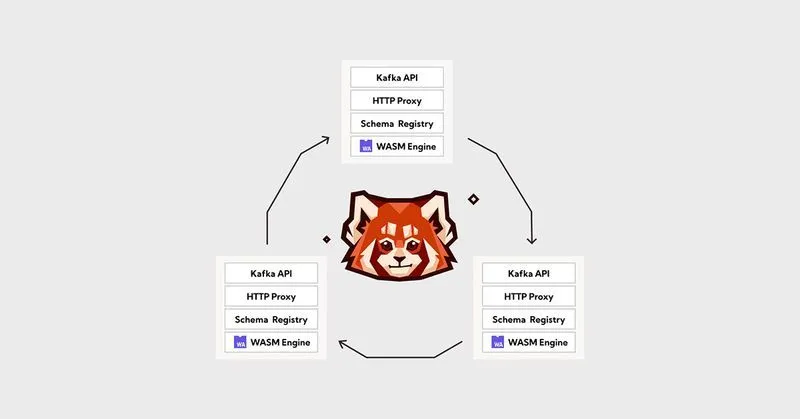
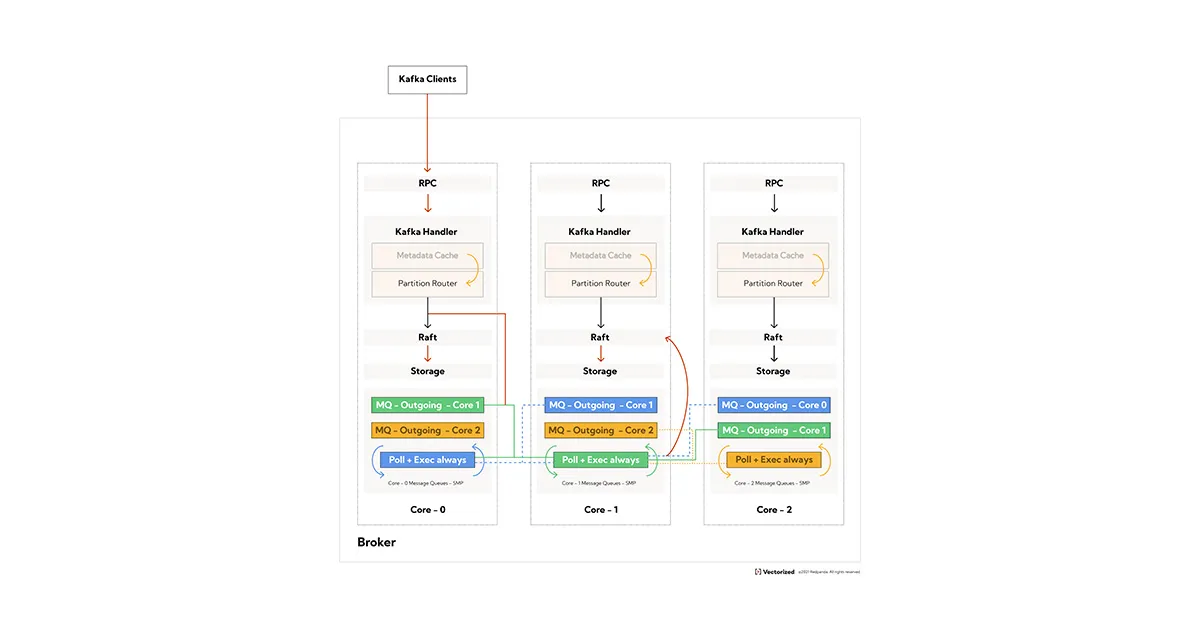
Redpanda Cloud brings the fastest Kafka® API to the cloud
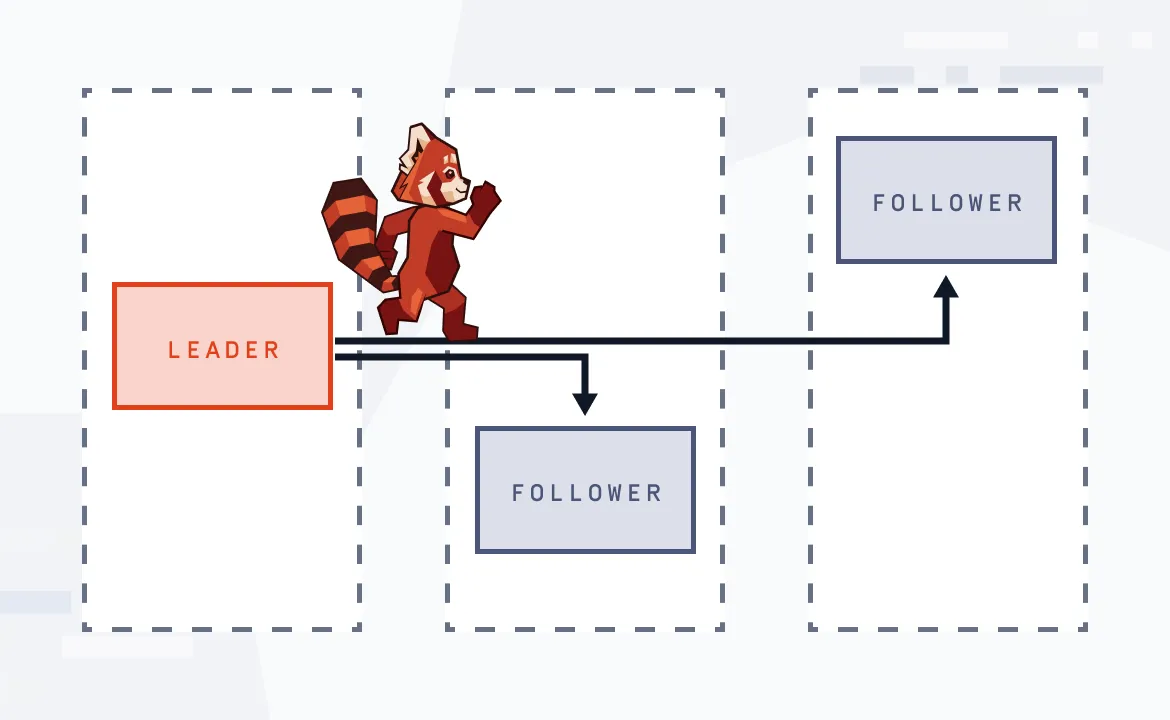
Redpanda Cloud brings the fastest Kafka API in the industry to developers, complete with a privacy-preserving architecture, integrated Redpanda Console, managed connectors, VPC peering, and SOC 2 compliance.
























































.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)

.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
























































.png)