

Flink vs. Spark—A detailed comparison guide











Flink vs. Spark
Stream processing is a continuous method of ingesting, analyzing, and processing data as it is generated. The input data is unbounded and has no predetermined beginning or end. It is a series of events that arrive at the stream processing system (e.g., credit card transactions, clicks on a website, or sensor readings from Internet of Things [IoT] devices).
Two prominent technologies, Apache Spark™, and Apache Flink®, are leading frameworks in stream processing. Where Spark initially gained popularity for batch processing, it has since evolved to incorporate structured streaming for real-time data analysis. In contrast, Flink was built from the ground up for real-time processing and can do batch processing too. Despite their distinct origins, both excel as low-latency and scalable technologies.
This article explores the two frameworks, their features, and why they are often compared in the context of real-time data analysis.
Summary of differences: Flink vs. Spark
Introduction to Spark and Flink
Spark is a powerful analytics engine built for large-scale data processing. It offers a broad range of capabilities, including SQL query execution and graph analysis, making it a flexible option for various data tasks.
Initially, Spark Streaming allowed real-time data stream processing from sources such as Kafka, Kinesis, and TCP sockets. You could use functions like map, reduce, join, and window to analyze data and export to storage or dashboards. Building on this, Structured Streaming was developed to work seamlessly with Spark SQL. The Structured Streaming approach processes data in small batches to achieve low latency(around 100 milliseconds) and ensure reliable, exactly-once processing.
With the release of Spark 2.3, a Continuous Processing mode was added. Instead of launching periodic tasks, Spark runs long-running tasks that continuously read, process, and write data. Continuous mode cuts latency down to as low as one millisecond. It offers flexibility to fit specific application requirements without altering the core query logic.
In contrast, Flink was initially designed as a distributed stream processing framework with additional batch processing capabilities. Applications are built as streaming dataflows, and user-defined operators modify the data. These dataflows are structured as directed graphs, flowing from source to sink. You can use it for building and running stateful streaming applications at scale with robust fault tolerance.
Data processing in Spark vs. Flink
Next, let's look at how the two technologies process data.
Batch processing
Spark was designed for efficient batch processing. It utilizes a Resilient Distributed Dataset (RDD) framework to handle large datasets efficiently. RDD is a fundamental concept and data structure in Spark. It represents an immutable, distributed collection of data objects that can be processed in parallel.
You can use Spark to perform complex operations on RDDs. Its in-memory computation drastically speeds up processing times over traditional disk-based methods. Spark’s Directed Acyclic Graph (DAG) scheduler further optimizes task execution, enhancing performance by reducing data shuffling.
In the figure below, each data set in Spark's stream processing is represented as a Resilient Distributed Dataset (RDD), serving as the fundamental abstraction for fault-tolerant datasets. This design enables streaming data to undergo processing utilizing any Spark code or library available.
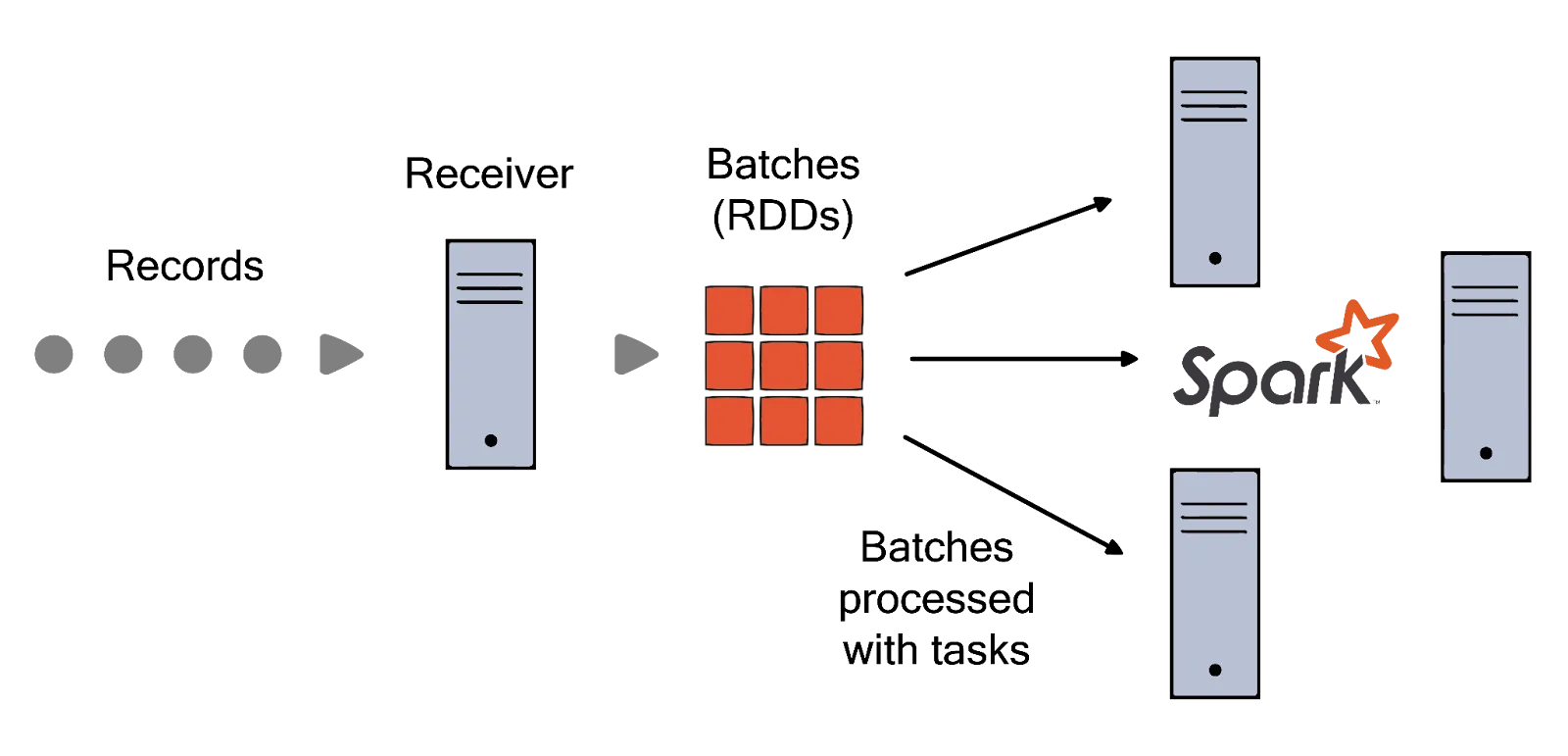
In contrast, Flink approaches batch processing as a subset of stream processing. It treats batch processing as the processing of bounded streams. To handle batch jobs, you can use the same DataStream APIs that leverage Flink’s streaming capabilities—such as windowing, state management, and event time processing. Flink also provides a DataSet API that specifically targets efficient batch processing with a richer set of operations for static data.

Stream processing
Spark applies the batch approach to stream processing. It treats unbounded data as a series of micro-batches. Developers can apply batch processing techniques to streaming data, using a unified API for both types of data processing. However, this micro-batching technique introduces some latency, making it less ideal for scenarios requiring real-time insights.
In contrast, Flink is designed with a true streaming model at its core. It handles data as a continuous flow and enables real-time processing with minimal latency. It offers low-latency processing of unbounded streams with high throughput. Its flexible state management allows detailed control over stateful computations, essential for real-time applications.

Key differences: Spark vs. Flink
Below we explore differences in the operational capabilities of the two technologies.
Data ingestion
Structured Streaming in Spark processes data in small, incremental batches. These batches are treated as continuous streams, allowing for real-time data processing. So, while Structured Streaming processes data in batches, it still provides an API for real-time data ingestion.
It supports a variety of data sources, including Kafka, Flume, Kinesis, and TCP sockets. Spark APIs rely on schema information to handle data at different stages like data ingestion, query planning, storage, and access. Schema information provides insights into how the data is shaped regarding fields and types. We can use schema information to drive optimizations at different levels.
The following sources are currently available in the Spark distribution of structured streaming:
- File—supports ingestion of data stored in formats such as JSON, CSV, Parquet, ORC, and plain text.
- Kafka—Facilitates the consumption of streaming data from Apache Kafka® or Kafka-compatible solutions like Redpanda.
- Socket—Enables a TCP socket client to connect to a server and consume text-based streams, which must be UTF-8 encoded.
- Rate—generates an internal stream of (timestamp, value) records at a configurable rate, primarily used for educational and testing purposes.
In comparison, Flink provides the DataStream API for various data ingestion connectors, such as Kafka, Amazon Kinesis Streams, RabbitMQ, Apache Cassandra, Google PubSub, Apache Pulsar, MongoDB, and others.
Both Spark and Flink enable parallel ingestion of event streams. They also provide checkpointing capabilities to ensure reliable recovery from failure.
Window operations
Window operations are fundamental in processing streaming data, allowing computations over a sliding time window or a set number of elements. Spark Streaming offers two primary types of window operations:
- Tumbling window processes data in fixed-sized, non-overlapping windows based on time. Each record belongs to exactly one window.
- Sliding window processes data in windows that slide over time, allowing records to belong to multiple windows and providing more flexibility in analyzing data trends.
Conversely, Flink provides a richer set of window operations, catering to more complex scenarios. Tumbling and sliding windows are similar to Spark, but Flink's real-time processing capabilities often result in more precise windowing operations. Additionally, you have:
- Session windows that dynamically capture activity sessions, closing the window after a period of inactivity. This is particularly useful for user session analysis.
- Global windows require a custom trigger to determine when to evaluate data, offering maximum control over window operations.
Join operations
Join operations are crucial in both batch and stream processing. They combine data from two or more datasets based on a common key or condition.
Spark Streaming supports:
- Stream-stream joins for joining two data streams, enabling real-time analytics on correlated data from different sources.
- Stream-dataset joins for combining streaming data with static datasets, useful for enriching streaming data with additional context.
Flink extends the concept with:
- Window join that joins streams based on window assignments—useful for correlating events that occur within the same time frame.
- Interval join that joins events from two streams that occur within a defined interval, offering flexibility in temporal data correlation.
Watermarks
Watermarks are pivotal in both Spark and Flink for dealing with late data in stream processing. They mark when data is considered complete, allowing the system to handle late-arriving data gracefully.
Spark implements watermarks within its Structured Streaming model, enabling event-time window operations and stateful processing even when data arrives late. Flink offers more fine-grained control over watermarks. You can adjust them dynamically based on the observed data, which is particularly beneficial in environments with highly variable data arrival patterns.
State management
State enables Flink and Spark to “remember” the data they have processed over time. State management keeps track of ongoing tasks and ensures everything stays correct and safe. It is a critical aspect of stream data processing for enhanced accuracy, failure handling, and efficient use of resources.
In Spark, stateful operations rely on a versioned key-value store known as the state store for storing intermediate data. This allows for read and write operations across batches in structured streaming.
By default, Spark uses an HDFS backend state store provider. Initially, data is stored in a memory map and subsequently backed by files in an HDFS-compatible filesystem for durability. As an alternative, RocksDB for state management is also available. It keeps state data outside the JVM memory, in native memory, and on the local disk.
In contrast, Flink treats states as first-class citizens with mechanisms for reading and updating state information during task execution.
It scopes an operator state to individual operator tasks, meaning the state is exclusive to records processed by the same task. Tasks of other operators cannot access this state. Flink also has a keyed state based on specific keys in the operator's input records. Each key-value has its own state instance, with all records of the same key directed to the task managing the state for that key.
Scaling stateful operators in Flink involves partitioning and redistributing the state among various parallel tasks, which requires careful management to ensure consistency.
Checkpoints and savepoints
In Spark, State changes automatically persist to a checkpoint location by Structured Streaming, ensuring fault tolerance. Similarly, Flink also employs checkpoints and offers an additional savepoints feature for fault tolerance and application management. Checkpoints are automatic and ensure consistent application states for recovery. Savepoints are manually triggered snapshots used for starting, stopping, and migrating applications without losing state.
How to choose between Flink vs. Spark
When choosing between the two technologies, you should consider your application's various processing requirements. We provide some key considerations below.
Scalability
Flink excels in real-time stream data processing thanks to its native support for continuous streaming models and iterative algorithms. Flink's architecture eliminates the need for micro-batching and reduces latency. It provides high-throughput processing and scales dynamically, managing resources efficiently to maintain performance under varying loads.
Microbatching in Spark sometimes creates additional latency. For example, Imagine a streaming application analyzing stock market data at a rate of 10,000 transactions per second. Micro-batching in Spark may cause delays between batch boundaries.
Consequently, the application struggles to keep up with the high data influx. In such scenarios, Flink's continuous streaming model, free from micro-batching constraints, can offer superior performance with reduced latency.
Fault tolerance
Spark uses a lineage-based fault tolerance mechanism, re-computing lost data from the lineage information. This approach accurately restores the pipeline's state, ensuring data consistency and enabling efficient failure recovery.
Flink utilizes distributed snapshotting based on the Chandy-Lamport algorithm. It captures a consistent global state of a distributed system by recording or “snapshotting” local states without halting the system's operation. It offers quick recovery by restoring the last known good state. This method ensures data consistency and supports exactly-once processing semantics.
It is better to choose Flink if you need more fault tolerance. Let’s understand with an example of an e-commerce platform processing customer transactions. In the event of a hardware failure or network disruption, Flink's fault-tolerant mechanisms ensure that processing continues seamlessly without data loss or interruption. In contrast, Apache Spark may face failures under similar circumstances, potentially resulting in data inconsistencies or processing disruptions.
Slow consumers
Backpressure mechanisms allow a system to gracefully handle scenarios where data is being produced at a faster rate than it can be consumed. Spark may encounter challenges with backpressure due to its reliance on the underlying data processing engine, which is not explicitly designed to handle backpressure. If your consumers are slow, this can potentially lead to performance issues.
Flink has built-in flow control mechanisms to manage backpressure. These mechanisms adjust the data processing rate based on system resource monitoring. This ensures the system remains stable under high loads without creating bottlenecks.
Unique libraries and APIs
Flink offers libraries like FlinkML for machine learning, FlinkCEP for complex event processing, and Gelly for graph processing. It provides APIs in Java, Scala, and Python.
Spark provides a broader range of libraries, including MLlib for machine learning, GraphX for graph processing, and Spark Streaming for real-time data. Spark supports APIs in Java, Scala, Python, and R, catering to a diverse developer community.
If your application is predominantly Java, Scala, and Python, Flink is a good choice; otherwise, you may have to go with Spark. Spark is also more popular among ML engineers to train models using batched data. It has a vibrant ML ecosystem around its SDKs and libraries.
Summary
In conclusion, Spark and Flink are powerful and versatile distributed data processing frameworks with unique strengths and capabilities. The choice between Flink vs. Spark depends on the project's specific needs.
- Scalability: Flink offers dynamic scaling for real-time processing; Spark excels in batch processing scalability.
- Fault tolerance: Flink uses distributed snapshotting; Spark employs lineage-based fault recovery.
- Backpressure handling: Flink includes built-in mechanisms; Spark may face challenges.
- Unique features: Flink's architecture is optimized for low-latency streaming; Spark provides a rich ecosystem for diverse data processing needs, including batch and micro-batch streaming.
Spark may be better if the primary use case is batch processing and the project requires a more mature platform with a broader range of libraries and tools. However, if the project requires real-time data processing and advanced windowing functions, Flink is preferred.