




Full CDC semantics land in the Iceberg output for Redpanda Connect
Your lakehouse mirrors the database, instantly.
Integrate Redpanda and MSF for enhanced performance, lower TCO, and fully managed cloud services









Recently, Amazon rebranded their proprietary stream processing product, Kinesis Data Analytics, to Amazon Managed Services for Apache Flink® (MSF), which provides a managed Apache Flink® deployment for customers.
MSF supports ingesting from several data sources, including Amazon Kinesis Data Streams and Amazon Managed Services for Kafka, enabling developers to build stream processing applications that process incoming data. Tight integration with data sources and stream processing engine provides more performance and convenience to customers who have deployed their entire streaming application suite on AWS.
However, MSF can also be integrated with other Kafka-API-compatible streaming data platforms, such as Redpanda, via the built-in Kafka data connector. This allows organizations to mix and match the benefits of performance, cost savings, and data safety. Plus, if having a fully managed deployment and data sovereignty are top priorities, Redpanda facilitates it by providing a BYOC deployment option for AWS customers.
In this post, we explore how you can leverage Redpanda to build stream processing applications with Amazon Managed Services for Flink. We also highlight several additional benefits that Redpanda provides over Amazon MSK, so you can make the right choice when selecting your streaming data source.
Redpanda is a streaming data platform that offers low-latency data ingestion at scale while ensuring data safety and reliability. On the other hand, Apache Flink is a framework that allows developers to create stream processing applications that can consume data from sources, such as Redpanda. By combining the two, developers can build resilient and scalable stream processing applications.
MFS supports ingesting data into Flink applications from several streaming sources, including Amazon MSK and Amazon Kinesis. Since Redpanda has API compatibility with Apache Kafka, you can consider Redpanda as an alternative to Amazon MSK, allowing you to use Redpanda as an upstream data source for Flink applications.
Why Redpanda on MFS provides a better developer experience when building stream processing applications?
Deployment coverage - AWS provides a good foundation for deploying stream processing applications across multiple AZs and regions, ensuring fault tolerance, scalability, and reduced latency. Redpanda’s deployment significantly benefits from that foundation.
Cost-efficient storage - Redpanda's Tiered Storage leverages Amazon S3 as its storage engine, providing a scalable and cost-efficient solution for ingesting growing volumes of streaming data.
Low hardware footprint - Redpanda’s architecture uses significantly fewer resources than Kafka, reducing its footprint on the infrastructure and lowering the overall TCO.
Fully managed platform - Both Redpanda and MSF provide a fully managed deployment model. At the time of this writing, the Flink version supported by MSF is 1.15. For developers, this means not worrying about Flink upgrades and focusing on the application logic.
When configuring a Flink application to ingest from a streaming data source, MSF asks for network information related to the data source, including VPC name, subnets, and security group information. To allow MSF applications to communicate with the upstream data source, VPC peering must be properly configured.
For example, when configuring a streaming application, you must provide a VPC that already exists or a VPC associated with an already provisioned MSK cluster.
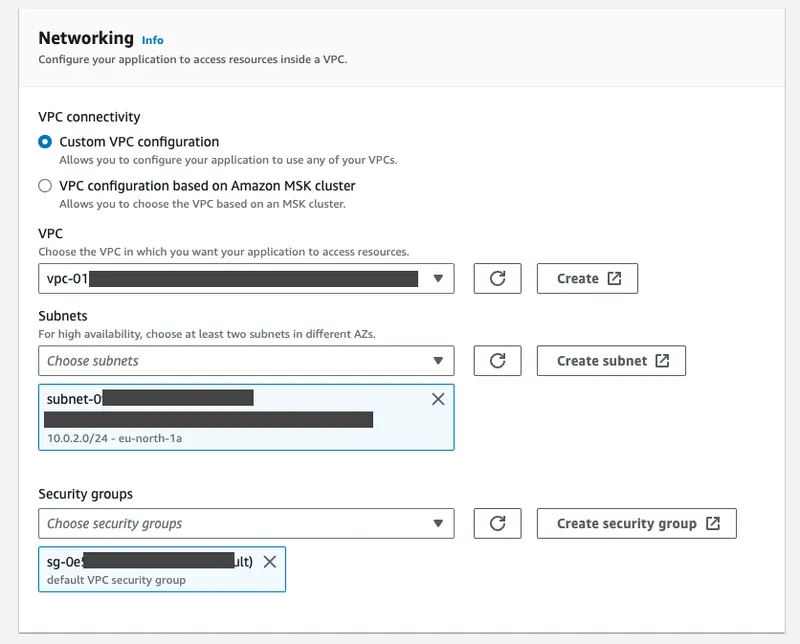
This configuration allows users who have deployed a BYOC Redpanda cluster in AWS to configure it as a streaming data source to MSF, allowing them to consume data as if they were consuming from an Amazon MSK cluster. The reason is that Redpanda is compatible with Apache Kafka APIs.
The only requirement to have here is that Redpanda’s VPC name, NAT gateway, subnets, and other access credentials must be known and accessible to your MSF application.
[CTA_MODULE]
Redpanda Cloud supports the Bring Your Own Cloud (BYOC) deployment model—a fully managed Redpanda cluster hosted on your cloud while Redpanda takes care of operations, monitoring, and maintenance. That means you get complete control over your data in the cloud —as well as the relief of fully managed services.
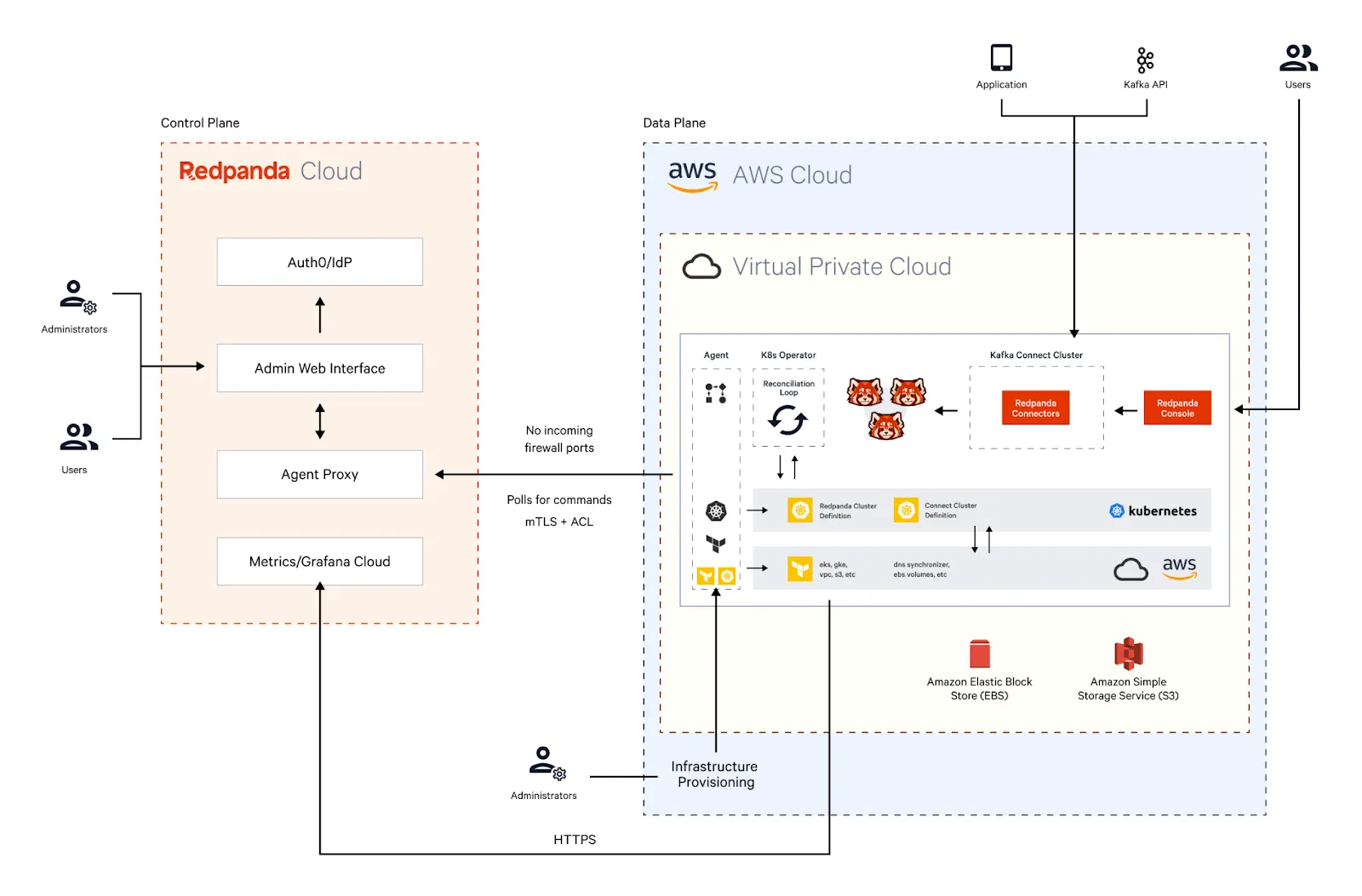
Furthermore, BYOC’s privacy-first architecture drives compliance for streaming data and allows you to scale on your own infrastructure while maintaining data sovereignty requirements. If you’d like a more detailed explanation of how BYOC works, read our post on why we think data sovereignty is the future of the cloud.
Redpanda currently supports provisioning BYOC clusters on cloud providers, including AWS and GCP. For users who have deployed most of their data platform on AWS cloud, Redpanda offers the flexibility of deploying a Redpanda cluster in their preferred deployment region, VPC, and subnet and have it secured with their own IAM roles.
Installing a BYOC cluster is quick and simple. Then, you can access the cluster either through the Internet or VPC Peerings, based on your preference. The access details will be used when configuring your Flink application to consume data from the provisioned Redpanda cluster.
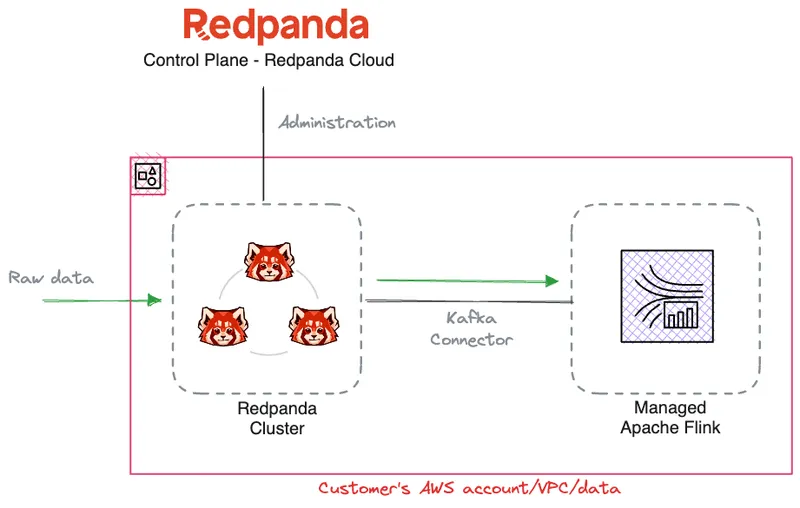
Now that we understand the integration options between the two technologies, let’s explore how to combine them to build and run stream processing applications. We can classify the typical developer workflow into three phases: data ingestion, application development, and maintenance.
Once the BYOC cluster is set up, you can stream data into the Redpanda cluster. Since Redpanda is compatible with Kafka read/write interfaces, you can use existing Kafka data producers, such as the ones already used with Apache Kafka or MSK.
When the data streams in, Redpanda Console, a developer-friendly tool that’s also hosted within the Redpanda Cloud, shows what’s happening with your cluster. The Console shows you the shape of your data–browse topics, and schemas and see the payload at a glance—a useful ability for developers debugging or generally designing their applications.
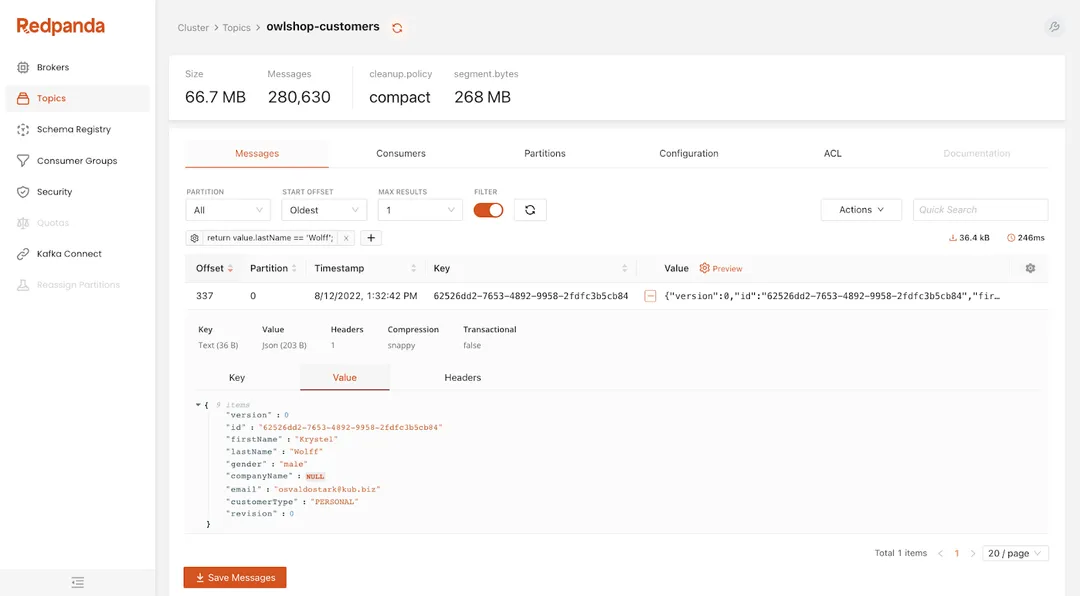
When the Redpanda cluster starts ingesting data, you can write Flink applications to process them. For that, MSF offers you two models: Streaming applications and Studio notebooks.
Streaming applications continuously read and analyze data from a connected streaming source in real time. They are typical applications you build with the Flink framework while leveraging various API abstraction levels, including DataStreams API, Table API, Python, and SQL through Java, Scala, and Python SDK interfaces.
Studio notebooks allow you to interactively query data streams using a notebook, a web-based development environment powered by Apache Zeppelin, and Flink as the stream processing engine.
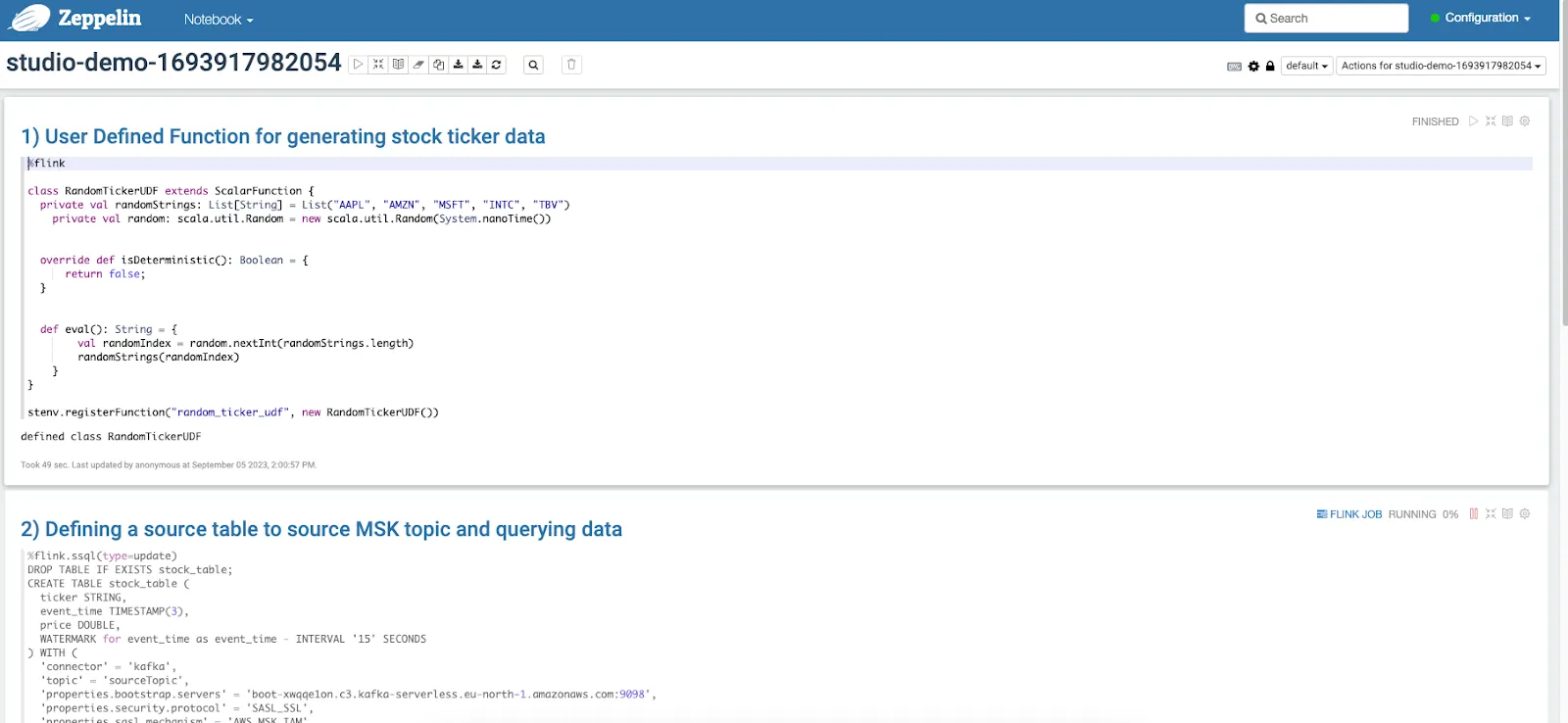
Whether you are developing a streaming application or a Studio notebook, you can use the Kafka connector to read from and write data to Redpanda. The Kafka connector is natively available in MSF.
An example of defining a Flink SQL table to ingest a stream called stocks from Redpanda follows.
%flink.ssql(type=update)
DROP TABLE IF EXISTS stock_table;
CREATE TABLE stock_table (
ticker STRING,
event_time TIMESTAMP(3),
price DOUBLE,
WATERMARK for event_time as event_time - INTERVAL '15' SECONDS
) WITH (
'connector' = 'kafka',
'topic' = 'stocks',
'properties.bootstrap.servers' = '<REDPANDA_BOOTSTRAP_SERVER_ADDRESS',
'properties.security.protocol' = 'SASL_SSL',
'properties.sasl.mechanism' = 'AWS_MSK_IAM',
'properties.group.id' = 'myGroup',
'scan.startup.mode' = 'earliest-offset',
'format' = 'json'
);Once the application is written, it should be packaged into an S3 bucket and submitted to MSF for execution.
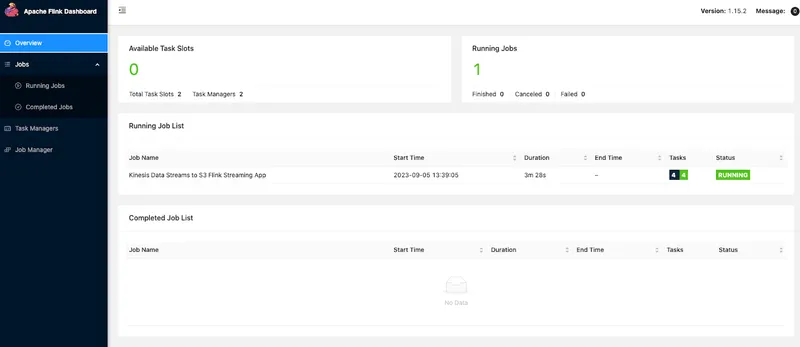
Once stream processing applications are deployed, Redpanda and MSF provide the necessary measures to ensure they are fault-tolerant, scalable, and perform well.
Redpanda Console provides the necessary metrics indicating the status of the Redpanda cluster, including the throughput, latency, and other health status metrics. Additionally, applications deployed to MSF use AWS CloudWatch for logging, metrics, and setting up alarms.
In this post, we explored the possibility of integrating a BYOC Redpanda cluster as a streaming data source for Amazon Managed Services for Flink.
Its API compatibility with Kafka allows Redpanda to act as a drop-in replacement for Kafka and its hosted variants like Amazon MSK. Furthermore, the relevant network configurations in MSF enable you to configure a BYOC Redpanda cluster as a streaming data source. Redpanda’s BYOC deployment model offers the flexibility of deploying a Redpanda cluster within your AWS VPC. When developing stream processing applications, you can use the Flink Kafka connector, which is natively available in MSF, to read data from and write data to Redpanda.
To get started, you can try Redpanda Cloud or grab the Community Edition from the Redpanda GitHub repo. If you have questions about integrating with Redpanda, chat with our engineers in the Redpanda Community on Slack.
Subscribe to our VIP (very important panda) mailing list to pounce on the latest blogs, surprise announcements, and community events!
Opt out anytime.

