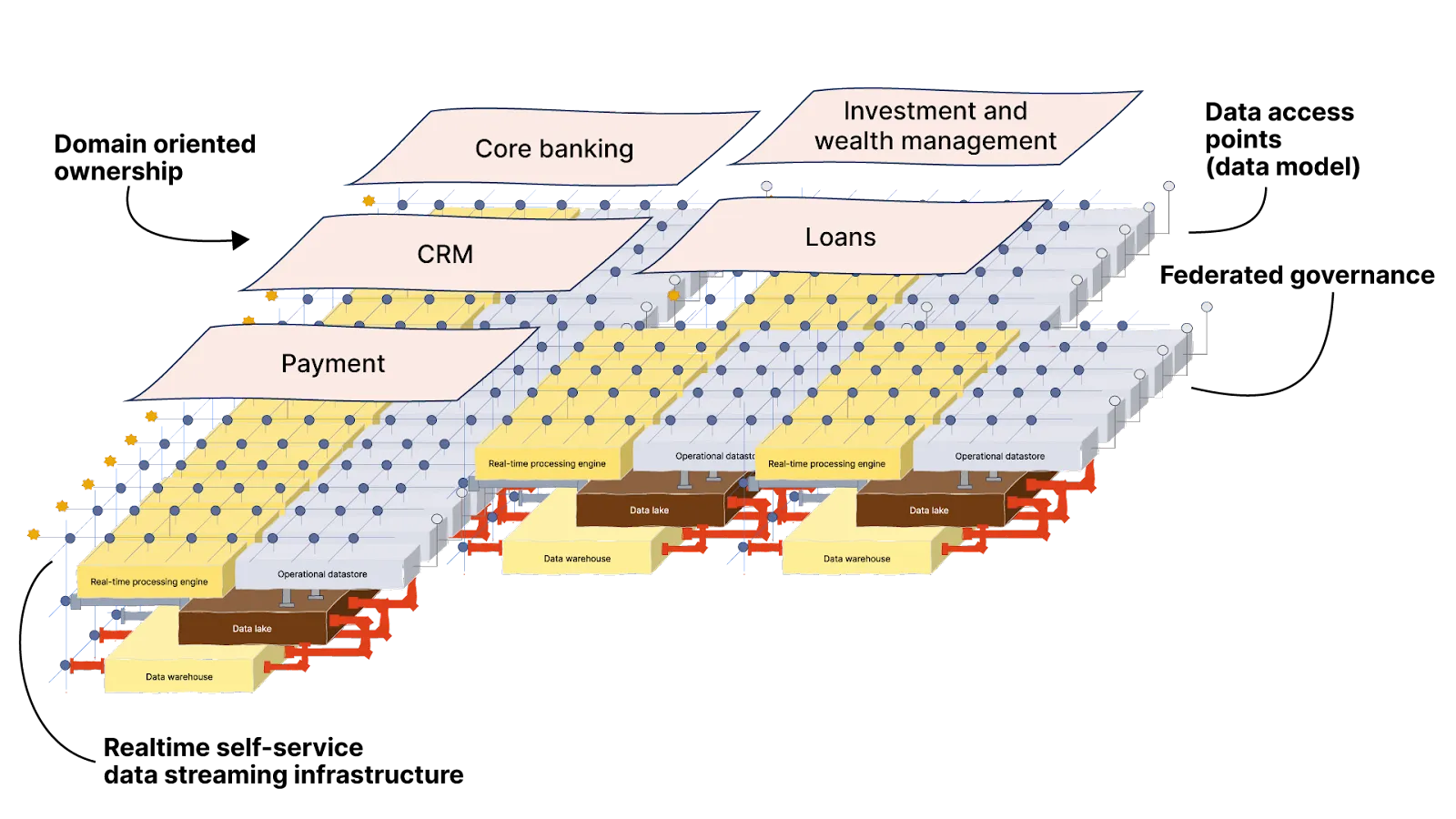
There are many moving parts involved—like the cultural shift, consent agreements, and regulation—but here I want to focus on the technical aspects for practitioners and architects. So I won’t go into much detail on those aspects, but for the curious, here’s a quick glance at the entire process.
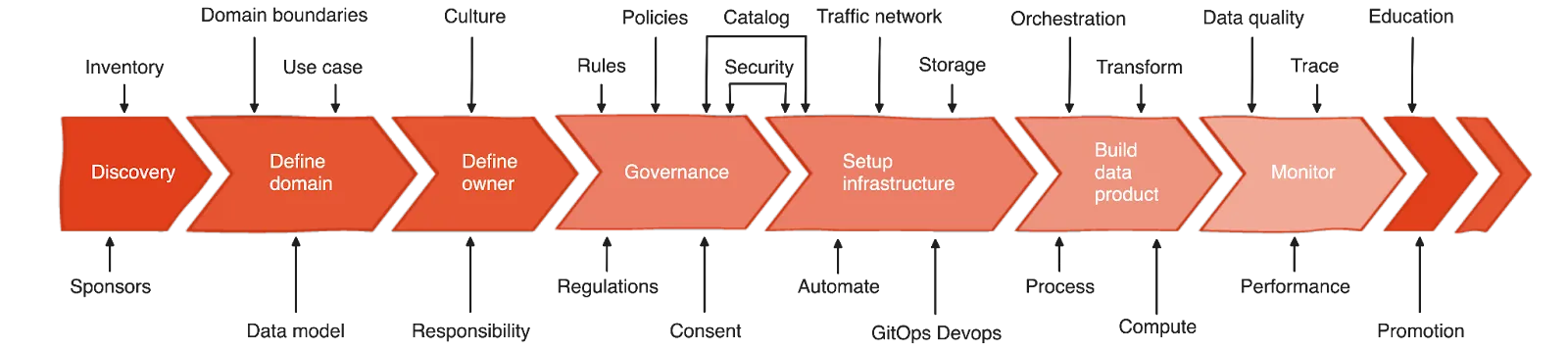
I will, however, highlight the subject of governance. The following points need to be discussed and meticulously planned out since they directly contribute to the cleanliness of the data and make it less prone to error during processing:
Think of it this way: the human body constantly processes a vast amount of information and data every second— movements, sensations, thought processes, and the regulation of internal organs. Similar to how the complex nervous system transports these signals to coordinate and control various bodily functions, building a well-designed data system can be likened to constructing a sophisticated network for data communication and processing.
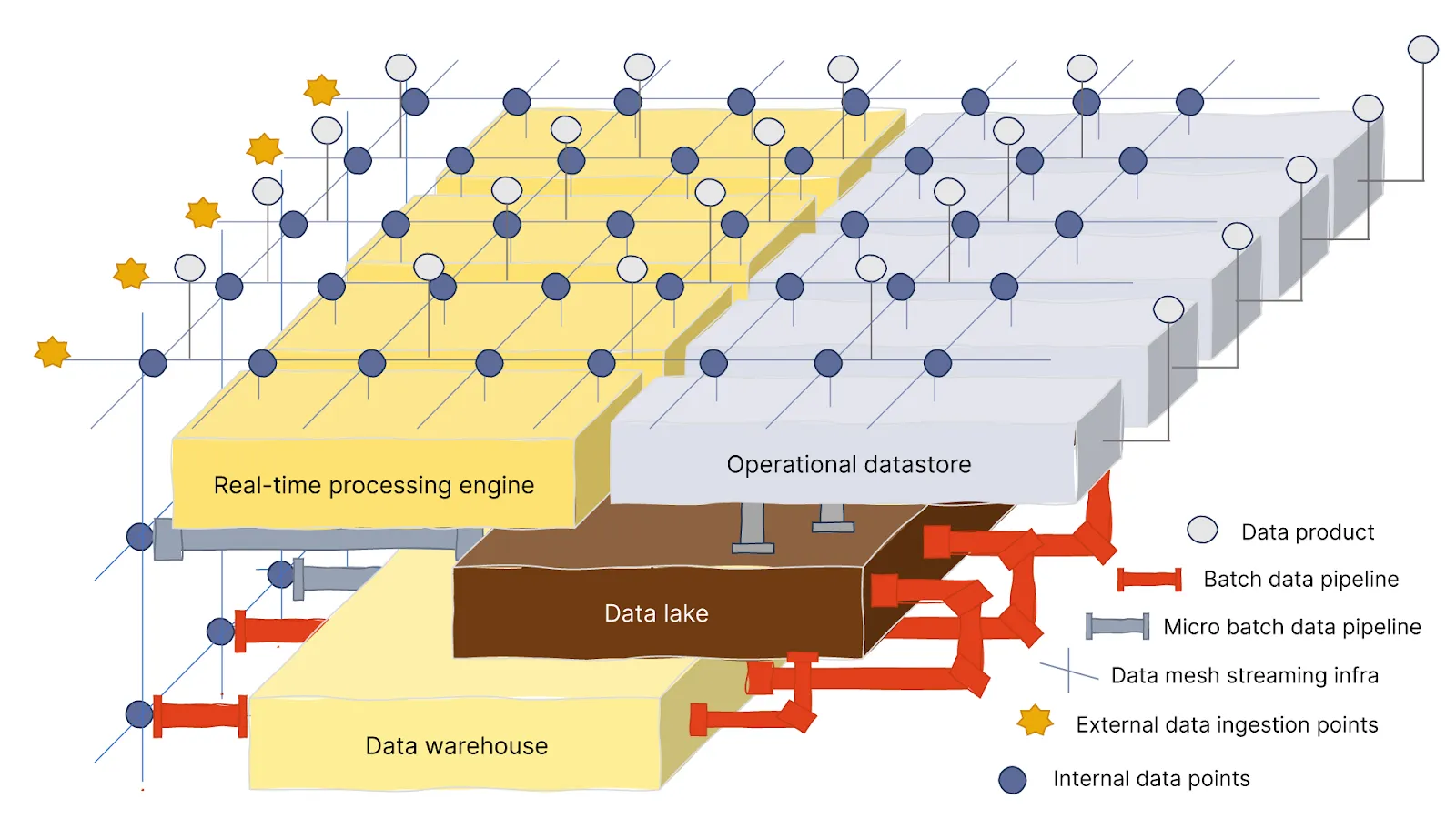
In the same way that nerves are used to transmit electrical signals and information throughout the body, we’d use a streaming data platform to build the network that pumps data around. When a system needs to send or get data, it can rely on the network to quickly deliver the piece of information to the right place.
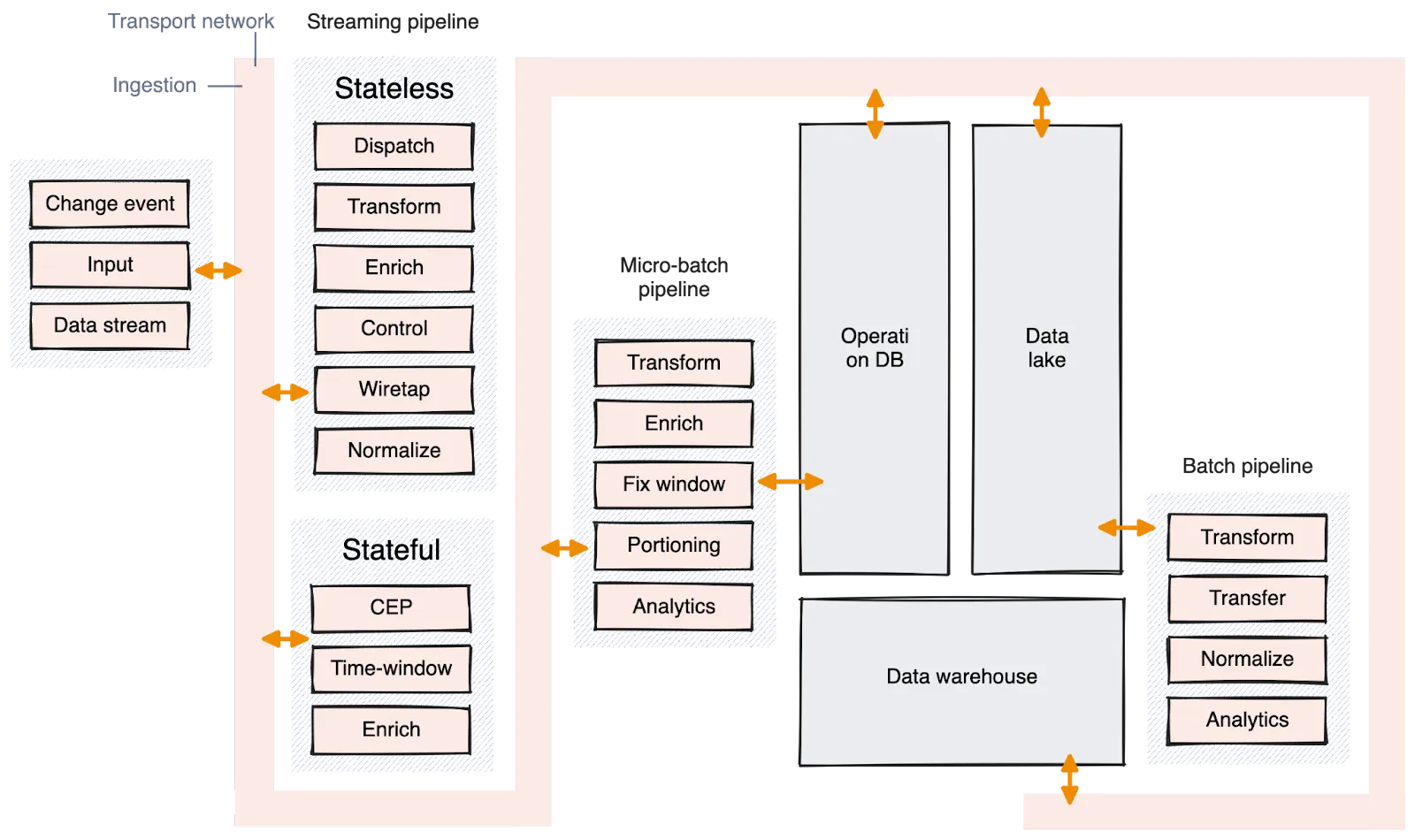
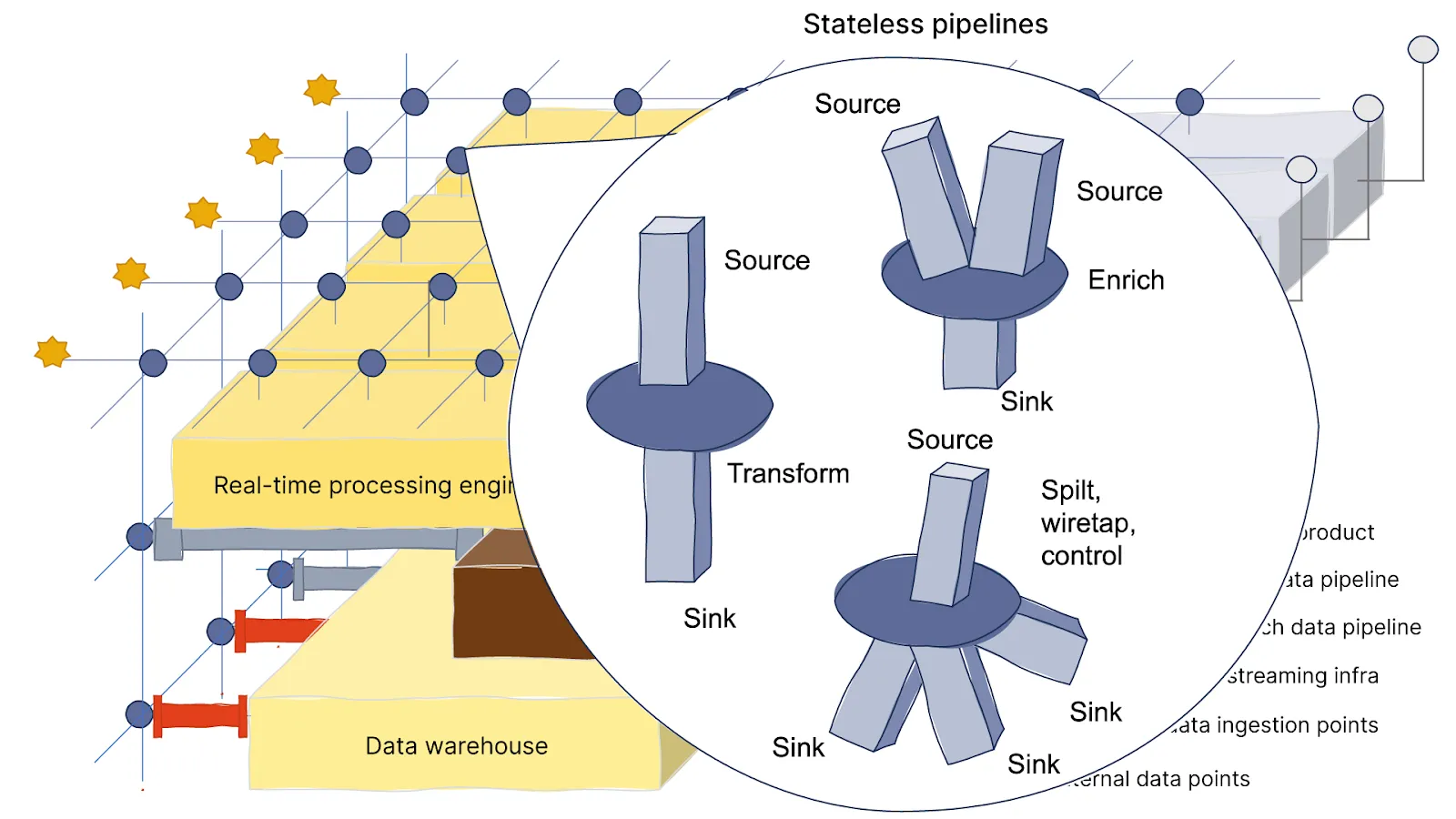
The network distributes data throughout the system. This data is mostly used by the streaming pipeline for quick data transformations, data enrichment, and routing data to the right places (i.e. stateless pipelines). Some stateful pipelines, which need to aggregate time-bound or context-bound data, also use the network.
Furthermore, data is streamed to micro-batch pipelines when real-time data is needed to trigger actions or for data enrichment. However, it's not typically used by batch pipelines. Instead, the data is sent and stored in data lakes, operational databases, or sometimes data warehouses that can later be used by batch processes.
Since you'll be relying on this streaming network to handle real-time data for the entire system, it needs to efficiently handle a large amount of load. You should check the throughput numbers and ensure enough brokers are available based on the number of systems or pipelines connected to it.
It’s case by case, but generally, the rule of thumb is to minimize the number of batch pipelines and, if possible, replace micro-batch pipelines with real-time processing.
It's advisable to maintain a copy of the raw data in a data lake but process incoming data as it arrives. The pipeline distribution should lean towards looking like the diagram below, quicker, smaller stateless pipelines that efficiently pre-process and dispatch data to their next destinations. These pipelines offer greater agility, easier scalability, and are well-suited for serverless computation, potentially reducing costs, especially for teams building real-time dataflows for an AI agent platform.
Stateful pipelines are best suited for stream processing engines or frameworks, which help manage and share state complexity. For time-window-based calculations, leveraging natural language frameworks can be more effective.
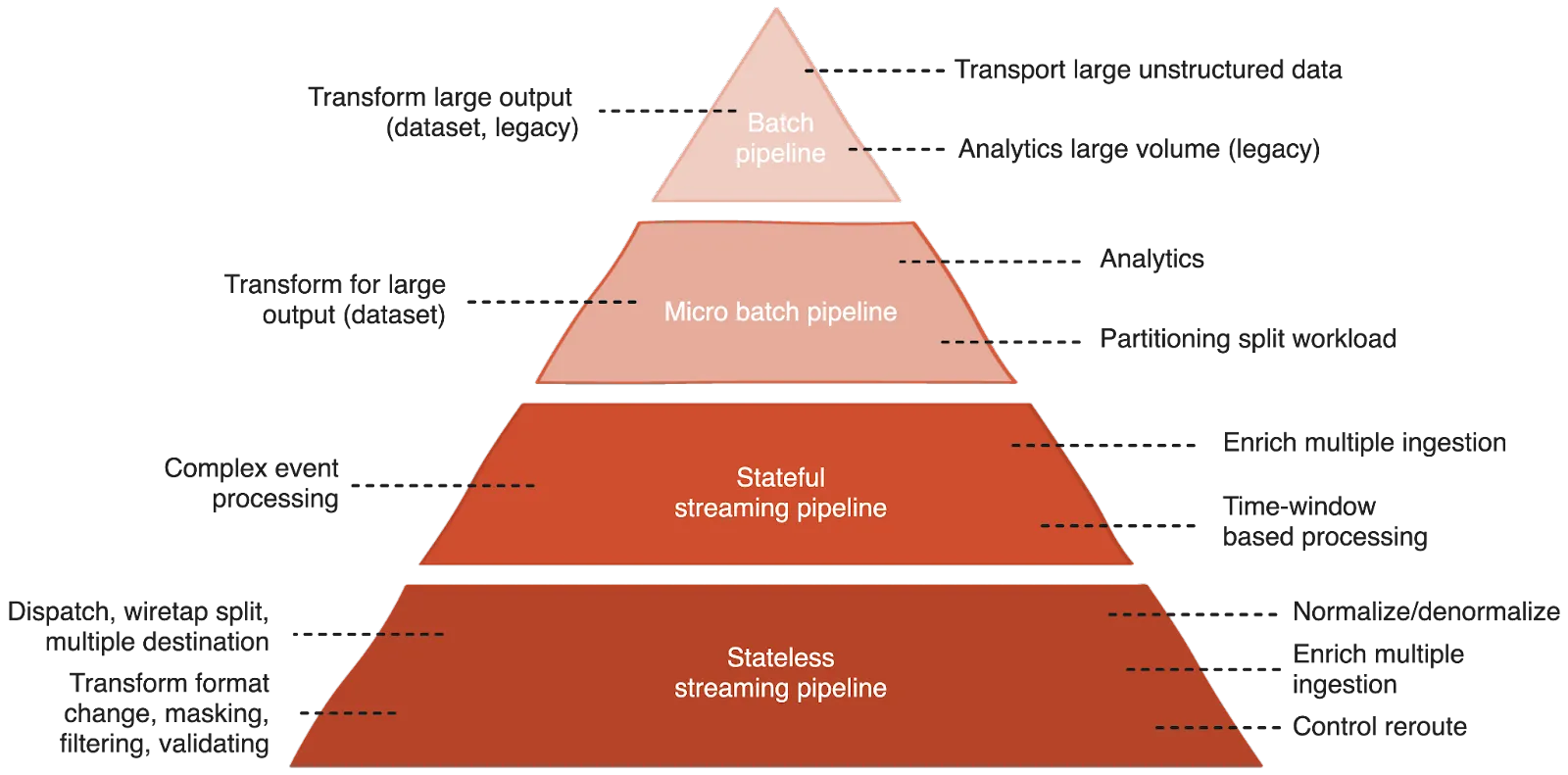
The batch pipeline, in my opinion, is not going away. The system still needs it for business intelligence applications and data visualization. These reports often involve processing significant historical data. While iterative processing could be considered, it’s likely that with advancements in processing power and machine learning algorithms, there will always be a need to rebuild the data model from scratch.
This approach will ensure the agility of the data layer and help solve the challenges we covered in our previous post.
[CTA_MODULE]
When it comes to generating datasets for training machine learning models, streaming data is better suited for continuous training and testing. However, it can be challenging to prepare datasets for ML model training from different types of data stores that were introduced throughout the years. Implementing a proven data strategy can streamline your troublesome data pipelines for real-time data ingestion, efficient processing, and seamless integration of disparate systems.
Next, I’ll walk you through a use case where we implement these data strategies to leverage generative AI for an insurance claim. We’ll also use Redpanda as our streaming data platform—a simpler, more performant, and cost-effective Kafka alternative. This use case will be nicely packaged in a free, downloadable report (coming soon!), so make sure you subscribe to our newsletter to be the first to know.
In the meantime, if you have questions about this topic or need support getting started with Redpanda for your own AI use case, you can chat with me or our team in the Redpanda Community on Slack. To learn how Redpanda is making streaming data simple, cost-efficient, and reliable for companies around the world, check out our customer stories and browse the Redpanda Blog for tutorials.
Subscribe to our VIP (very important panda) mailing list to pounce on the latest blogs, surprise announcements, and community events!
Opt out anytime.

