





Real-time Change Data Capture with Redpanda Connect and MySQL
Stream every insert, update, and delete from your database the moment it happens

Take a closer look into our latest cost-saving feature—now available in Redpanda 23.2








Redpanda recently announced Redpanda 23.2, which is now generally available for both the self-hosted Redpanda Platform and fully-managed Redpanda Cloud deployments. This release is packed with new features that improve performance, automation, and cost optimization. One of the most important new capabilities of 23.2 is follower fetching.
In an earlier post, we provided a high-level overview of follower fetching. But if you’re the technical type, you’ll want to dive deeper into the details. That’s precisely what this post is for. So, settle in and keep reading to learn how follower fetching works, its benefits, and a few tips to get you up and running in no time.
Let’s start from the top. Data replication in Redpanda happens at the partition granularity. Each topic partition in Redpanda is replicated N times, where N is the replication factor of the topic. For example, if the replication factor is three, each partition will have three replicas. That means if one of the brokers fails, the data will still be available in the other two brokers.
For each partition, one replica is designated as the leader, while others are followers. The leader is responsible for accepting writes from producers and distributing the writes to the followers. The followers then store the writes in their own logs and keep them in sync with the leader.

If the leader fails, one of the followers will be elected as the new leader. The followers will then continue to replicate the data from the new leader. This ensures the data is always available even if one or more brokers fail.
Now that we understand the primitives, let's see how a typical consumer fetches records from a Redpanda topic partition.
As we learned above, all read and write requests must be routed to the broker containing the leader replica of a partition. So, the consumer sends a metadata request to the cluster to find out where the leader is located.
The consumer then receives the metadata response, locates the leader for the partition, and sends a "fetch request" to the leader. A fetch request is a way of requesting records from Redpanda––something like, "Please send me messages starting at offset 32 in partition 0 of topic Foo."
Once the leader receives the fetch request, it’s checked for validity. That includes checking if the offset exists for the specific partition. If the client requests a message that has been deleted or an offset that hasn't been created yet, the broker will return an error. Otherwise, the records are returned to the consumer. The following diagram illustrates this whole operation.

Standard fetching works efficiently in terms of cost and latency when consumers and leader replicas are located in the same rack or availability zone (AZ). Situations where they spread across different AZs or regions, result in expensive reads as network traffic crosses availability zones. Also, fetch latency will become a critical concern.
However, we often find Redpanda clusters deployed across multiple AZs and regions to take advantage of high availability, disaster recovery, and also being geographically close to their customers.
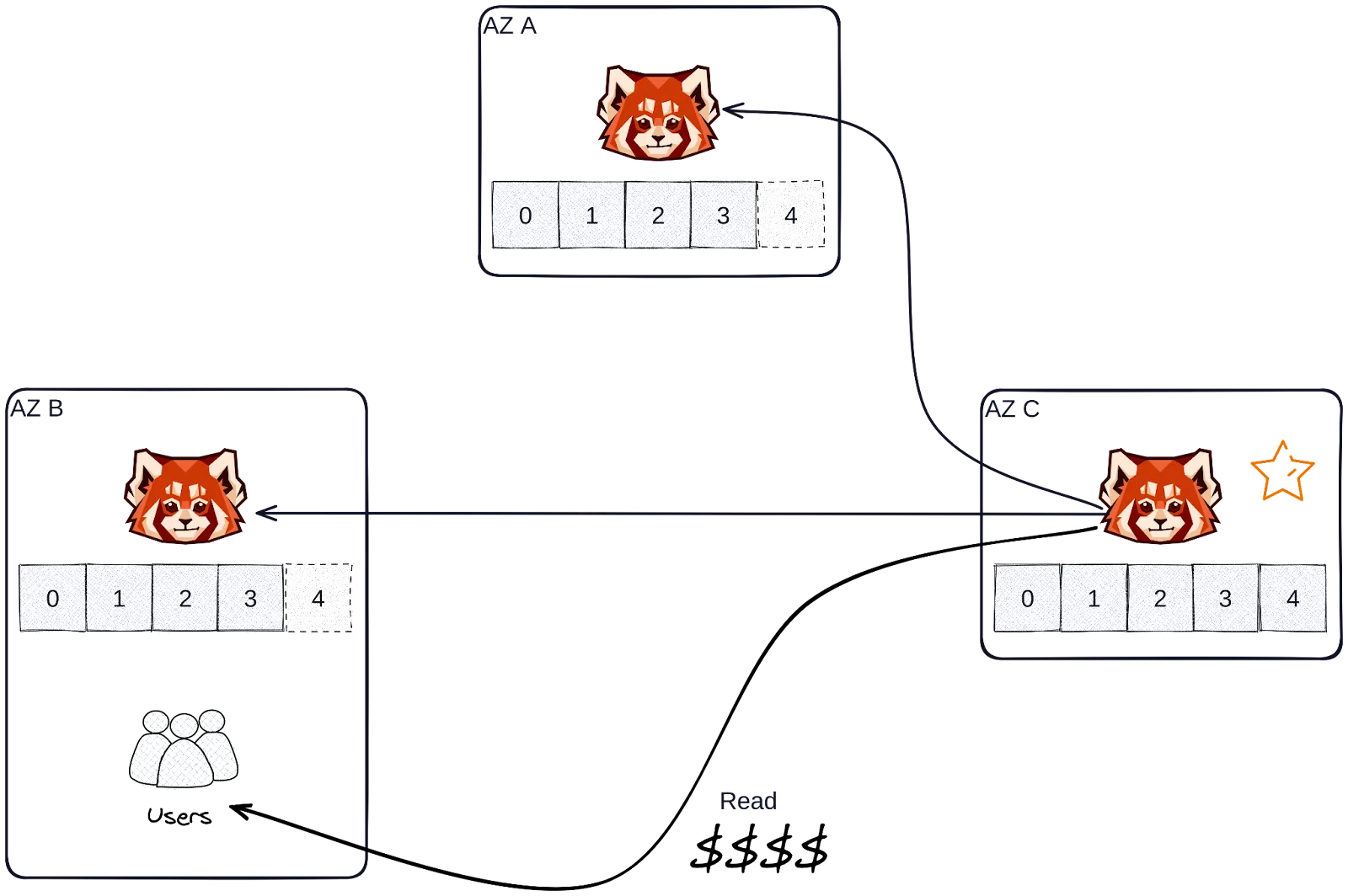
Follower fetching enables a consumer to fetch records from the closest replica of a topic partition, regardless of whether it's a leader or a follower.
To understand follower fetching, you should first learn how Redpanda would pick the "closest replica" for a consumer. It gets to a point where Redpanda depends on rack awareness, treating replicas in the same rack as the consumer as the closest. The consumer indicates its rack ID by setting the client.rack property on fetch requests, allowing Redpanda to serve a replica from the same rack ID, if available.
A rack would be equivalent to an availability zone or a region when a Redpanda cluster is deployed in the cloud. The following diagram illustrates the sequence of steps for follower fetching. (It’s similar to standard fetching.)

Remember, the first fetch request from a consumer is processed by the leader replica. To find the leader, the consumer first sends a metadata request to Redpanda, asking where it is.
The consumer receives the metadata response and sends the first fetch request to the leader, along with the client.rack property indicating its rack ID.
The leader checks for a replica (itself or a follower) with a rack ID matching the consumer's rack ID. If a replica with a matching rack ID is found, the fetch request returns records from that replica. Otherwise, the fetch is handled by the leader.
With follower fetching, consumers get the flexibility of reading from non-leader replicas as well, allowing them to:
If you’re curious to see the cost and efficiency advantages of follower fetching in action, check out our high availability series where we run a multi-AZ cluster deployment with follower fetching.
The following guidelines will help you achieve smooth functioning with follower fetching.
client.rack property to benefit from follower fetching. Clients will always consume from leaders, regardless of rack configuration, and enable follower fetching on the cluster side if they do not have any particular preferences.Redpanda follower fetching is generally available and ready to start saving you on cloud infrastructure costs! To enable follower fetching in Redpanda using the 23.2 release, simply configure properties for the consumer and the Redpanda cluster and node:
enable_rack_awareness property to true.rack property to a specified rack ID / name of the node’s AZ.client.rack property to a specified rack ID / name of the node’s AZ.To learn more about how follower fetching works, check out our documentation. If you haven’t already, check our full announcement and peruse the 23.2 release notes on GitHub. To see it in action for yourself, try Redpanda for free!
Have questions about follower fetching or getting started with Redpanda? Jump in the Redpanda Community on Slack and ask away.
Subscribe to our VIP (very important panda) mailing list to pounce on the latest blogs, surprise announcements, and community events!
Opt out anytime.

