

Flink SQL—from fundamentals to advanced operations











Flink SQL
Recently, Apache Flink® has been the top choice for developers seeking an open-source stream processing framework. In the previous chapters of this guide, we have already discussed how Flink excels in real-time data processing thanks to features like event-time processing, exact-once semantics, high throughput, low latency, and versatile windowing mechanisms.
Flink SQL, a layered API of the Flink framework, is a user-friendly interface and a powerful tool for querying and analyzing data. It is an ANSI standard-compliant SQL engine that can process hundreds and thousands of critical applications in real time.
So, what makes Flink SQL a popular choice for stream processing and analytics? Let’s explore this in this article.
Summary of key Flink SQL concepts
Why choose Flink SQL for stream processing and analytics?
Flink has become popular due to its proficiency in managing real-time and historical data. Its main advantage lies in its familiar SQL abstraction over Flink functionality.
The benefits of Flink SQL include:
SQL query integration
You'll find Flink SQL easy to grasp if you're familiar with SQL. Flink SQL eliminates the need to learn new frameworks and languages for data analysis. You can use standard-compliant and popular SQL operations, such as filtering, aggregating, joining, and windowing.
Focus on high-level processing logic
Flink SQL is language-agnostic, meaning developers can utilize their preferred programming language and keep focus on high-level processing logic rather than on implementation details. In your code, you can tell Flink what should be done rather than how it should be done.
That way, you can easily handle complex data transformations and write queries, reducing development overheads. Developers can also improve code readability on projects.
Efficient data processing at scale
Flink SQL can handle high-volume data without compromising performance. It provides built-in optimization for query execution, allowing developers to process large-scale data sets faster and improve performance for analytical tasks.
[CTA_MODULE]
Fundamentals of Flink SQL
Flink SQL adheres to ANSI SQL standards and offers SQL-like language. It uses Apache Calcite as the underlying SQL engine, ensuring compatibility with existing SQL syntax. This alignment with industry standards empowers developers to focus on the business logic rather than grapple with the complexities of the underlying infrastructure. It enhances the accessibility and efficiency of real-time data processing.
Let’s discuss the fundamentals of Flink SQL one by one, beginning with its layered architecture.
Flink SQL abstraction over other APIs
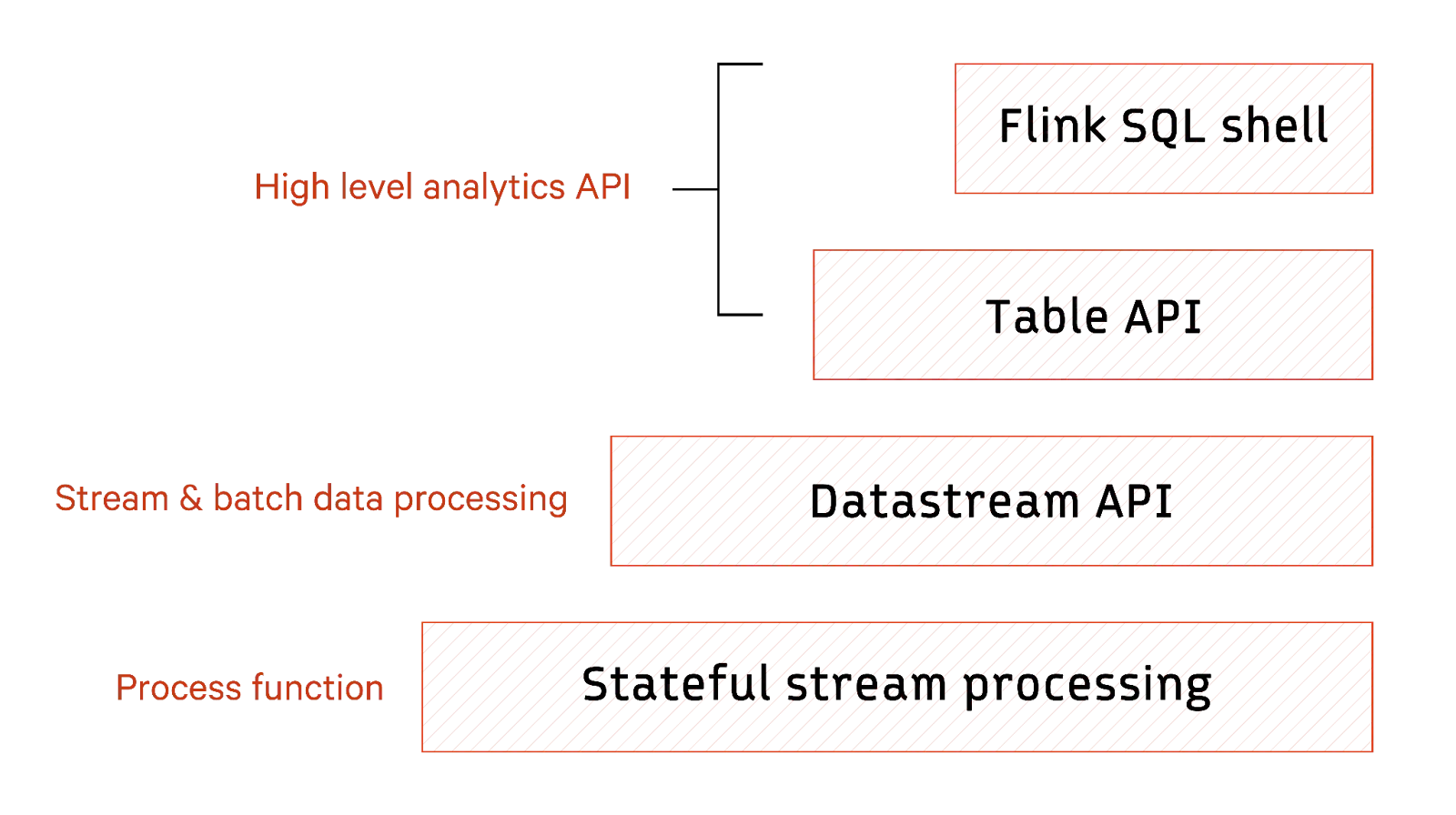
Flink offers a range of APIs to support stream processing. It starts with the lowest layer, stateful stream processing, which allows prompt data stream processing while maintaining its state. This layer connects to the layer above it through a component known as ProcessFunction, which is a fundamental part of the Flink runtime. ProcessFunction defines how each data stream element should be processed, giving developers precise control over the processing tasks.
The DataStream API provides a versatile toolkit for most applications. It offers stream and batch data processing operations, including joins, transformations, and aggregations. Additionally, the Table API simplifies relational operations by treating data as tables with attached schemas. Developers can seamlessly integrate these APIs, switching between tables and DataStream/DataSet as needed for hybrid processing approaches. Finally, at the top is the Flink SQL shell layer, which provides interoperability by allowing developers to use SQL queries to interact with the Table API and extract the desired results.
Data operations
Flink SQL represents streaming data as tables for creation and manipulation. These tables act as structured views over data streams. You can easily query and process them using SQL syntax. You can perform many familiar data operations on streaming data, including filtering, aggregation, and joining multiple data streams. Like in a simple SQL database, these operations allow you to derive meaningful insights from complex data sets in real time.
Below is a basic example of a Flink SQL query. This code snippet:
- Sets up a Flink execution environment and table environment.
- Registers a data source.
- Runs a simple Flink SQL query to calculate total sales by-product from an orders dataset stored in a CSV file.
// Set up the execution environment
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
// Register data source
tableEnv.executeSql("CREATE TABLE Orders (orderId INT, product STRING, amount INT) " +
"WITH ('connector' = 'filesystem', 'path' = '/path/to/orders.csv', 'format' = 'csv')");
// Execute Flink SQL query
tableEnv.executeSql("SELECT product, SUM(amount) AS total_sales FROM Orders GROUP BY product").print();Advanced query operations
Next, let’s look at more advanced Flink SQL operations.
Performance optimization techniques
Query optimization allows the selection of the most efficient execution plan for a given query. This includes meticulously analyzing data sources and queries to determine the best way to retrieve results. Flink SQL offers query optimization techniques like:
Cost-based
Flink SQL prefers the lowest-cost query plans. This is done by analyzing different query plans and assigning costs to each. The cost optimization metrics could vary depending on the data size, available resources, and execution of various operators.
Operator fusion
Serialization and deserialization between operations can affect latency and introduce performance overheads, especially in scenarios with multiple data transformation stages. Operator fusion combines adjacent operators, so serialization and consequent deserialization are no longer needed.
Parallel execution
Flink SQL also offers parallel execution for query optimization so multiple data processing tasks run in parallel.
Dynamic optimization
Flink SQL can adapt to changing conditions and optimize the query operations in real time. Dynamic optimization continuously monitors the execution of queries and adjusts the execution plan based on runtime statistics.
Joins
Joins play a crucial role in advanced query operations. They combine data from multiple streams or tables based on common attributes. Flink supports various types of joins.
Inner join
An inner join includes only records with matching values in both streams or tables. In stream processing, an inner join between two streams is typically window-based, meaning it joins records falling within a specified time window. It is ideal for filtering out non-matching data to focus on the intersection.
Outer join
Outer join in Flink includes records that do not have matching values in one or both streams or tables. It is useful when retaining all records from one source, even if there are no matching records in the other.
Cross join
It combines every record from one dataset with every record from another dataset. It is useful when you need to generate all possible data combinations from the two streams. However, it can result in a large volume of output records and should be used with caution.
Time-related joins
Interval join is helpful when one needs to join datasets based on time intervals, while temporal join combines datasets based on time attributes.
Lateral join
It is a powerful feature in Flink that joins a table with a user-defined table function. Users can perform complex calculations or transformations on the fly, enhancing the flexibility and efficiency of query operations.
// Inner join for retrieving customers who have placed orders
SELECT Customers.customer_id, Customers.customer_name, Orders.order_id, Orders.order_date
FROM Customers
INNER JOIN Orders ON Customers.customer_id = Orders.customer_id;Windowing and watermarking
Handling event time is one of the main challenges of real-time streaming analytics, as events are processed as they occur. Flink SQL has built-in support that allows developers to accurately analyze data based on event time. Flink SQL does it with several techniques; notable ones include windowing and watermarking.
Windowing divides data streams into manageable groups or chunks based on different attributes. Flink provides multiple types of windows:
- Tumbling windows divide the data stream into non-overlapping fixed-size windows for fixed-time interval calculations.
- Hopping windows allow overlapping windows for more frequent updates and sliding window calculations.
- Cumulative windows accumulate data over time to perform calculations for time-based aggregations or trend analysis.
Additionally, Flink SQL introduces the concept of watermarks to track the progress of event time and determine when to emit results. It places marks in the data stream to show how far along in time the processing has reached. These marks help ensure data is analyzed correctly, even when events arrive out of order or with delays.
User-defined functions
User-defined functions (UDFs) enable complex data processing and analytics in Flink SQL. You can use them for anything from simple calculations to complex aggregations.
To define a UDF, the user must extend the appropriate Flink class based on the task type. For example, users can just extend the AggregationFunction class to aggregate the records. Once a UDF is created, it can be used in Flink SQL queries by registering it with the Flink execution environment.
You can then invoke the UDF within SQL statements like any built-in function. Users can call the UDF by its name and pass the required parameters, allowing for seamless integration of custom logic into the data processing pipeline.
Let's consider a scenario where we have a dataset of temperature readings from weather sensors. We want to convert temperatures from Celsius to Fahrenheit using a UDF called celsiusToFahrenheit. For that we would have to implement celsiusToFahrenheit function in Java as we do here:
package com.example.udf;
import org.apache.flink.table.functions.ScalarFunction;
public class TemperatureConverter extends ScalarFunction {
public double eval(double celsiusTemperature) {
// Convert Celsius to Fahrenheit
return (celsiusTemperature * 9 / 5) + 32;
}
}Next, we need to register this function with Flink's SQL runtime. We can do this in our Flink application:
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.TableEnvironment;
public class TemperatureConversionJob {
public static void main(String[] args) throws Exception {
// Set up the execution environment
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
EnvironmentSettings settings = EnvironmentSettings.newInstance().useBlinkPlanner().inStreamingMode().build();
TableEnvironment tEnv = TableEnvironment.create(settings);
// Register the UDF
tEnv.createTemporarySystemFunction("celsiusToFahrenheit", TemperatureConverter.class);
// Define the table schema
String ddl = "CREATE TABLE TemperatureReadings (sensorId INT, celsiusTemperature DOUBLE) WITH ('connector' = 'memory')";
// Register the table
tEnv.executeSql(ddl);
// Define and execute the SQL query using Flink SQL
String sqlQuery = "SELECT sensorId, celsiusTemperature, celsiusToFahrenheit(celsiusTemperature) AS fahrenheitTemperature FROM TemperatureReadings";
tEnv.executeSql(sqlQuery).print();
// Execute the Flink job
env.execute("Temperature Conversion Job");
}
}To activate Flink SQL:
- We first created a table environment (
tEnv) usingTableEnvironment.create(settings). - We structured the
TemperatureReadingstable usingDDL (CREATE TABLE). - We registered the table within Flink SQL by executing
tEnv.executeSql(ddl). - This allowed us to run a SQL query (SELECT statement) to convert temperatures from Celsius to Fahrenheit using the
celsiusToFahrenheitUDF. - We executed the Flink job by calling env.execute("Temperature Conversion Job").
Now that we have covered the basics of Flink SQL, let's discuss the best practices you can implement to enhance performance.
[CTA_MODULE]
Flink SQL installation and setup
If you're taking your first steps with Flink SQL, chances are Flink is already up and running on your system. With that in place, let's move on:
- Locate the
flink-conf.yamlfile within your Flink directory. - Make modifications to specify parameters tailored specifically for Flink SQL.
- Save the file and restart Flink.
Environment variables
It is important to set up environment variables, as they provide the necessary configuration parameters for Flink to run efficiently. Environment variables define paths to various directories and files required by Flink. This way, Flink can access the resources and dependencies it needs to run.
- A compatible version of JDK (11 or higher)
- Apache Hadoop installed and configured
Flink has several deployment options, including stand-alone, Kubernetes, etc.—so Hadoop is optional. Depending on the features and connectors you plan to use, there can be additional dependencies. Make sure to review Flink’s documentation for any specific dependencies required.
Accessing Flink SQL
To use Flink SQL functionality, you can leverage either the Flink SQL Shell or integrate Flink SQL queries directly into your Java or Scala applications using Table API or DataStream API. Here's how you can use each approach:
Flink SQL shell
Start the Flink SQL Shell by running the following command in your terminal.
bash
bash
./bin/sql-client.shOnce the shell starts, you can enter SQL queries directly and execute them against your Flink cluster.
Table API
You can use the Table API or DataStream API for Java or Scala applications to create and run Flink SQL queries in your code. Let’s write Flink SQL queries using Table API:
public class Flink SQLExample {
public static void main(String[] args) throws Exception {
// Set up the execution environment
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
DataStream<UserEvent> userEvents = …
// Register the stream as a table
tableEnv.registerDataStream("UserEvents", userEvents, "userId, eventTime, eventType");
// Write Flink SQL query using the Table API
Table resultTable = tableEnv.sqlQuery(
"SELECT eventType, COUNT(*) AS eventCount " +
"FROM UserEvents " +
"GROUP BY eventType"
);
// Convert the result table to a stream
DataStream<Row> resultStream = tableEnv.toAppendStream(resultTable, Row.class);
// Print the result stream
resultStream.print();
// Execute the Flink job
env.execute("Flink SQL Example");
}
}This Java example employs Flink's StreamTableEnvironment and StreamExecutionEnvironment to process a stream of user events, registered as UserEvents. Flink SQL queries calculate event counts by type and store them in resultTable. Finally, the results print via resultStream, and the Flink job runs within the env environment.
Best practices and tips for efficient Flink SQL Development
Here are some of the best practices and tips that developers should keep in mind for Flink SQL applications:
Proper schema design
Proper schema design is crucial in Flink SQL to ensure efficient data processing. Schemas serve as blueprints for data organization in tables. Without a proper schema, queries may take longer to execute and could lead to unnecessary errors or complications.
By carefully considering factors such as the type of data being processed and how it will be used, developers can create an optimal schema that meets their specific needs within the Flink ecosystem.
Choose appropriate window sizes
When using windows, it is important to choose proportionate window sizes based on the data characteristics. If the window size is too small, it can lead to frequent window activations that can result in overhead.
In contrast, if the window size is too large, it can result in delayed processing. It is essential to analyze your data patterns and choose a window size that can strike a balance between both latency and resource utilization.
Limit side-effects in SQL queries
Side effects refer to the drastic operations that can modify the whole state of the systems or have non-deterministic behavior when they interact with external systems.
Minimizing side effects in SQL queries can ensure predictable and efficient processing. You can use Flink’s built-in connectors to interact with external systems instead of SQL operations.
Test and monitor performance
It is important to test your applications under different scenarios thoroughly. Flink provides various monitoring tools, such as Flink’s web dashboard and metrics reporters to identify performance bottlenecks. Profile the Flink SQL queries to identify areas of high resource usage or slow execution times.
To improve performance, you can then use Flink optimization techniques such as query rewriting, join reordering, and operator fusion(explained above). You can also partition the data or adjust windowing strategies to distribute the workload evenly across your cluster.
Registering tables in the catalog
One crucial aspect of data processing is managing metadata, and Flink SQL's catalog makes this task easier. Acting as a centralized repository, the catalog simplifies metadata management. It allows developers to define, organize, and register tables, as well as other data sources, efficiently.
Furthermore, it facilitates seamless integration with external systems and tools. This is especially helpful for developers who want to effectively utilize existing infrastructure and investments.
Despite its numerous functionalities, applications with Flink SQL queries experience malfunctions. Let’s address the common issues with Flink SQL and explore troubleshooting techniques.
Troubleshooting common issues in Flink SQL
Flink SQL offers powerful capabilities for real-time data processing, but like any technology, it can encounter issues. Here are some common problems and how to troubleshoot them:
Syntax errors
Syntax errors are one of the most common reasons for system malfunction in Flink SQL queries. To avoid them, the user should pay close attention to their queries for typos or incorrect syntax. Flink gives error messages and logs to pinpoint the exact location of the error.
Data inconsistency
Data inconsistency occurs due to network issues, data corruption, and incorrect data transformation. Troubleshooting requires validating data sources and processing logic. Moreover, users should look for any data anomaly or unexpected behavior in the streaming pipeline. The user can employ Flink’s in-built monitoring and logging capabilities to trace the data flow and identify potential issues.
Memory and resource management
Memory and resource management are essential to maintain the stability and performance of Flink SQL applications. To troubleshoot memory and resource issues, monitor resource usage metrics such as CPU utilization, memory consumption, and network traffic. Moreover, optimizing Flink SQL queries can minimize resource usage and maximize efficiency. Scaling vertically and horizontally can also handle workloads effectively.
Error handling
Error handling is important to ensure the reliability and fault tolerance of Flink SQL applications. Implement robust error-handling mechanisms such as retries, error logging, and fallback strategies. Monitor error logs and metrics to identify recurring errors and address them proactively.
[CTA_MODULE]
The Future with Flink SQL
Apache Paimon is a project that aims to enhance Flink SQL capabilities with advanced analytics such as event pattern detection and graph processing. Moreover, developers can perform advanced analytical tasks beyond simple, traditional SQL queries. This allows organizations to uncover hidden patterns and insights in the data.
Flink SQL can also integrate with popular data lakehouse platforms, such as Apache Iceberg and Delta Lake, through standardized connectors and APIs. This integration allows organizations to query and analyze data stored in their data lakehouse without needing complex data movement or transformation processes.
You can also use Flink SQL standard Kafka connectors to integrate with Redpanda - a cutting-edge streaming data platform for real-time use cases. Redpanda for event sourcing and Flink SQL for stream processing make a powerful, easy-to-use duo to build streaming applications for all modern, latency-sensitive use cases.
As the data landscape continues to evolve, Flink SQL will undoubtedly play a crucial role in driving innovation and enabling organizations to unlock the full potential of their data.
[CTA_MODULE]
Conclusion
Flink and its component, Flink SQL, are among the top solutions for real-time stream processing and analytics. Its advanced features and ongoing development have significantly simplified complex data processing tasks.
Redpanda (a drop-in Kafka replacement) for data ingestion and Flink for data processing is currently the best combination for stream processing at scale. With both, you can revolutionize how your organization handles data, bringing even more performance, reliability, and cost-efficiency to your stream processing.