





Full CDC semantics land in the Iceberg output for Redpanda Connect
Your lakehouse mirrors the database, instantly.
Learn the differences between RabbitMQ and Redpanda, and when it makes sense to use Redpanda as a RabbitMQ alternative.








In Redpanda, data persistence is similar to a database in that it stores data for later use. When data is produced, it is written immediately to disk, bypassing the page cache. Once it is committed to the majority of brokers in the Raft group, the producer receives their acknowledgment. This makes Redpanda highly durable and ensures the integrity of data under chaotic and strenuous conditions.
The fundamental differences between RabbitMQ and Redpanda significantly drive architectural decisions when designing a decoupled, services-based architecture around a central publish-and-subscribe data platform. For instance, RabbitMQ's broker-side intelligence allows for fancy error handling like throttling retries and automatically routing to “dead letter queues” on the server side. On the other hand, Redpanda and Kafka achieve higher scalability by blunting the intelligence of the brokers and leaving the logic and processing to the clients, leading to increasingly decoupled architectures and true microservices.
RabbitMQ is an open-source messaging platform based on the AMQP protocol. It allows users to create applications that produce messages to a central queue, which are then consumed in a fairly tightly coupled manner. RabbitMQ is lightweight, fast, scalable, and resilient, handling high throughputs and message counts. It can prioritize and route messages, schedule delivery of messages at a later time, or delete messages after a set expiration period.
Redpanda is a streaming data platform that is a drop-in replacement for Apache Kafka®. Unlike RabbitMQ, Redpanda persists data by default and allows multiple consumers to consume and replay the same data simultaneously. Redpanda focuses on writing and reading data to and from log segments without losing any data. It is known for its scalability and resilience, but this comes with architectural trade-offs.
In messaging platforms like RabbitMQ, the system acts as a megabrain, orchestrating signals throughout a reactive central nervous system. This is referred to as smart brokers and dumb clients. On the other hand, streaming data platforms like Redpanda and Kafka use dumb brokers and smart clients. The brokers prioritize writing and reading data to and from log segments, while the consumers ask for the data in a simple fashion and make logical decisions about what to do with the message.
Comparing rabbits to red pandas isn’t really a fair and direct comparison. They’re both cute and friendly creatures that you may want to cuddle and befriend, but, when you analyze their behavior and genetic composition, they’re different animals.
If you’re a zoologist and stumbled across this article, you’ll be disappointed to learn we’re not actually talking about fuzzy animals. However, if you’re a systems architect or developer trying to determine whether to use Redpanda or RabbitMQ for your application, you’re in the right place.
RabbitMQ is an open-source messaging platform based on the AMQP protocol. Messaging platforms allow users to create applications that produce messages to a central queue from which those messages are subsequently consumed in a fairly tightly coupled manner.
The appeal of queue-oriented platforms like RabbitMQ is that they are lightweight and fast. Yet, unlike the traditional JMS-based messaging systems of old, they are scalable and resilient, handling higher throughputs and message counts.
An old messaging guru once imparted to me that messaging is akin to the RPM and speedometer gauges in a car. In this example, you only care about what the “atomic” value is at the present time, not what it was before that moment. You also want that value to be presented to you without you having to ask for it.

Likewise, when a message hits your platform, it gets routed to a queue, which is then pushed to a passively waiting client that will consume and do something with the message. Usually, the message plays a simple, specific role in a services-oriented application. One of the key tenets of messaging platforms is that, by default, once the downstream component consumes the message, it’s gone.
Redpanda is a streaming data platform that is a drop-in replacement for Apache Kafka®. Your existing applications will work with zero (or very little) modification, and for most architects working with modern platforms, that’s all you probably need to know.
For beginner streaming-data engineers, it may be helpful to explain Redpanda as conceptually similar to RabbitMQ: You have a horizontally scalable and resilient platform that applications centrally produce data to and consumers consume from. However, unlike messaging platforms like RabbitMQ, streaming data platforms persist the data by default. They can also have multiple consumers of the exact same data, at the same time, and the consumers can replay the data at will.
To revisit the car analogy, data streaming enables doing more sophisticated things like understanding how many miles until your fuel tank is empty. This is due to the ability to blend and analyze stateful/stored data with stateless streaming data. Redpanda and Kafka are also well-known for being more scalable and resilient than RabbitMQ, but that scalability comes with architectural trade-offs which we will discuss later in this article.
If you’re curious about the specific differences between Redpanda and other streaming data platforms like Kafka, you can view this benchmark or download our comprehensive guide here. For a more detailed comparison of Redpanda and RabbitMQ, specifically, just keep reading.
As you are now aware, there are fundamental differences between these two types of platforms. These differences significantly drive architectural decisions when designing a decoupled, services-based architecture around a central publish-and-subscribe data platform.
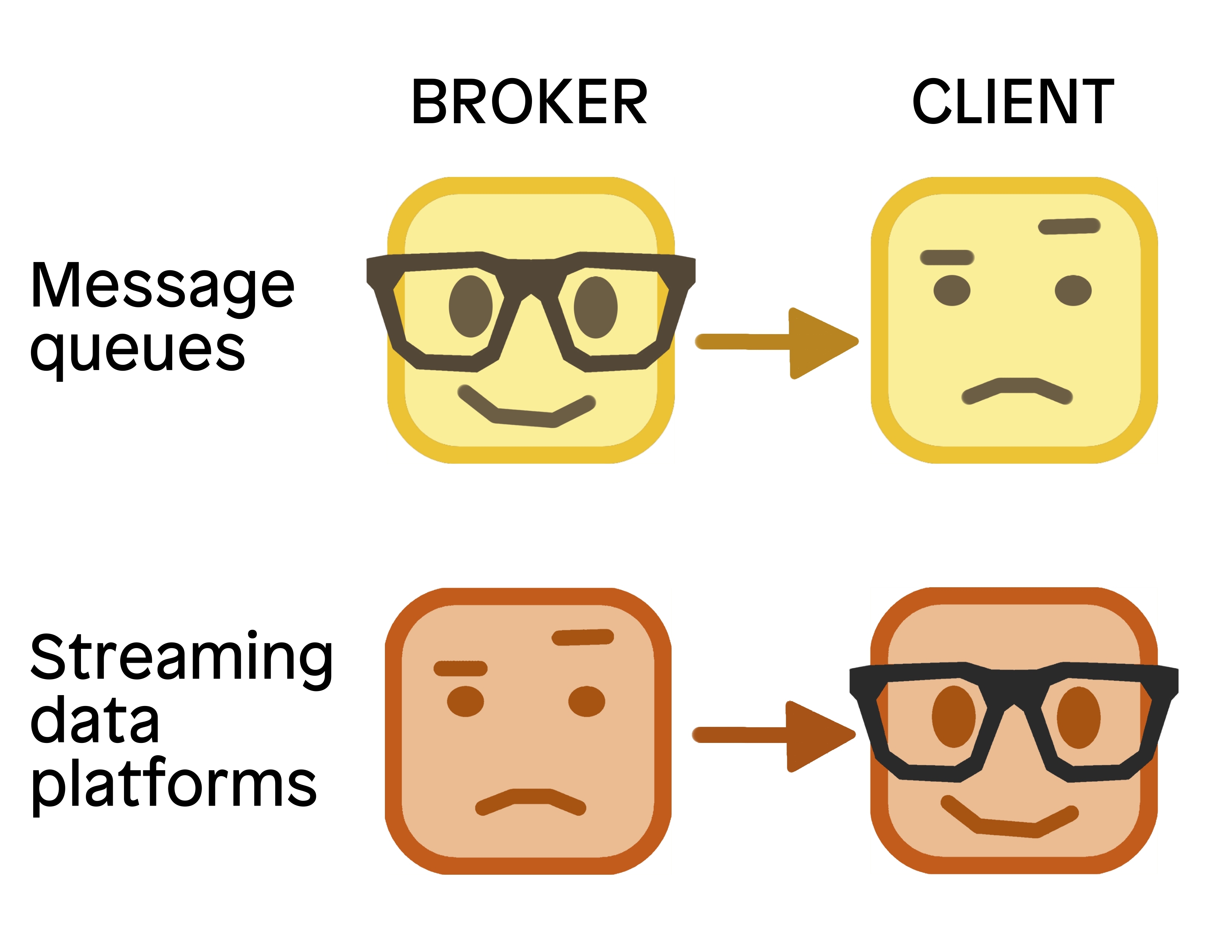
Probably the biggest difference between messaging platforms (RabbitMQ) and streaming data platforms (Redpanda/Kafka), is how the brokers and clients interact. A common way of referring to this in the industry is that messaging platforms tend to use smart brokers and dumb clients, while streaming data platforms use dumb brokers and smart clients.
What’s the difference? I’m glad you asked…
Think of a RabbitMQ-based system as a megabrain, orchestrating the signals throughout a reactive central nervous system. You can do all sorts of neat things like prioritize and route messages, and you have lots of options in terms of the exchange type you want to implement (direct, fan-out, topic, header-based). When messages are ready for consumers, the platform pushes them to the consumers that are connected to the queues, allowing the consumers to not have to do much work. The platform also lets you do neat things like schedule delivery of messages at a later time or delete messages after a set expiration period.
Another benefit of broker-side intelligence that you get with RabbitMQ is the ability to do fancy error handling like throttling retries, automatically routing to “dead letter queues” on the server side if there is an error in processing, and more. RabbitMQ also has a feature called Flow Control, which prevents a system from running out of resources due to runaway message growth.
On the flip side, Redpanda and Kafka achieve much higher scalability by blunting the intelligence of the brokers. Redpanda prioritizes writing and reading data to and from log segments. It doesn’t know why an event happened or have an opinion on what to do with the event; it just focuses on allowing the stream to flow freely and without losing any data. The consumers ask for the data in a simple fashion by seeking an offset in the append-only commit log (or starting from the latest position) and scanning forward.
Streaming data platforms are well-regarded for horizontal scalability, and the consumer group protocol plays a very important role in that. The consumer group protocol keeps track of the offset from which each of the consumers in a group last consumed. Consumers make the logical decisions of what to do with the message, such as routing back to other topics, sending them downstream, or replaying events as needed.
Similar to RabbitMQ, you can also implement dead letter queues (i.e. topics) in Redpanda or Kafka. Unlike in RabbitMQ, where this is handled on the broker side, Redpanda and Kafka do it on the consumer side in an error-handling pattern by producing failed messages to a specific topic and moving on.
Note: Leaving the logic and processing to the clients has led to increasingly decoupled architectures and sent application design into a realm of true microservices. Client-side intelligence has led to a rich, growing, and mature ecosystem of applications for stream processing, data integration, data sourcing, and real-time analytics.
Data persistence in streaming data platforms is similar to a database in the sense that it is storing your data for later (re-)use. In fact, there has been a long-running debate in the Kafka community on whether Kafka can be considered ACID compliant. Redpanda even invited Kyle Kingsbury to perform his "Jepsen" test on Redpanda. This is normally run against databases to determine their integrity under chaotic and strenuous conditions. (To see the results, you can read our Jepsen report post here.)
In Kafka, data is produced to the leader broker’s page cache (and eventually flushed to disk), and only then is it sent to the other replicas in line according to the configuration. Redpanda works similarly to Kafka, with two subtle but significant differences. First, the data is written immediately to disk, bypassing the page cache, and second, once it is committed to the majority of brokers in the Raft group, the producer receives their acknowledgment. The result is that Redpanda and Kafka persist data in a similar fashion, but Redpanda is far more durable than Kafka.
When you value data integrity, Redpanda has you covered.
In the messaging world, there is no persistence layer by default. When messages are consumed from the queue they are removed. This means that when your data has been picked up by the consumer and jettisoned off to do whatever it was meant to do, there is no longer a record of that data for you to replay later if your consumer runs into problems. That is the default mode, the core architecture of any messaging platform.
It’s possible to hook up both persistent and durable queues to RabbitMQ. That said, we hear complaints regularly from RabbitMQ operators that these features increase overhead on the brokers and, in turn, decrease performance.
On the producer side of RabbitMQ, acknowledgments (“confirms”) are typically sent for each message, which can lead to backpressure. That increases resource overhead and further degrades performance. You can confirm multiple messages by turning on transactions, but this also introduces a non-trivial performance hit and lowers overall throughput. All of this means that increasing durability in RabbitMQ means you have to accept many trade-offs at the broker level.

We briefly mentioned earlier that one of the key differences between RabbitMQ and Redpanda is that from a data consumption perspective, RabbitMQ is “push” based and Redpanda is “pull” based. This is a core difference in the design of the two systems.
In both Redpanda and Kafka, the consumer does a “pull” by polling the topic for new messages. You can control on the client side how quickly you receive the messages, how you replay the messages from earlier times, and if you have many consumers reading the messages at the same time. The architectural trade-off is that an architecture built with smart clients puts a lot of responsibility on the consumer code. It can take RabbitMQ-oriented architects and developers a little while to get used to this new mental model, but once they grok it, they can completely re-architect the access patterns within their client applications with great success.
In RabbitMQ, the clients are passive and react when messages get “pushed” to them, but since they must be prepared to handle potentially high bursts of data, the consumers need to be overprovisioned. Also, because the broker does its best to push out messages as quickly as possible, there’s no guarantee that the consumer will receive the messages in the same order as they were produced into the queue. This can be particularly problematic in “re-queueing” scenarios.
This style of push-based consumption can lead to low end-to-end latencies, even when scaled to tens of thousands of messages per second. This generally requires a “less is more” approach, which means that only minimal features go into the broker, and it performs much better when message sizes are small.
The client-centric, pull-based consumption in Redpanda and Kafka lends itself well to parallel consumption with horizontal scalability because the consumer latency can be controlled independently of the cluster.
Another area where the pull-based approach of Redpanda and Kafka excels is with the “fan out” architecture. Redpanda is built to serve the Consumer API of Kafka, and this allows the architect to create a decoupled and duplicative consumption pattern that does not impact the performance of the brokers when the clients consume data.
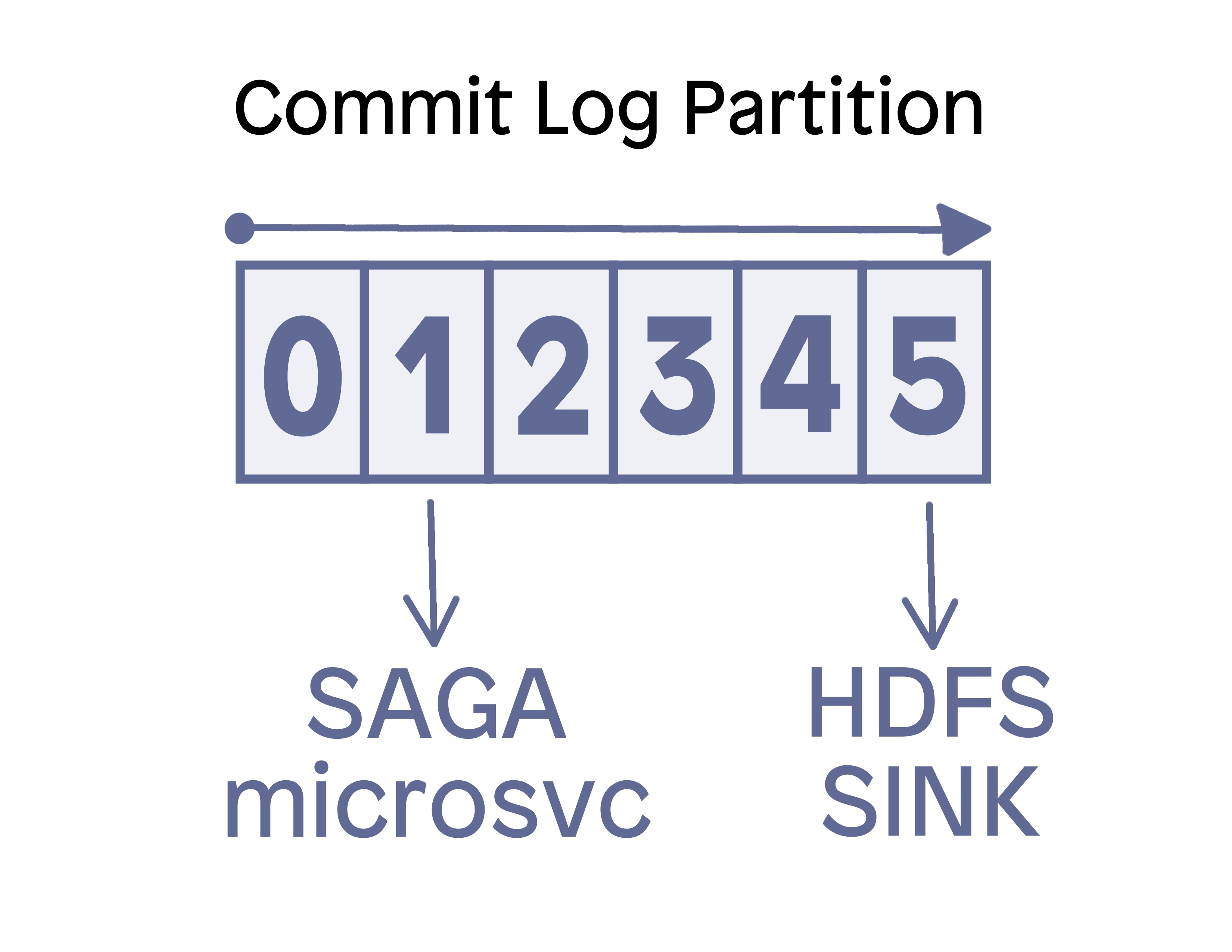
“Fan out'' is the term used to describe multiple different groups of consumers reading from different positions (offsets) in the log. This design lets you run a fast-reading application (such as an HDFS sink connector) that does very little before committing its offset position back to the consumer group coordinator. Alongside it you can also run a slower-processing application (e.g. a microservice) that might do sequential operations before committing back to the consumer group coordinator that it completed its operation and is ready for the next message.
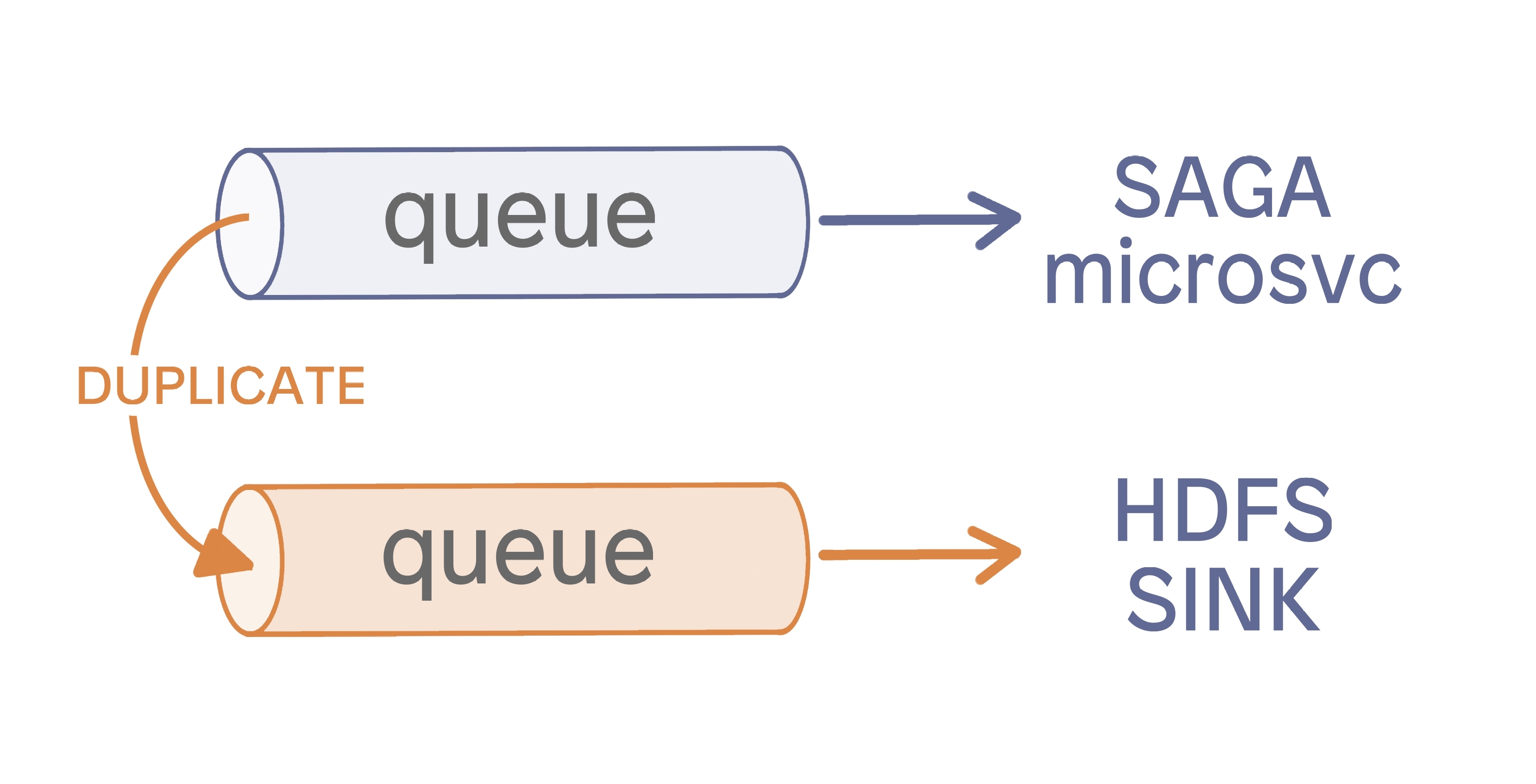
RabbitMQ’s feature-rich product does allow for fan out, but the way it is accomplished is very different. It does fan out by duplicating the queue or “exchange” within the brokers. At this point, multiple applications are able to consume what is essentially the same data from the cluster, but this design uses more resources on the brokers and introduces new administrative challenges.
Under the right conditions, RabbitMQ can scale quite well. In the wild, there are instances of clusters having as many as 1000+ nodes in a cluster (though not recommended) and can sustain 100k+ messages per second with consistently low latency, which is certainly impressive. However, many users encounter challenges with the default behavior of getting an acknowledgment for each message. As we’ve discussed, the more features you add (e.g. persistence, durable queues, routing, and transactions), the more that resource overhead impacts performance. That, in turn, limits scalability.
Another challenge for messaging platforms is that queues can become “backed up” when there is heavier production than consumers can keep up with. One of the side effects of this is that producers end up getting throttled, which creates “back pressure” problems. Operators may then be tempted to “drain the queue” using suboptimal techniques such as thread pooling to scale consumption. Another operation that tends to be required is “shovel operations” (i.e. moving data temporarily out of queues on one cluster and into queues on another cluster) to save on disk space. These can cause the cluster to seize up for short intervals, during which time you are simply hoping for the best!
Another point to note with regard to scale is that RabbitMQ’s performance degrades with higher throughput of larger message sizes. While a 4KB message will tend to perform pretty well, an increase of message size to 16KB will introduce significant latency.
In contrast, Redpanda is highly scalable because of its simple writing and reading of data to/from an append-only log. The consumers and producers can alter their performance profile by allowing for batch producer acknowledgments and consumer commits, leading to much higher throughputs. Consumers can scale horizontally up to the number of partitions for the topic, so the consumer application can control how quickly it wants to reduce its lag, which is a welcome solution for RabbitMQ operators that are challenged by a need to more quickly drain the queue before the broker(s) run out of memory.
It’s not uncommon to see Kafka clusters pushing 1-2 Gigabytes per second, and Redpanda scales to magnitudes higher than Kafka. Redpanda and Kafka can also handle much larger message sizes than RabbitMQ and similar systems (and Redpanda can handle far larger message sizes than Kafka) without diminishing cluster performance. The producers and consumers have configurations to help with latency on larger message sizes if that becomes an issue.
RabbitMQ should not be thought of as brittle nor incapable of High Availability (HA). It is a distributed platform with many product features that support resilience. For example, RabbitMQ does well behind load balancers; if a node goes down, there is a rebalancing process that happens without manual intervention. You can configure RabbitMQ to use multiple nodes for a single queue so that if one node goes down, there are others that can take over the responsibility. This is similar in concept to how Redpanda and Kafka operate.
However, in contrast to Redpanda, the more nodes you add to a queue, the greater the performance penalty. This forces the architect to make a decision on whether high availability or performance is more important for the application.
In streaming data platforms, HA is achieved by replicating the data across a set number of nodes for the topic. If any single node goes down, leader election occurs, and another broker steps in to take over as the leader or follower for partitions on the failed broker. In Kafka, Zookeeper® has traditionally served in this role, triggering and managing the “rebalance,” but Zookeeper is being phased out in favor of Raft.
In Redpanda, the same leader election process happens and is already done in an optimized implementation of Raft. In fact, Raft is embedded throughout Redpanda – the replication protocol, the partitions, and even the cores of the nodes are all Raft groups, so it’s much easier to achieve HA via the replication factor and the general principles of Raft. You can read more about how we do it in this Raft blog as well as this blog on Redpanda HA.
Everyone always wants to declare a winner and a loser, but can’t we all just be winners in our own way? That’s kind of how this ends.
If you’re looking for the pub/sub platform side of your application architecture to be responsible for rule-based routing while allowing consumers to not be responsible for much, RabbitMQ might be good for you. If you want scheduling and expiration of messages or sophisticated error handling (where you don’t want consumers to have to worry about it), that’s also potentially a great fit for RabbitMQ. If you have mostly smaller messages and simply need to know point-in-time values while maintaining decent scale and HA, RabbitMQ would be a fine candidate!
However, if you want to build an event-driven architecture by leveraging a rich ecosystem of smart clients, or if you want to further decouple your systems, Redpanda is a great choice. Perhaps you want a central data bus as your system of record from which you can always replay your business events. Use Redpanda. If your RabbitMQ deployment is becoming untenable after enabling all of the additional features you want, yet Kafka is missing the mark on the latency profile that your distributed applications require, take Redpanda for a spin and maybe run an Open Messaging Benchmark to prove it out!
It is also entirely possible that you have use cases that warrant using both RabbitMQ and Redpanda together in the same environment, maybe even within the same application. There are HA, scalable source and sink connectors built for Kafka Connect that work great with Redpanda’s Kafka API, so you don’t even have to write code to integrate the systems.
It is important to note that this article focuses on the traditional RabbitMQ queue-based functionality. RabbitMQ has released a feature called Streams that provides functionality that is closer to what Redpanda and Kafka do. You will read in the aforementioned link that, although RabbitMQ Streams does provide the ability to do some of the features you will read about in the Redpanda section above like fan-out, replay/persistence, and allows for larger throughput and message sizes, it removes much of the queueing “smarts.'' You don’t get the benefits of features like prioritization, exclusivity, TTL, and dead letter queues, and — more importantly — you can’t use the Kafka API directly. A comparison of RabbitMQ Streams really belongs in a different article comparing the Kafka API vs proprietary pub/sub technologies.
RabbitMQ is an excellent tool with many loyal and happy users, but it’s one type of animal with its own specialized attributes. Redpanda is a different tool with similar functionality that excels in ways RabbitMQ does not.
Consider what you need, not only today but also as your applications evolve, and choose the solution that will give you the best performance and the most flexibility. Maybe that’s RabbitMQ. Maybe it’s Redpanda. Maybe it’s both, with several RabbitMQ clusters pulling from a central Redpanda cluster that gives you performance and durability that RabbitMQ can’t.
If you’re curious about the specific differences between Redpanda and other streaming data platforms like Kafka, you can view this benchmark or download our comprehensive guide here.
To take Redpanda for a test drive, get started here. We also have a lively and helpful Redpanda Community on Slack where you can interact with our Solution Architects and Core Engineers to get any and all of your burning questions answered.
Check out our documentation to understand the nuts and bolts of how the platform works or read our blogs to see the plethora of ways to integrate with Redpanda. We also recently unveiled our Redpanda University if you’d like a self-paced, guided learning experience
Subscribe to our VIP (very important panda) mailing list to pounce on the latest blogs, surprise announcements, and community events!
Opt out anytime.

