

CDC (change data capture)—Approaches, architectures, and best practices











CDC (change data capture)
Organizations often use multiple systems to execute various business operations. Ensuring the data in all these systems remain consistent with the central transactional database is critical for making quick and accurate business decisions.
CDC (Change data capture) helps organizations maintain data integrity across systems by synchronizing changes made to online transaction processing (OLTP) databases. Changes are propagated as events across downstream systems in real time.
This article introduces the concept of change data capture, the various architectures used in implementing it, and the pros and cons of such architectures.
Summary of key CDC (Change data capture) concepts
Understanding CDC
Change data capture refers to mechanisms that propagate data changes in an OLTP database as events to various destination systems like cache indexes, data lakes, warehouses, or another relational database. A change in data occurs in a database through INSERT, UPDATE, or DELETE operation. Change data capture runs the same operations or brings the same effect in the destination database as and when the change happens.
In most cases, the source database is relational since CDC is often used to synchronize data between a transactional database and other downstream systems. However, the concept of CDC can apply to any source system, whether NoSQL or flat file storage.
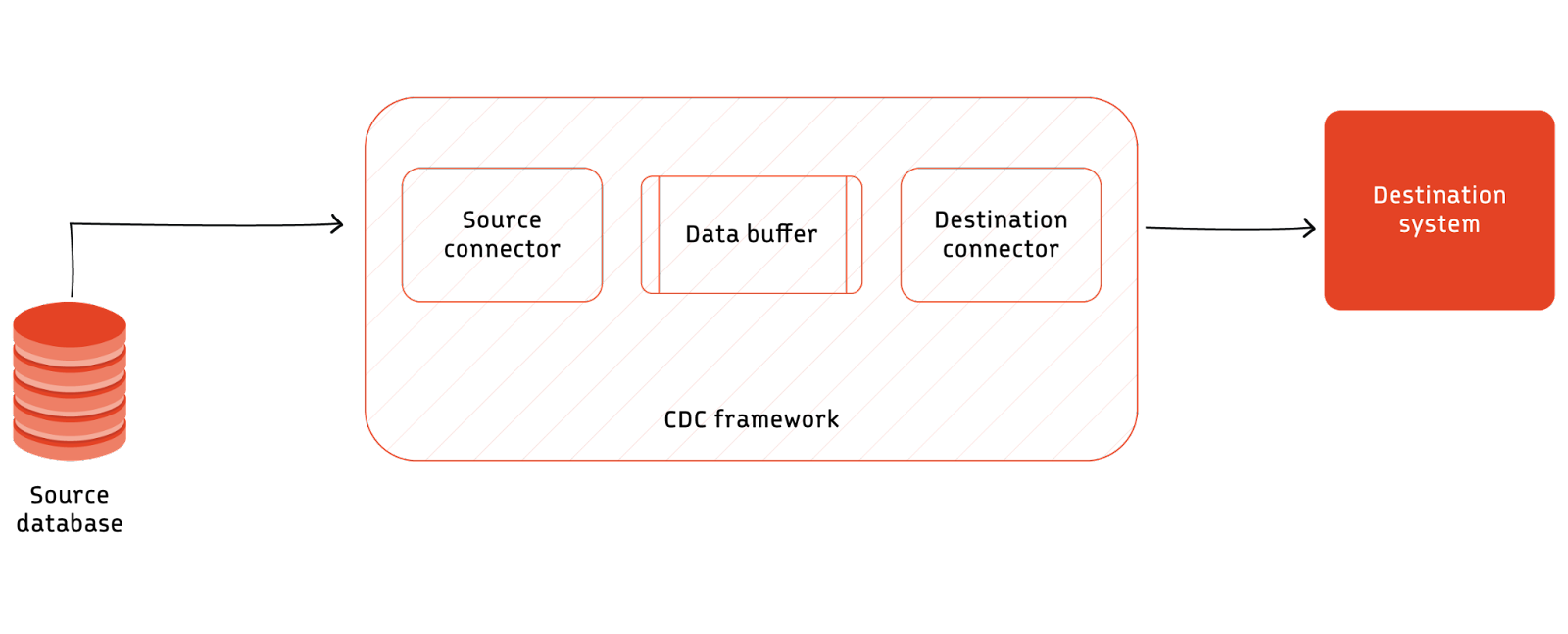
A typical CDC workflow contains a source database, a CDC framework, and a destination system. The CDC framework relies on the source database’s features or active data extraction mechanism to ensure seamless data flow between the source and destination system. Its implementation usually requires decoupling the source and destination system to adjust to the varying speed of changes at the origin database.
Practical applications of CDC
Typical use cases that benefit from CDC implementation are listed below.
Data replication between databases
There are many use cases within an organization where data has to be replicated between databases. For example, while building analytics platforms, data from transactional databases must be copied to a data warehouse so that analytics can run without affecting the transactional database.
On-premise to cloud data migration
The advent of cloud computing platforms like AWS, Azure, and GCP has changed how organizations approach their technology landscape. Even the organizations with the most strict data security protocols now do not hesitate to move parts of their data processing to the cloud. In such hybrid cloud setups, having the same copy of data in cloud systems and on-premise systems is important. Change data capture helps accomplish this in a real-time manner. It is also used in multi-cloud setups where organizations use two cloud providers to cover a single point of failure.
Microservice data integration
Organizations that rely on microservice integration split their core functionalities into several domains that act independently based on events. In such architectures, one needs to synchronize data between all the domains to ensure no conflicts between the platforms. For example, an e-commerce business that relies on microservices architecture may have many data systems like inventory, order management, catalog, etc. Syncing data across these platforms is important to avoid conflicts in their responses.
Maintaining caches and indexes
Large IT systems often depend on caches and indexes outside the database to improve the performance of their services. A typical example is caching API responses in the case of static systems. In such cases, there is a need to invalidate or update the cache whenever the underlying data changes. Change data capture helps to do this in real time.
Implementing real-time reports and analytics
CDC can help in generating reports and aggregated metrics in real time. This involves setting up a change data capture process to send all changes happening in source databases, run column-level transformations, and write it into another database or reporting framework that displays it to the user. Since no batch-based ETL process is involved, this will be much faster.
Maintaining audit logs for compliance
Domains with high compliance requirements like banking, healthcare, etc, often need every data change to be recorded as separate events that can later be verified. CDC provides a quick way to implement such audit logs. In this scenario, the change data capture streams all the change events to a separate database or log files that manage the audit log.
[CTA_MODULE]
Push-based CDC implementation
Change data capture implementation patterns differ based on the extent of source database involvement in sending data to the CDC framework.
In the case of push-based CDC, the source database does most of the work. It pushes data to the CDC framework, which manages the transfer to the destination database. Push-based CDC relies on the source database to initiate the data capture process.
Trigger-based CDC
Trigger-based CDC is an example of push-based CDC. A trigger is a stored procedure that can be configured to execute whenever a database change occurs. You can configure triggers to run when a specific column changes. The triggers inform the CDC framework of the changes happening in the source database. The advantage of trigger-based CDC is that it relieves the CDC framework of detecting the changes in the source database.
Even though trigger-based CDC is simple to implement, they are not the best alternative from the database performance point of view. The write performance of the source database gets affected when there are too many triggers. Another negative aspect is that creating a trigger requires running a schema change operation, which may not be preferred in some cases.
Pull-based CDC implementation
In the case of pull-based CDC, the framework is responsible for identifying the changes happening in the source database and pushing it to the destination database. Here, the source database’s involvement is far less than in pull-based CDC. The source database exposes a mechanism through which the CDC framework can access its internals. CDC based on binary logs and queries are examples of pull-based CDC.
Query-based CDC
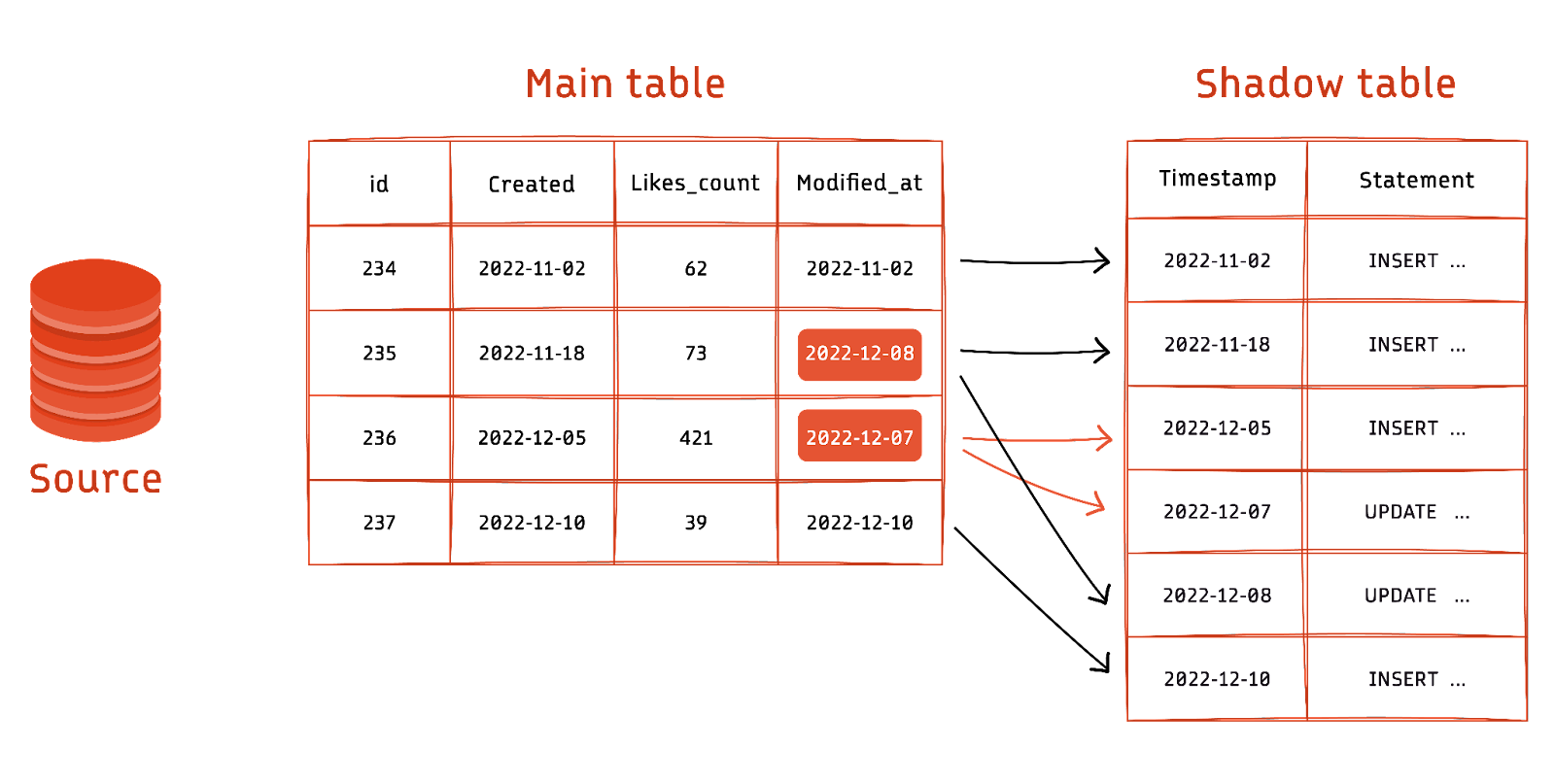
In query-based change data capture, the CDC framework uses SELECT statements to identify if there has been a change in data. The source table has a last modified time stamp column to do this effectively. The CDC framework continuously polls the source database and extracts all the data rows that changed since its previous fetch. Query-based CDC is simple to implement but requires a table schema change to include a timestamp column if it is not present in the original table.
Query-based CDC also causes a performance drop in the source database because of the frequent read operations that it executes. Handling delete operations in a query-based CDC requires complex queries and is often not worth the performance impact.
Log-based CDC
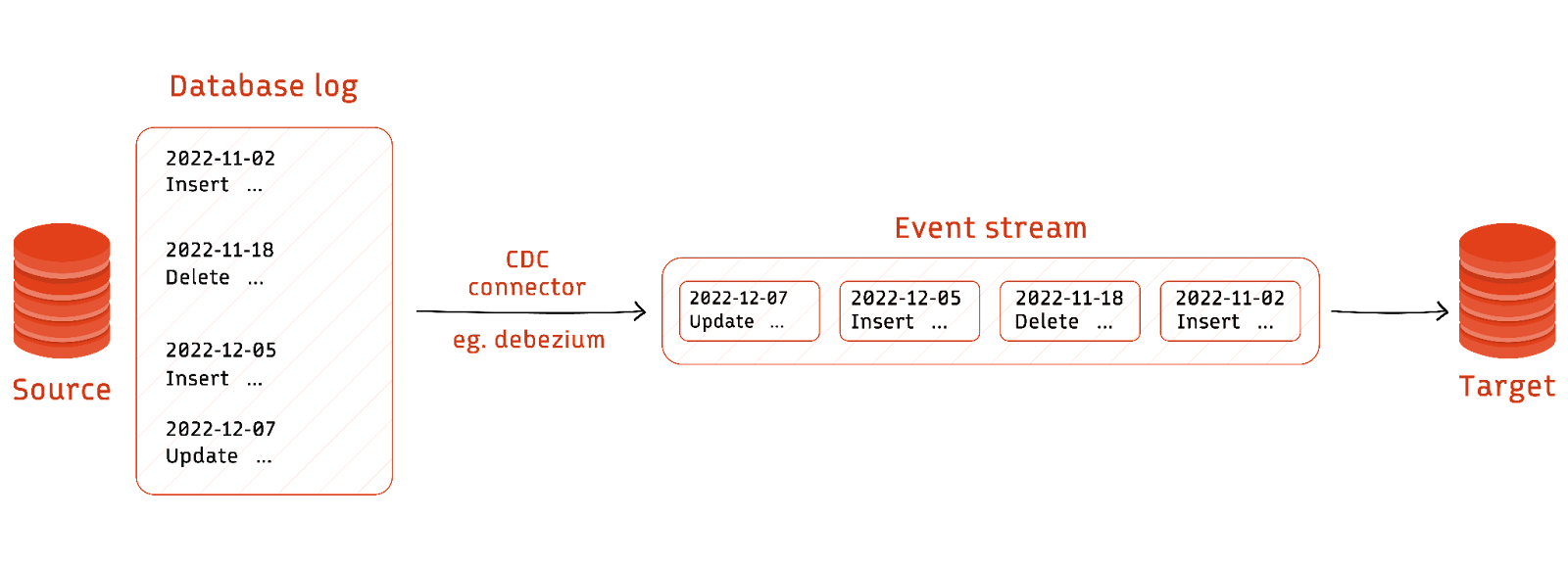
Most databases use a write-ahead log that stores all the events happening in a database to aid backup and data replication. The write-ahead log contains all details regarding INSERT, UPDATE, and DELETE operations. The logs can be proprietary or human-readable, depending on the source database. Parsing the binary log helps a third-party application that needs data replication to detect all the changes happening in the source database. The log helps replicate applications to extract data from the source database without putting pressure on the source. Even though there is a performance impact while enabling the logs, it is far lower than query-based or trigger-based CDC.
Log-based CDC is the best approach to processing overhead on the source database. However, it does not have the standardization that is found in the case of trigger and query-based CDCs. This is because write-ahead logs are closely coupled to the storage architecture and do not follow any standard format like a SQL query or TRIGGER DML.
Hence, log-based CDC implementations require third-party CDC tools to parse the logs and get the changes. The tools convert the changed data into events and use event-streaming services like Redpanda to push the event stream to the target system.
Reference architecture for CDC
On a high level, change data capture implementation contains three main components.
- Source database connector
- Data buffer or queue
- Destination system connector
The source database connector pushes or pulls data from the source database to the data buffer. In the case of push-based CDC, this connector is tightly coupled to the source database. In the case of pull-based CDC, the connector is generally part of the CDC framework itself.
The data buffer helps the CDC framework to store the data from the source database temporarily. The buffer can be an in-memory queue or a completely isolated distributed streaming platform. This buffer helps CDC frameworks manage the incoming data's flow rate changes. In case of spikes, the queue helps to scale processing.
The destination system connector subscribes to the data buffer, runs any transformations required, and writes it into the destination system. The destination system can be another database, flat file storage, or even the API of a third-party system.
Implementing a custom change data capture system based on the above architecture components looks as below.
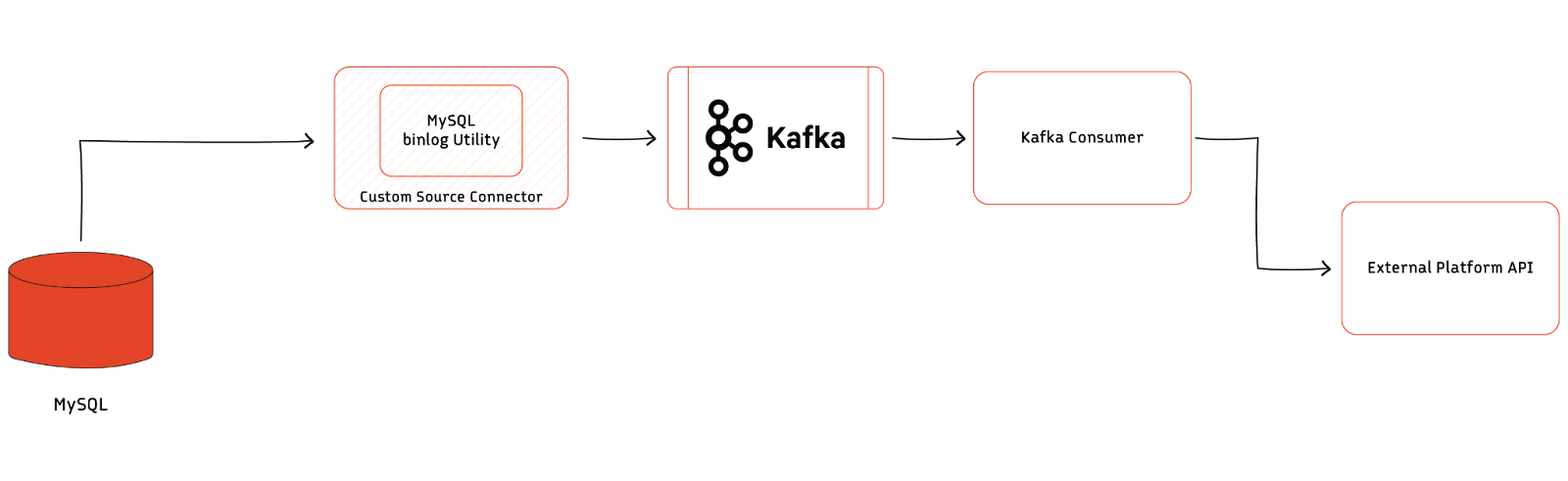
The above diagram shows change data capture implemented in MySQL using a log-capturing approach with Apache Kafka® acting as the buffer. The captured data is then pushed to the API exposed by an external platform. The MySQL bin log connector is a critical part of this implementation. Developers can implement this as a custom module using available utilities like mysqlbinlog or open source connectors.
The CDC implementation with Redpanda is similar.

The above diagram shows the change data capture implemented in PostgreSQL using a log-capturing approach with Redpanda as the buffer. The Postgres database is the data source from which we stream changes. Debezium is the source database connector that establishes a connection with the database, monitors changes, and passes them on to the respective Redpanda topics. Redpanda acts as the data buffer. Various clients and consumers connect and receive the streaming data changes directly from Redpanda.
[CTA_MODULE]
CDC with Redpanda Connect
The reference architecture above shows Debezium as the CDC connector, but it is not the only option. Redpanda Connect provides its own native CDC input connectors, built from the ground up in Go and optimized for containerized deployments.
These connectors ship as a single binary with no JVM dependency. This means lower memory overhead, faster startup times, and simpler operational management compared to Java-based CDC frameworks.
Redpanda Connect currently supports eight certified CDC inputs:
- PostgreSQL CDC: postgres_cdc
- MySQL CDC: mysql_cdc
- MongoDB CDC: mongodb_cdc
- Microsoft SQL Server CDC: microsoft_sql_server_cdc
- Oracle Database CDC: oracledb_cdc
- Amazon DynamoDB CDC: aws_dynamodb_cdc
- TigerBeetle CDC: tigerbeetle_cdc
- Google Cloud Spanner CDC: gcp_spanner_cdc
The most recent additions — Microsoft SQL Server, Oracle, Amazon DynamoDB, and TigerBeetle — expand coverage into enterprise relational databases, managed NoSQL services, and purpose-built financial transaction stores. Every connector carries a certified status, meaning it is production-ready and supported in both Redpanda Cloud and self-managed environments.
This is worth comparing to Debezium, the most widely adopted open-source CDC framework. Debezium supports connectors for MongoDB, MySQL, PostgreSQL, SQL Server, Oracle, Db2, Cassandra, Vitess, Spanner, and Informix, among others.
However, Debezium runs on the JVM and typically requires Kafka Connect as its runtime, which adds infrastructure complexity. Redpanda Connect CDC connectors run as part of the Redpanda Connect pipeline — no separate Connect cluster, no JVM tuning, no additional orchestration layer.
Redpanda Connect also covers databases that Debezium does not. Amazon DynamoDB and TigerBeetle CDC inputs are unique to Redpanda Connect, giving teams a native CDC path for DynamoDB streams and TigerBeetle's financial transaction engine without building custom consumers.
Combined with the broader Redpanda Connect components catalog of over 300 connectors, these CDC inputs slot into larger data pipelines that include transformations, enrichments, and routing — all within a single deployment artifact.
Best practices while setting up CDC
Setting up a change data capture pipeline requires considering several factors that affect implementation success. The following section details some best practices while setting up the CDC pipeline.
Choose the right CDC approach
Push vs. pull goes a long way in ensuring the best performance. A trigger-based CDC approach is the easiest to implement if your use case involves a database for which transactional write performance is not critical. It relieves the CDC framework of detecting the changes in the source database. In contrast, log-based CDC is the way to go for databases exposed to customers and in a critical path where write performance is very important.
In the case of pull-based CDC setups, choosing the log-based CDC is always better. The only advantage of query-based CDC is the standardization it offers because of the use of standard SQL statements to identify database changes. If one deals with a database where log-based change data capture is challenging to implement, then a query-based one can be considered. Such situations arise when there is a lack of connector support for the source database or when one is using a non-popular legacy database.
Choose the right technology
Change data capture is not a new field, but its applications have increased now because of the data-first nature of modern businesses. Since it has been there for a long time, many matured tools exist to implement change data capture. One should always try to take advantage of mature tools rather than reinventing the wheel.
Most CDC setups require some transformation before pushing data to the destination database. It is best to avoid implementing complex transformations in trigger-based CDC pipelines since it would add additional load to the source database and cause issues. Having the buffer in the middle mitigates this problem. Use real-time processing technologies like Redpanda for real-time data processing in such cases.
[CTA_MODULE]
Conclusion
CDC (Change data capture) helps to synchronize real-time changes happening in a database with other systems. It is used in several applications like data replication, microservice integration, cache invalidation, and cloud migration.
Typical CDC implementations follow a pull-based or a push-based approach. The ideal mode of implementing CDC is to use a log-based replication connection for the source database. If such an implementation is impractical, one can use a trigger-based or query-based implementation, resulting in a source database performance trade-off.
[CTA_MODULE]