





What is an Agentic Data Plane?
What is it, why enterprises need it, and how to evaluate one

A deep dive into the challenges blocking the FSI from successfully adopting AI—and how to solve them








In the ever-evolving landscape of the Financial Services Industry (FSI), organizations face a multitude of challenges that hinder their journey toward AI-driven transformation. Legacy systems, stringent regulations, data silos, and a lack of agility have created a chaotic environment in need of a more effective way to use and share data across the organization.
In this two-part series, I delve into my own personal observations, break open the prevailing issues within the FSI, and closely inspect the factors holding back progress. I’ll also highlight the need to integrate legacy systems, navigate strict regulatory landscapes, and break down data silos that impede agility and hinder data-driven decision-making.
Last but not least, I’ll introduce a proven data strategy approach in which adopting data streaming technologies will help organizations overhaul their data pipelines—enabling real-time data ingestion, efficient processing, and seamless integration of disparate systems. If you're interested in a practical use case that showcases everything in action, keep an eye out for our upcoming report.
But before diving into the solution, let’s start by understanding the problem.
Stepping into larger financial institutions often reveals a fascinating insight: a two-decade technology progression unfolding before my eyes. The core business continues to rely on mainframe systems running COBOL, while a secondary layer of services acts as the gateway to access the core, and extension of services offerings that can’t be done in the core system.
Data is heavily batched and undergoes nightly ETL processes to facilitate transfer between these layers. Real-time data access poses challenges, demanding multiple attempts and queries through the gateway for even a simple status update.
Data warehouses are established, serving as data dumping grounds through ETL, where nearly half of the data remains unused. Business Intelligence (BI) tools extract, transform, and analyze the data to provide valuable insights for business decisions and product design. Batch and distributed processing prevail due to the sheer volume of data to be handled, resulting in data silos and delayed reflection of changing trends.
In recent years, more agile approaches have emerged, with a data shift towards binary, key-value formats for better scalability on the cloud. However, due to the architectural complexity, data transfers between services have multiplied, leading to challenges in maintaining data integrity. Plus, these innovations primarily cater to new projects, leaving developers and internal users to navigate through multiple hoops within the system to accomplish tasks.
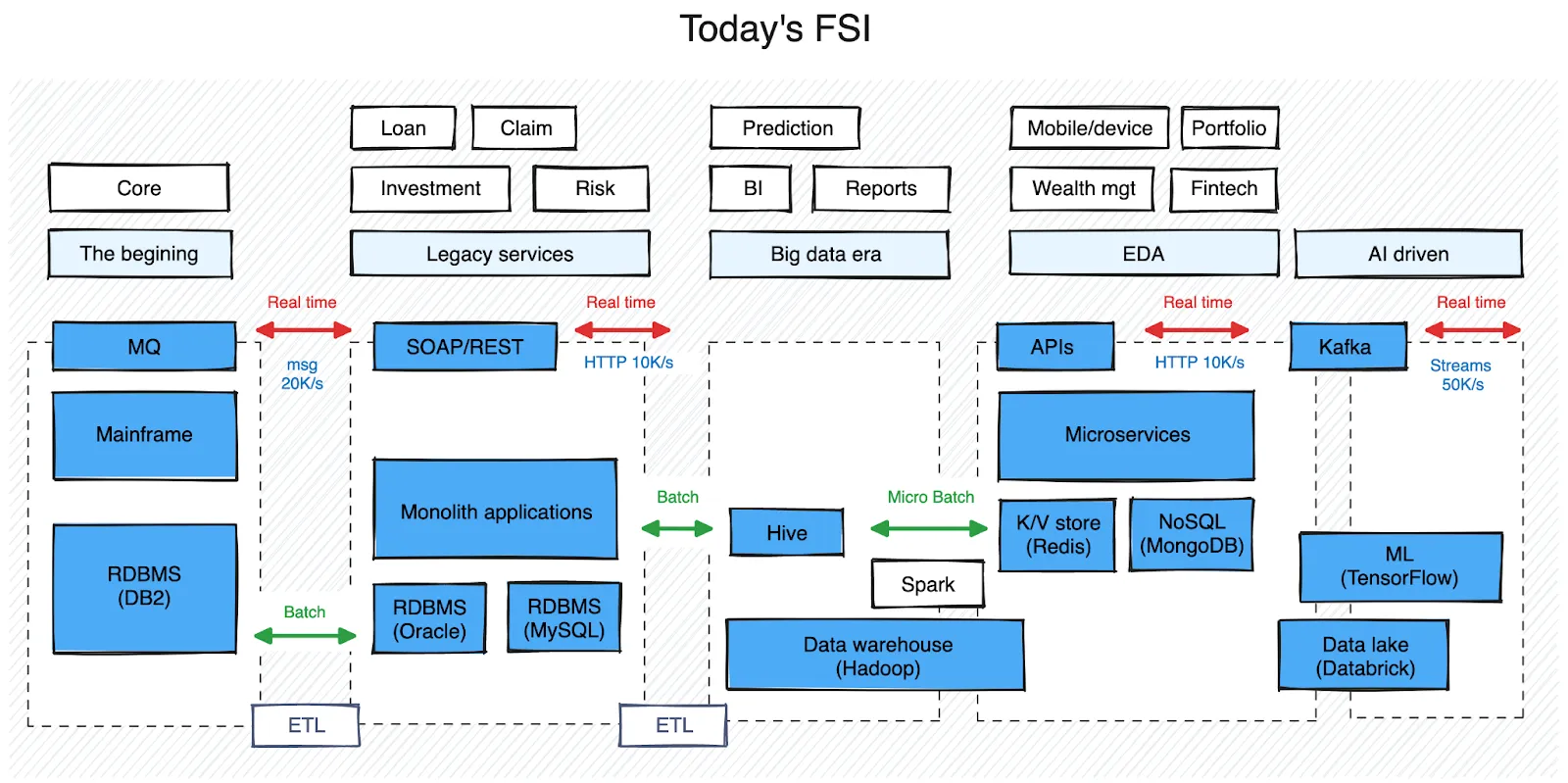
Companies also find themselves paying the price for slow innovation and encounter high costs when implementing new changes. This is particularly true when it comes to AI-driven initiatives that demand a significant amount of data and swift action, especially for organizations hoping to power an AI agent platform at scale. Consequently, several challenges bubble to the surface and get in the way of progress, making it increasingly difficult for FSIs to adapt and prepare for the future.
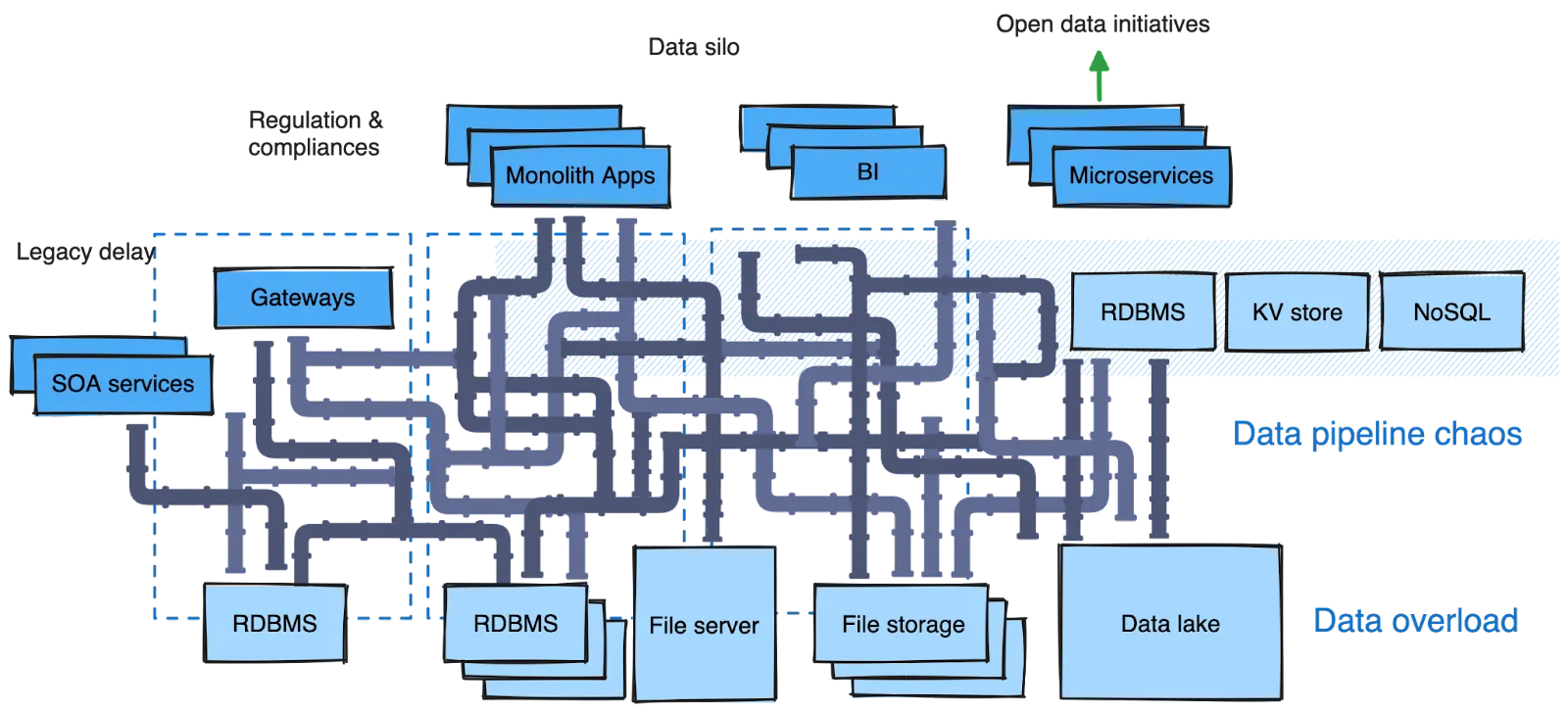
Here’s a breakdown of these challenges and the ideal state for FSIs.
Clearly, there’s a lot stacked up against FSIs attempting to leap into the world of AI. Now let’s zoom in on the different data pipelines organizations are using to move their data from point A to B, and the challenges many teams are facing with them.
There are all sorts of ways that move data around. To keep things simple, I’ll distill the most common pipelines today into three categories:
These are typically used when processing large volumes of data in scheduled “chunks” at a time—often in overnight processing, periodic data updates, or batch reporting. Batch pipelines are well-suited for scenarios where immediate data processing isn't crucial and the output is usually a report, like for investment profiles and insurance claims.
The main setbacks include processing delays, potentially outdated results, scalability complexities, managing task sequences, resource allocation issues, and limitations in providing real-time data insights. I’ve witnessed an insurance customer running out of windows at night to run batches due to the sheer volume of data that needed processing (updating premiums, investment details, documents, agents’ commissions, etc.).
Parallel processing or map-reduce are a few techniques to shorten the time, but they also introduce complexities, as parallel both require the developer to understand the distribution of data, dependency of data, and be able to maneuver between map and reduce functions.
Micro batch pipelines are a variation of batch pipelines where data is processed in smaller, more frequent batches at regular intervals for lower latency and fresher results. They’re commonly used for financial trading insights, clickstream analysis, recommendation systems, underwriting, and customer churn predictions.
Challenges with micro-batch pipelines include managing the trade-off between processing frequency and resource usage, handling potential data inconsistencies across micro-batches, and addressing the overhead of initiating frequent processing jobs while still maintaining efficiency and reliability.
These pipelines process data as soon as it flows in. They offer minimal latency and are essential for applications requiring instant reactions, such as real-time analytics, transaction fraud detection, monitoring critical systems, interactive user experiences, continuous model training, and real-time predictions.
However, real-time pipelines face challenges like handling high throughputs, maintaining consistently low latency, ensuring data correctness and consistency, managing resource scalability to accommodate varying workloads, and dealing with potential data integration complexities—all of which require robust architectural designs and careful implementation to deliver accurate and timely results.
To summarize, here’s the important information about all three pipelines in one table.
As a side note, some may categorize pipelines as either ETL or ELT.
Depending on the destination of the data, if it’s going to a data lake, you’ll see most pipelines doing ELT. Whereas with a data source, like a data warehouse or database, since it requires data to be stored in a more structured manner, you will see more ETL. In my opinion, all three pipelines should be using both techniques to convert data into the desired state.
Pipelines are scattered across departments and IT teams implement them with various technologies and platforms. From my own experience working with on-site data engineers, here are some common challenges working with data pipelines:
During the process of redesigning the data framework for AI, both predictive and generative, I’ll address the primary pain points for data engineers and also help solve some of the biggest challenges plaguing the FSI today.
Looking through a data lens, the AI-driven world can be dissected into two primary categories: inference and machine learning. These domains differ in their data requirements and usage.
Building a generative AI model is a major undertaking. For FSI, it makes sense to reuse an existing model (foundation model) with some fine-tuning in specific areas to fit your use case. The “fine-tuning” will require you to provide a high-quality, high-volume dataset. The old saying still holds true: garbage in, garbage out. If the data isn’t reliable, to begin with, you’ll inevitably end up with unreliable AI.
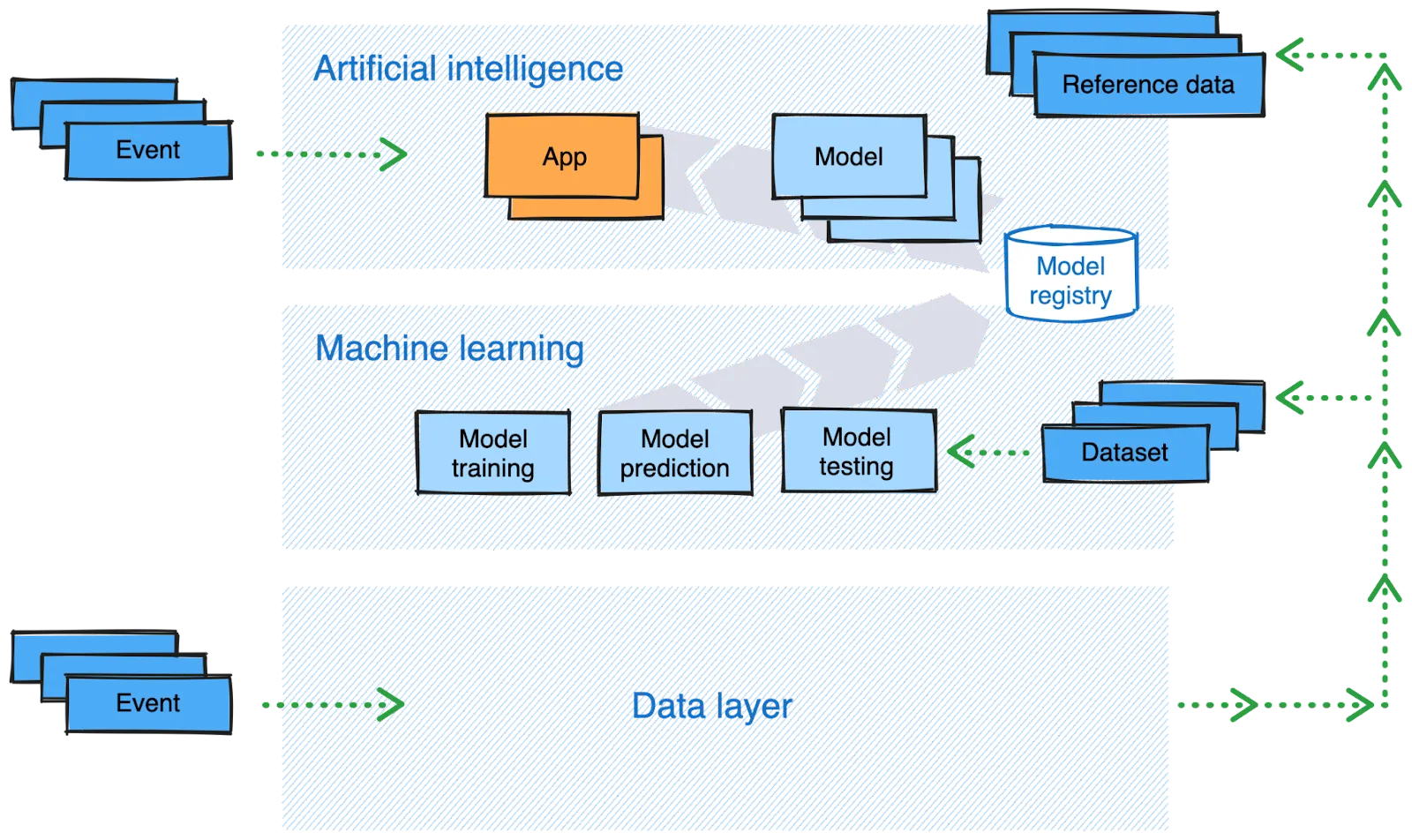
In my opinion, to prepare for the best AI outcome possible, it’s crucial to set up the following foundations:
Data infrastructure: You need a robust, low latency, high throughput framework to transfer and store vast volumes of financial data for efficient data ingestion, storage, processing, and retrieval. It should support distributed and cloud computing, and prioritize network latency, storage costs, and data safety.
Data quality: To provide better data for determining the model, it’s best to go through data cleansing, normalization, de-duplication, and validation processes to remove inconsistencies, errors, and redundancies.
Now, if I were to say that there’s a simple solution, I would either be an exceptional genius capable of solving world crises or blatantly lying. However, given the complexity we already have, it’s best to focus on generating the datasets required for ML and streamline the data needed for the inference phase to make decisions. Then, you can gradually address the issues caused by the current data being overly disorganized. Taking one domain at a time, solving business users’ problems first, and not being overly ambitious is the fastest path to success.
But we’ll leave that for the next post.
Implementing a data strategy in the financial services industry can be intricate due to factors such as legacy systems and the consolidation of other businesses. Introducing AI into this mix can pose performance challenges, and some businesses might struggle to prepare data for machine learning applications.
In my next post, I’ll walk you through a proven data strategy approach to streamline your troublesome data pipelines for real-time data ingestion, efficient processing, and seamless integration of disparate systems.
In the meantime, if you have questions about this topic or need support getting started with Redpanda for your own AI use case, you can chat with me or our team in the Redpanda Community on Slack.
To learn how Redpanda is making streaming data simple, cost-efficient, and reliable for companies around the world, check out our customer stories and browse the Redpanda Blog for specific examples and tutorials. See you in part two!
What is it, why enterprises need it, and how to evaluate one

Enterprise agents need governance infrastructure, not just better models

What AI trends will shape analytics in the coming months?
Subscribe to our VIP (very important panda) mailing list to pounce on the latest blogs, surprise announcements, and community events!
Opt out anytime.