




What is an Agentic Data Plane?
What is it, why enterprises need it, and how to evaluate one
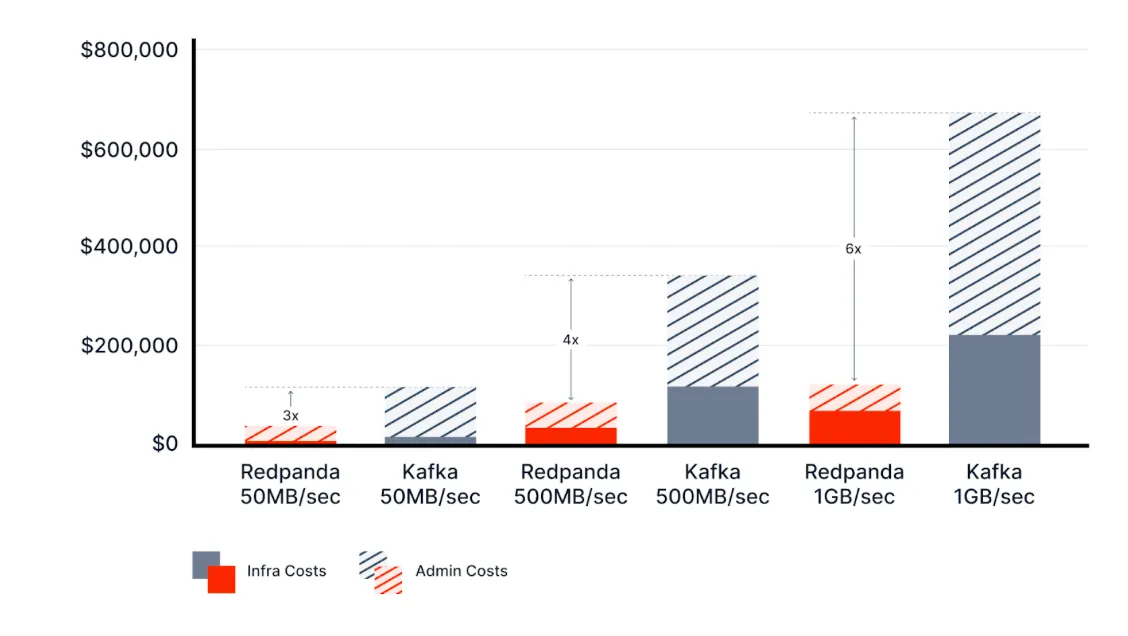
Monitoring that even (Franz) Kafka would approve of









Real-time data systems tend not to have amazing developer experiences. There are two core reasons.
One, the developer experience for the engine itself is poor. Streaming engines tend to be difficult to use, difficult to spin up, and difficult to operate on an ongoing basis, as they have a ton of moving parts and complexity to manage. This is especially painful when trying to self-host, develop locally, or integrate into a modern continuous integration/deployment (CI/CD) pipeline. As a result, only the most sophisticated and experienced engineers can make proper use of these systems, leaving behind most software developers and narrowing the market for event-based architectures.
Second, most streaming data systems don’t integrate well into the rest of the developer workflow, and they lack many of the “creature comforts” developers are used to seeing in their other tools. The modern developer workflow extends much further out and is much broader in scope than the streaming engine itself. For streaming engines to cement their place in the hearts and minds of developers, they must offer solutions to the rest of the puzzle.
We’ve talked before about why developers love Redpanda’s core developer experience, which is leaps and bounds above what’s come before in the streaming space. With native Raft, no JVM, and full Kafka compatibility, Redpanda enables developers to do their best work, reducing unnecessary complexity and toil while doing it all at the highest throughput, lowest latency, and, importantly, lowest cost.
But it’s also important to address that second point — how Redpanda creates a holistic developer experience that services all aspects of the modern developer’s workflow, from deployment to monitoring and Day 2 operations to long-term storage. These remain unresolved, “open loops” that have prevented a broader audience of developers and organizations from taking advantage of real-time capabilities.
At Lightspeed, it’s our core belief that there’s a potentially massive market expansion opportunity for real-time, streaming data systems. Opening up this opportunity will require thinking much bigger about what a streaming engine can be and do.
That’s where Redpanda comes in.
Too often, developers looking to deploy streaming data systems are left to their own devices when it comes to deployment. Deployment is often a mess, involving multiple separate binaries, each with its own peculiarities, requiring engineers to develop expertise in systems they couldn't care less about and in which they have no comparative advantage. Streaming systems can easily become one of the most painful pieces of infrastructure they’ll deploy.
Further, developers increasingly see the cloud as their default deployment platform. In the same way that SaaS relieves some of the operational burden of running software by offloading that to the vendor, developers would love to be able to consume cloud-based streaming services with as few wrinkles as possible. Developers want a cloud experience but their organizations don’t want to lose data sovereignty. They need a security model that works within the constraints of the typical enterprise while also getting the ease of use of the cloud — the best of both worlds.
Lastly, developers on the bleeding edge don’t want to think about infrastructure at all, cloud or otherwise. They don’t want to think about servers, machines, nodes, availability zones, or regions. They want access to true streaming as a service rather than streaming as a server. In other words, they want serverless, and they want it now.
The modern developer experience requires a modern platform. Redpanda is that platform.
Here’s how Redpanda makes deployment a breeze.
The core of the Redpanda deployment model is the way its nodes are architected. Redpanda nodes are fully-contained processes that ship with everything needed in a modern streaming system, including an HTTP proxy, a Raft-based consensus mechanism, and a schema registry. Every node runs the same, single binary, leading to significant operational simplification along with a more efficient overall operating model.
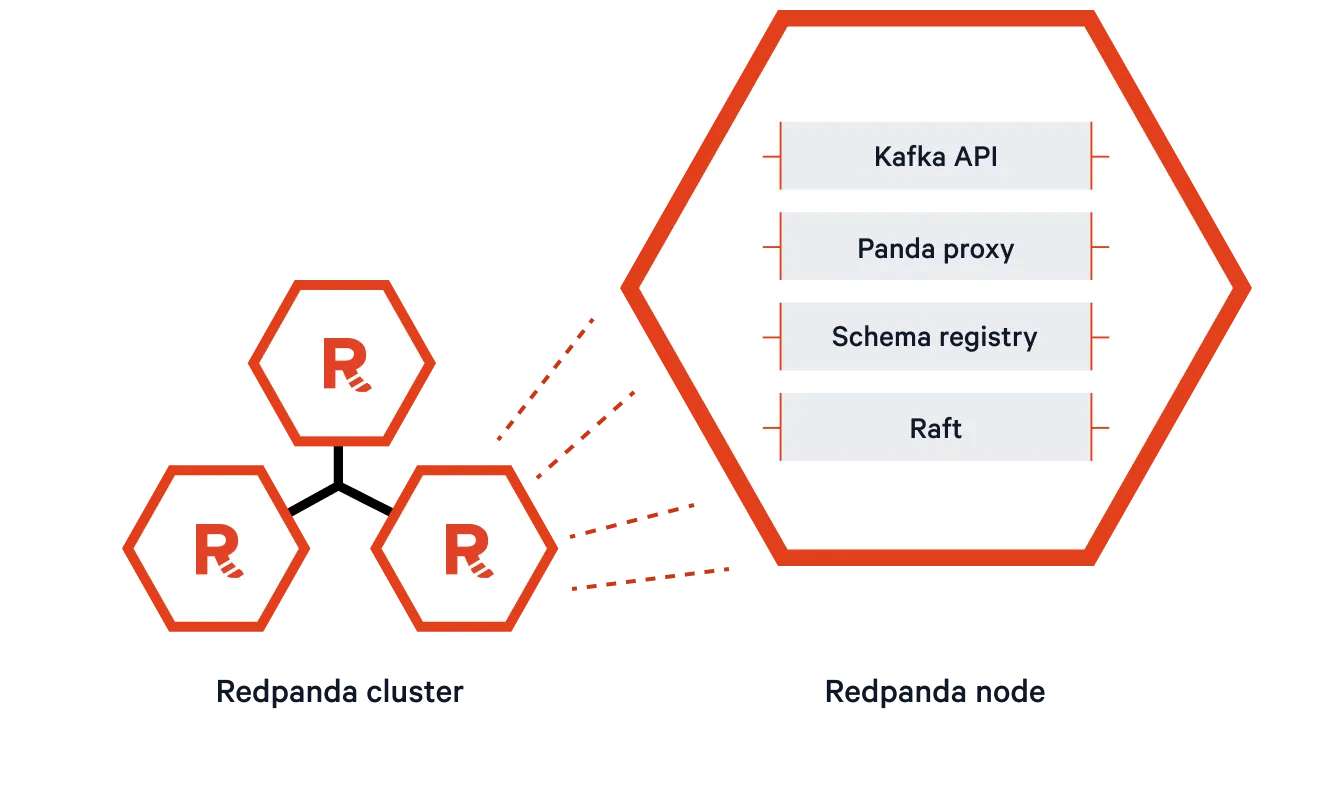
It’s hard to overstate how game-changing this is. Due to this architecture, running a single Redpanda cluster doesn’t require operating a massive fleet of varying services. This is a massive boon for developer productivity and also enables Redpanda to go where previous streaming systems have struggled, including edge / IoT deployments and CI/CD pipelines with tight performance requirements and resource constraints.
“The latency and the throughput we got with almost no configuration was incredible. Redpanda is fast, reliable, friction-free and has very low operational overhead.” - Alpaca
Redpanda’s cloud turns the table on traditional cloud infrastructure. While the company does offer standard, dedicated, managed clusters in the cloud, they didn’t want to stop there. Redpanda went further, pioneering a deployment model they call BYOC, or, “bring your own cloud.” BYOC lets customers deploy Redpanda clusters within their own cloud environment, while still being fully managed by Redpanda.
“BYOC’s privacy-first architecture drives compliance for streaming data, and allows you to scale on your own infrastructure while maintaining data sovereignty requirements.” - Bring Your Own Cloud (BYOC): best of both worlds
Redpanda does this by cleanly splitting the control and the data plane. The data plane stays within the customer’s cloud account, while the control plane stays on Redpanda’s side. This creates an incredibly slick and elegant setup, with proper separation of concerns between Redpanda’s and the customer’s cloud environment. With BYOC, organizations get all the benefits of the cloud while retaining data sovereignty and maintaining privacy.
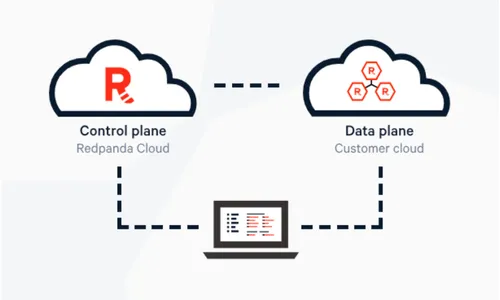
Redpanda takes care of everything you’d expect in a modern, competent cloud service, like provisioning, monitoring, and maintenance, while sensitive data and credentials never leave the customer environment. Rolling upgrades that the customer can control ensure zero application downtime. For obvious reasons, BYOC has become an incredibly popular deployment paradigm among Redpanda users.
“Redpanda BYOC gives us a fully managed Kafka service running on our own cloud servers, balancing our internal compliance requirements with ease of use, and without compromising performance and compatibility.” - LiveRamp
[CTA_MODULE]
Lastly, Redpanda is working on a number of exciting features around serverless, a relatively new paradigm within the context of streaming systems. This is their focus on developer experience taken to the logical extreme — what a streaming data system could look like from the perspective of a developer who doesn’t want to worry about systems or deployment at all.
Importantly, serverless isn’t some esoteric technology that is far ahead of where developers are today. Serverless is here now. According to Datadog’s 2022 State of Serverless report, over half of the organizations surveyed in each of the major public clouds have already adopted serverless in some fashion. For AWS in particular that number is over 70%.
And yet streaming data systems haven’t kept pace. Developers today who want to pair streaming data with a serverless approach are largely figuring it out on their own.
We believe that serverless, in addition to Redpanda’s planned WebAssembly capabilities, is the last major step toward unlocking accessible streaming and event-based systems for the great majority of developers out there. Developers will be able to talk to a streaming data system in their native tongue and perform data transformations on the fly, almost like a universal Google Translate for streaming data.
With JavaScript and Python being the world’s most popular programming languages broadly and most used specifically within serverless functions, Redpanda’s upcoming serverless offerings will expand the relevant, addressable audience for streaming data by an order of magnitude or more.
Streaming systems can be daunting, intimidating systems that are difficult to manage for the average developer. These difficulties are made no easier by the fact that the command line (i.e. a dark screen with some white text scrawled over it) is often the default way to manage these systems. Ad hoc inspection and analysis is much harder than it should be.
This is especially frustrating during crisis situations, such as production infrastructure going down. In such situations, time is of the essence, and engineers don’t have time to wrestle information out of their tools, searching for obscure command line invocations that they didn’t even know existed. Once the information is located, it often appears as a torrential downpour of logs and metrics, with little to no organization or formatting. We’ve all been there.
This just won’t do. While many developers swear by their terminals, many would love to have a more visual and intuitive representation of their infrastructure. This is especially true of younger, more junior developers who didn’t grow up writing MS-DOS applications and who have a higher standard for developer experience.
Redpanda Console is a single pane of glass for managing the entire Kafka ecosystem. All of your streaming infrastructure in one place, with all the admin capabilities organizations expect:
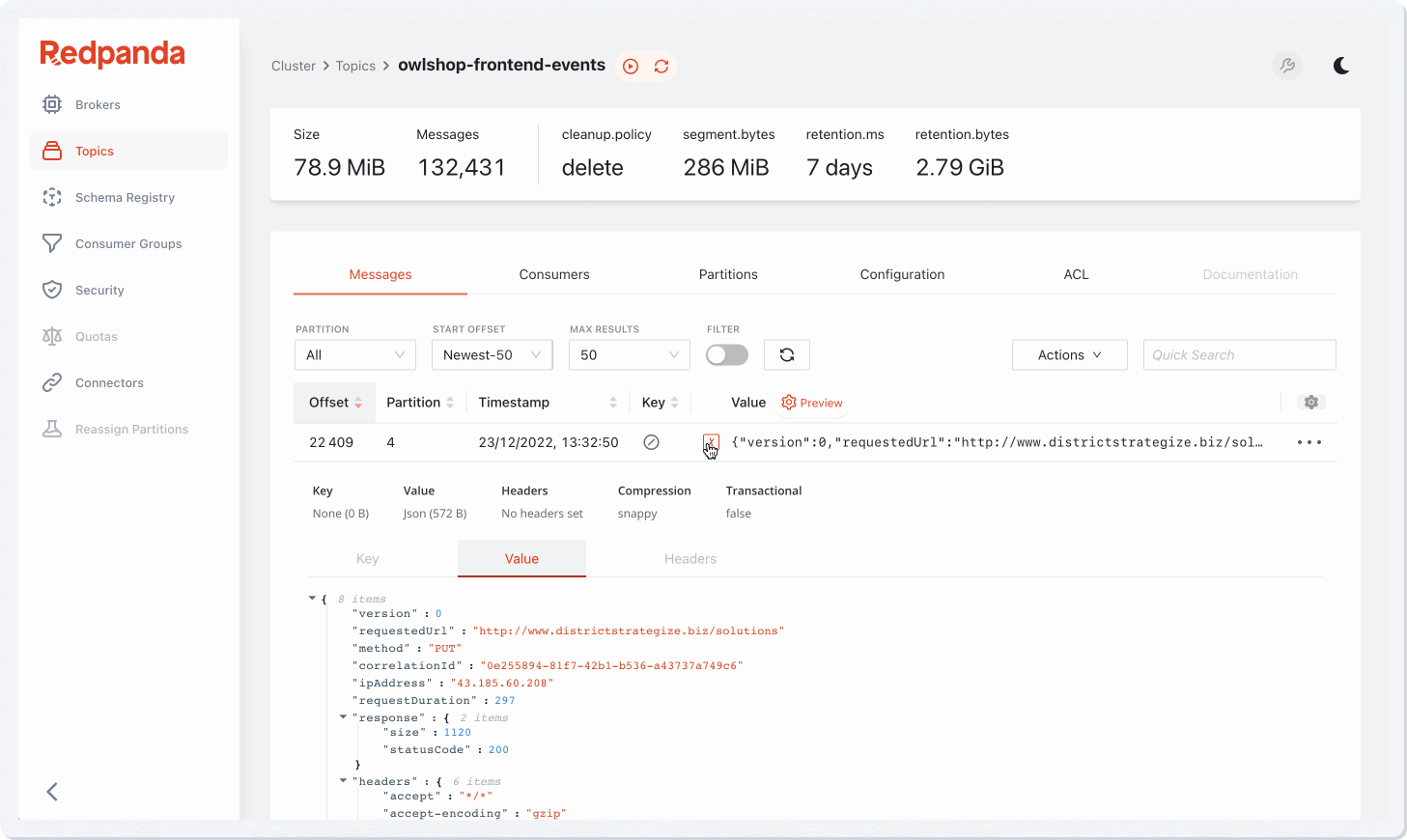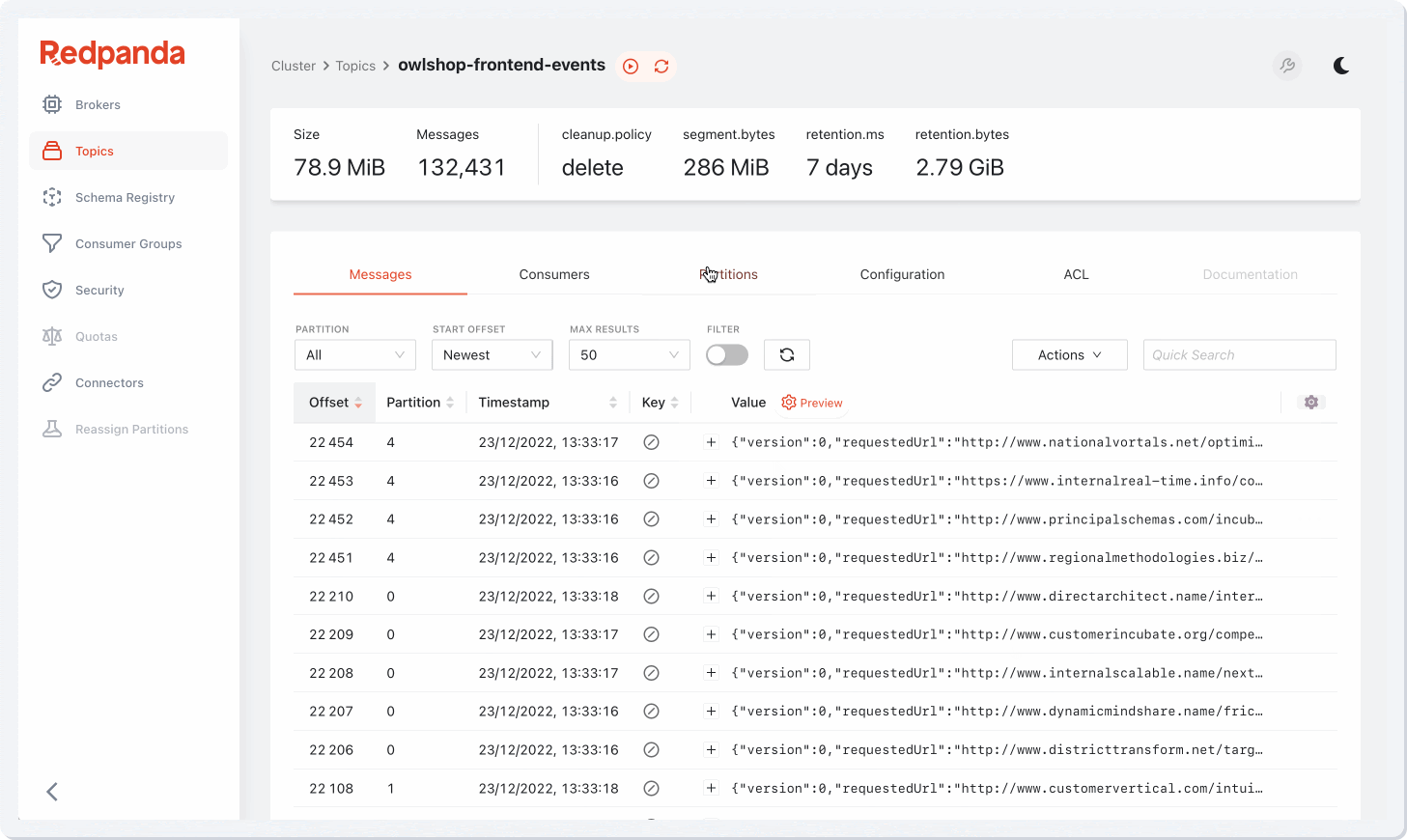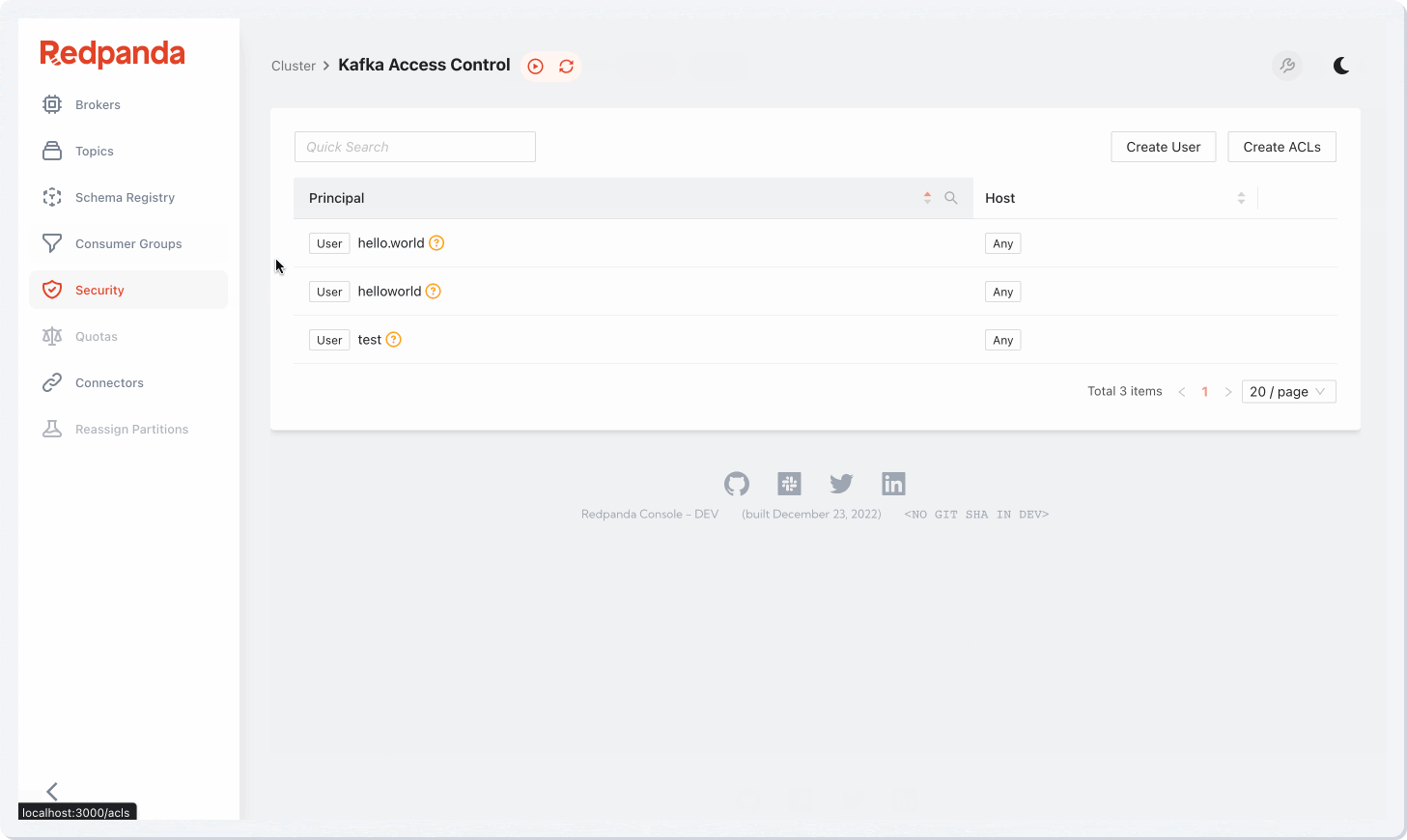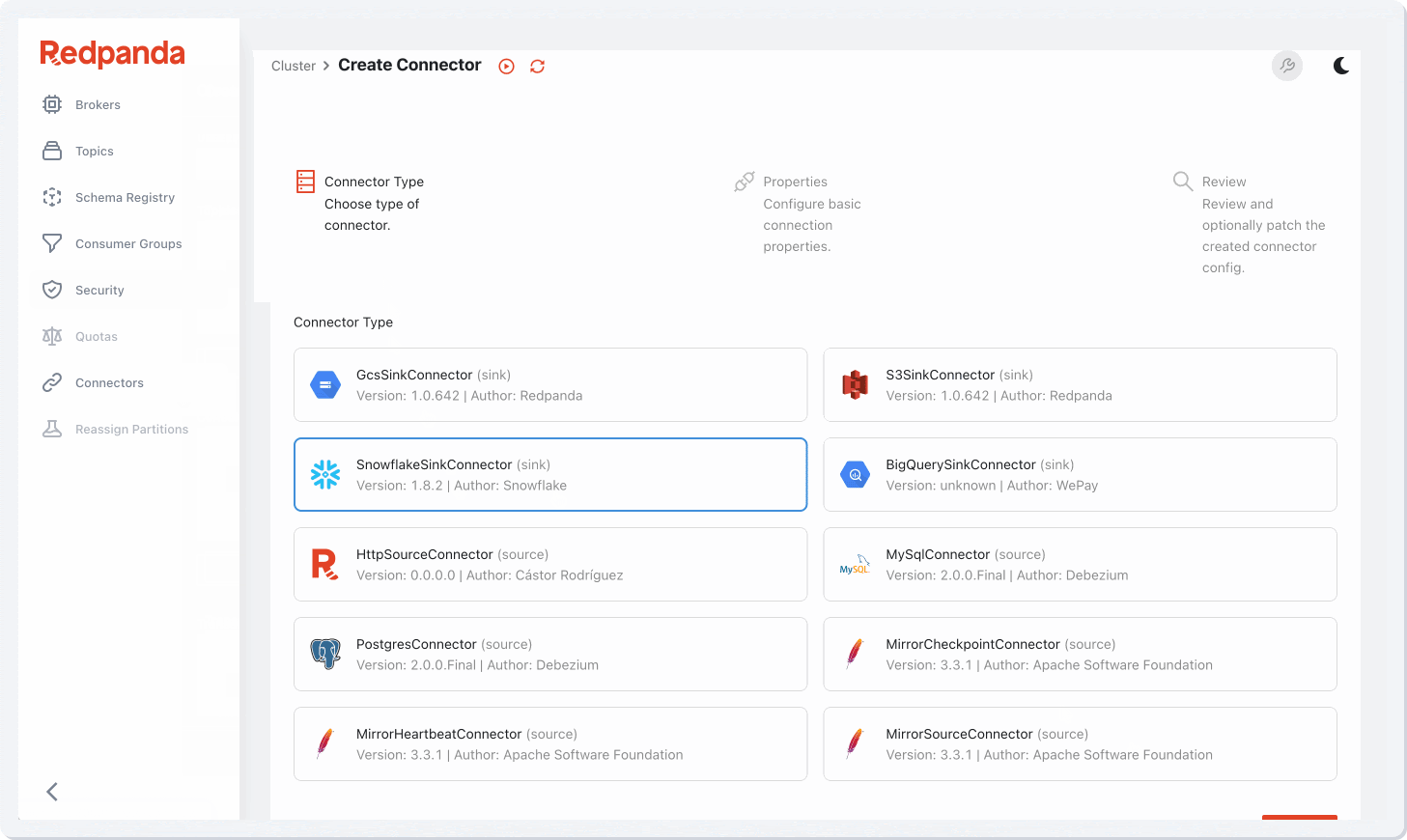
But the most impressive thing about Redpanda Console is that it’s not merely a “dashboard” with a slew of charts and numbers — it goes so much further than that.
Redpanda Console gives developers data observability superpowers they aren’t used to. This includes capabilities like push-down JavaScript filter, allowing users to filter their cluster’s data at any level of complexity by writing programmable data filters in JavaScript, with encoding support for JSON, Protobuf, Avro, and more.
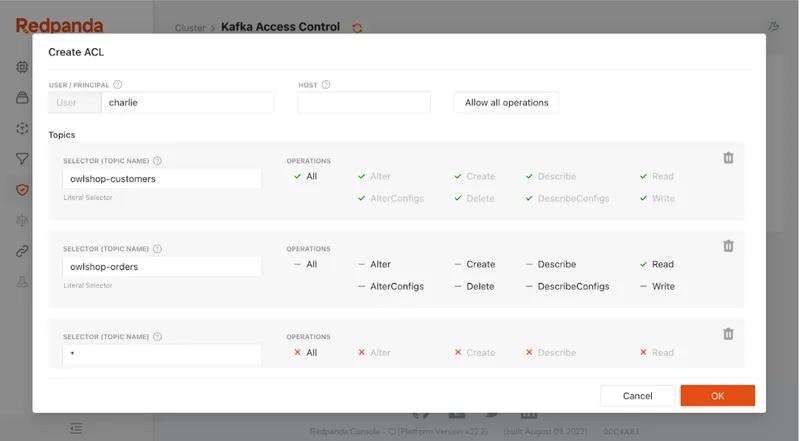
The console also simplifies and strengthens access control. The console presents an easy interface for configuring access control lists (ACLs), setting up fine-grained role-based access control (RBAC), and reviewing comprehensive audit logs. It also integrates tightly with all the identity providers you’d expect, like GitHub, Okta, and Google, enabling Single Sign On (SSO) access.
“Redpanda Console delivers a tremendous improvement in the productivity, effectiveness and quality of life of developers and operators who work with Redpanda or Kafka” - Redpanda Console: Putting the “fun” back into Kafka
Okay, so a developer is running Redpanda. They’ve spun it up within their own cloud account as enabled by the BYOC model, and they have the beautiful Redpanda Console setup giving them full observability and control over their cluster. Everything is hooked up and data is flowing through Redpanda.
But all that data has to go somewhere. It’s time to talk storage.
Storage is quite important in the context of event-based architectures:
This is why Redpanda went out of its way to submit itself for testing by trusted third parties like Jepsen.
“How did Redpanda fare in its Jepsen testing? Redpanda is a safe system without known consistency problems. The consensus layer is solid. The idempotency and transactional layers had issues that we have already fixed. The only consistency findings we haven’t addressed reflect unusual properties of the Apache Kafka protocol itself, rather than of a particular implementation.” - Redpanda’s official Jepsen report
But it’s not just about the CAP theorem and distributed systems. Putting on our investor “cap” for a second — data gravity is how nearly every mission-critical data system of the past generated significant value for its creators and its customers. For a data infrastructure company to build a large and valuable business, it must hold and retain customer data for extended periods of time. Ephemerality won’t cut it:
Here too, Redpanda has it covered. Presciently, the team built Redpanda with the cloud as its default storage tier. This is a stronger statement than merely being “cloud-native”: Redpanda intelligently manages reads and writes behind the scenes to provide the lowest friction and highest performance, effectively becoming an infinite storage destination:
“Making cloud the default storage tier unlocks new streaming data use cases that were once considered out of reach. The long-term data retention capability encourages businesses to treat Redpanda as the “single source of truth” for their historical records.” - How Redpanda’s cloud-first storage model reduces TCO
In addition to unlimited data retention, Redpanda’s cloud-first architecture enables:
Redpanda accomplishes this with its Shadowing Indexing architecture, which was built from scratch to support cloud-native Tiered Storage, enabling Redpanda to seamlessly move data between brokers and reliable, cheap cloud stores like Amazon S3 or Google Cloud Storage (GCS). Users can access their data using the same Redpanda/Kafka APIs they’re used to, while getting infinite data retention and scalability for free.
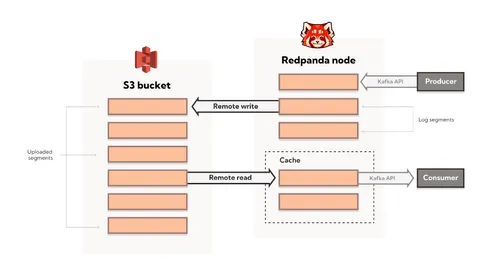
The upshot of all this innovation is amazing ease of use and performance at an incredibly low cost.
We’ve already talked a bit about data sovereignty in the context of the cloud, where security and retaining control of enterprise data are key concerns. That’s a very literal interpretation of sovereignty. But there’s another, potentially equally important notion of control that developers and organizations care about, but often give up as a side effect of adopting cloud data stores. Often enough, one doesn’t even realize something has been lost until you’re in too deep.
“Data sovereignty is much harder to achieve than data privacy. Privacy can be achieved with policy: delete this, mask that, obfuscate here, index like so. Sovereignty can only be achieved if you, the user, control the hard drive lifecycle where data resides. There are no two ways about it. Data either lives inside the hard drives that you control or it does not.” - Data sovereignty is the future of cloud
Redpanda believes developers should control the data they produce. This goes without saying in the world of on-prem. However, we cannot take this for granted in the era of the cloud:
These aren’t (pleasant sounding) data lakes or even (somewhat less enticing) data warehouses, they’re data jails, and the vendor holds the only key. As far as Redpanda is concerned, that isn’t true data sovereignty.
Redpanda wants to fix this. Leveraging popular open data formats like Apache Iceberg and the unique BYOC architecture we discussed earlier, Redpanda will enable developers to finally regain ownership over their data. Developers will be able to pick their preferred storage vendor while maintaining ownership, queryability, indexing, and portability no matter where the data ends up. Today it’s S3, tomorrow it’s Snowflake and Databricks, and in the future, it’ll be any vendor they’d like. Organizations will also be able to bring their own query engines to the data, no matter the underlying data format.
Developers will once again own their data. All enabled by Redpanda.
Redpanda meets developers where they are and then enables them to go even further. That reach will push Redpanda to places no streaming system has gone before, driving a level of mission-criticality beyond most other developer infrastructure. The ease of use and incredible flexibility of Redpanda will generate developer love and appreciation for the product. And, with infinite retention and a strong commitment to data sovereignty, Redpanda’s “data gravity” will only grow.

It’s why we were so excited to lead their recent $100M Series C financing. The real-time revolution has only just begun, and Redpanda is leading the charge.
— Nnamdi Iregbulem, Partner
Originally published on Medium.
Nnamdi Iregbulem is a Partner at Lightspeed Venture Partners, where he focuses on software investments across developer tools, application infrastructure, and machine learning. He works closely with Lightspeed portfolio companies RedPanda, Materialize, and several other unannounced investments. A self-taught programmer, Nnamdi loves to code in his free time and especially loves Python.
Lightspeed is a multi-stage VC firm focused on accelerating disruptive innovations and trends in the enterprise, consumer, and health sectors. Lightspeed has backed 600+ companies globally in the past two decades including Nutanix, Affirm, AppDynamics, MuleSoft, Snap, and Nest.
Subscribe to our VIP (very important panda) mailing list to pounce on the latest blogs, surprise announcements, and community events!
Opt out anytime.

