

Data streaming technologies: An overview











Data streaming technologies
In response to the ever-changing requirements of real-time analytics, data streaming tools have become an integral part of data engineering. Data streaming empowers the immediate processing and transmission of data, though it comes with its own challenges, such as latency, scalability, and fault tolerance. Various data streaming technologies employ distinct strategies to address these challenges.
This article discusses leading data streaming technologies, examines their approaches to data engineering, and assesses their role in a data streaming pipeline.
Summary of key data streaming concepts
The rest of this article explores the differences between these data streaming technologies so you can choose the best one for your requirements. Please see the previous chapters in the guide on streaming data pipeline and stream processing fundamentals.
[CTA_MODULE]
Data streaming technologies—architectural approaches
The four technologies serve distinct roles and take distinct approaches to data streaming.
Publish-subscribe
Kafka and Redpanda are data stream ingestion technologies. They stream data from source to target using a publish-subscribe model. A data source can be anything like IoT devices, application logs, server telemetry, business events, etc. A target is usually a stream processing technology like Spark Streaming or Flink or a data storage layer.
Kafka implements data streaming using a distributed publish-subscribe system. Its working model consists of producers, consumers, topics, and a set of brokers deployed as a cluster. The brokers serve as intermediaries between the producers and consumers. Producers publish the messages to topics. Consumers subscribe to topics to receive messages. Kafka’s distributed architecture partitions topics across multiple brokers, which enables parallel processing and horizontal scalability.

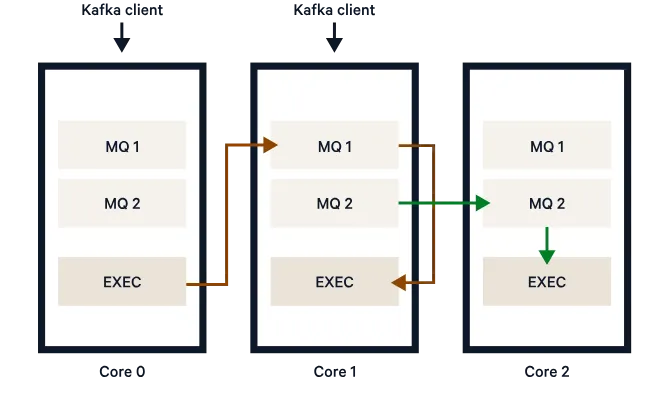
Redpanda also implements pub-sub using brokers, topics, producers, and consumers. The components of Redpanda play the same role as they do for Kafka, but with several additional performance benefits. Redpanda brokers’ thread per core architecture allows them to pin each application thread to a single CPU core. This improves performance and responsiveness by eliminating the overhead of thread management and context switching required with the pub-sub approach of Kafka.
Redpanda brokers leverage memory-mapped files for efficient data access. They also use a streamlined replication protocol, based on the Raft consensus algorithm, for faster data propagation, ensuring data is replicated consistently across a cluster of nodes. Topics are also partitioned utilizing a modern hashing algorithm for even data distribution for improved load balancing and scalability.
Micro-batch processing
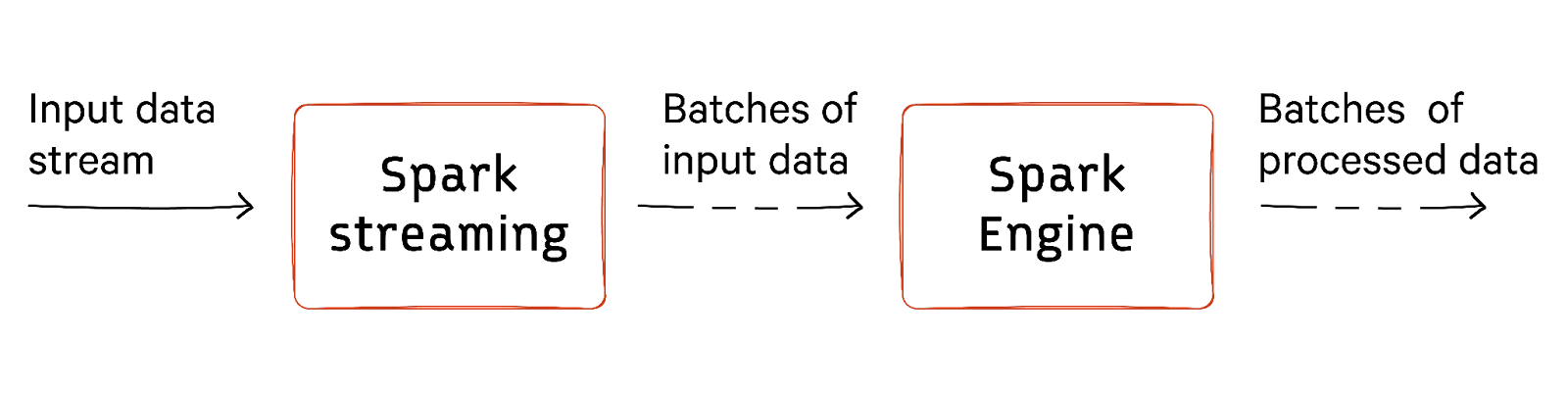
Spark Streaming processes data before moving it on for further analytics. It leverages a micro-batch processing approach that divides continuous data streams into smaller, more manageable chunks called discretized streams or DStreams. DStreams are further processed as a series of mini-batches, which allows Spark Streaming to utilize Spark’s underlying batch processing engine for stream processing tasks.
The key components of Spark Streaming include Receivers, DStreams, Jobs, and JobSchedulers.
The Receivers are responsible for receiving data from various sources and converting it into Spark’s internal format. Jobs are the execution of the stream processing task. The Job Scheduler is responsible for scheduling, executing, and coordinating jobs on worker nodes.
Task distribution
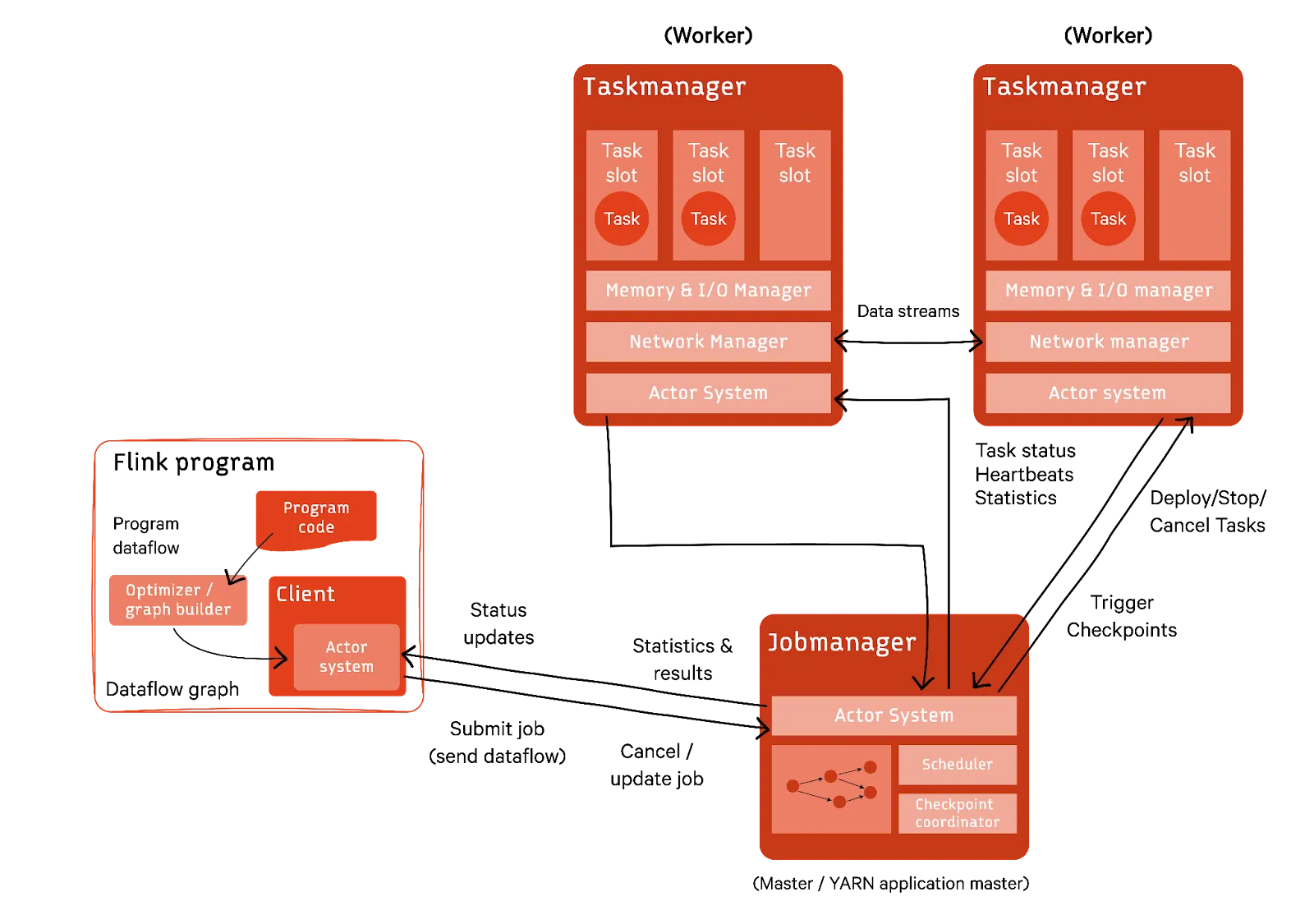
Flink also fits into the data stream processing layer. It implements data stream processing using two primary components - the Job Manager and Task Managers.
The Job Manager acts as a central coordinator, responsible for managing tasks, distributing them among the Task Managers, and overseeing checkpoints and recovery mechanisms. The Task Managers are the worker nodes that execute the tasks assigned by the Job Manager. Each Task Manager consists of multiple slots, each with the capability to perform a single task.
Flink clients prepare and send data streams to the Job Manager. They can disconnect or remain connected to receive progress reports. You can launch Job and Task managers as standalone clusters, in containers, or under resource frameworks.
[CTA_MODULE]
Data streaming technologies—other key differences
Next, let's explore differences relevant to performance.
Compression
All four technologies use compression to allow the data to have a smaller memory footprint without sacrificing the essential information it contains. This allows for storage space to be saved, reduces transmission time, and also improves performance.
Spark Streaming applies compression at the data stream level and offers several types of compression, including Snappy, LZ4, and ZSTD. Flink also offers data compression at the data stream level. It offers multiple compression options, including Snappy, gzip, and LZF. Kafka offers data compression, but instead of the data stream level, it offers it at the topic level or per-message. It offers multiple compression options, including Snappy, gzip, LZ4, and ZSTD.
Redpanda also offers several data compression options like Snappy, LZ4, and ZSTD. In contrast to other data streaming technologies, Redpanda
- Applies real-time data compression and compresses the data as it is ingested.
- Provides a multi-level compression feature that allows for granular control over the compression settings.
- Offers higher compression ratios with ZSTD, more affordably, by using fewer CPUs than Kafka and Spark Streaming.
This can significantly improve resource allocation and also lead to cost savings.
Please see the example below to see how Redpanda can achieve higher levels of compression with ZSTD while using fewer computing resources than Kafka. The code block below illustrates how Kafka achieves compression with ZSTD.
import zstandard as zstd
# Sample message
message = "The sky is blue today."
# Compress message using Kafka's Zstandard implementation
kafka_compressed = zstd.compress(message.encode('utf-8'), level=3)
# Calculate compression ratio
kafka_ratio = len(message) / len(kafka_compressed)
print("Kafka compression ratio:", kafka_ratio)
# Measure CPU usage during compression
cpu_usage_kafka = measure_cpu_usage(zstd.compress, message.encode('utf-8'), level=3)
print("Kafka CPU usage:", cpu_usage_kafka)Kafka compression ratio: 3.4 Kafka CPU usage: 15%The next code block illustrates how Redpanda achieves compression with ZSTD.
import zstandard as zstd
# Sample message
message = "The sky is blue today."
# Sample message for Redpanda's Zstandard compression
redpanda_compressed = zstd.compress(message.encode('utf-8'), level=3)
# Calculate compression ratio
redpanda_ratio = len(message) / len(redpanda_compressed)
print("Redpanda compression ratio:", redpanda_ratio)
# Measure CPU usage during compression
cpu_usage_redpanda = measure_cpu_usage(zstd.compress, message.encode('utf-8'), level=3)
print("Redpanda CPU usage:", cpu_usage_redpanda)Comparative output
Redpanda compression ratio: 3.5 Redpanda CPU usage: 10%For this example, the CPU usage difference is only 5%, but it can be more for real-world scenarios, depending on the data and the compression algorithm applied. Even with just a 5% difference, that could be a tremendous cost savings for an organization, especially when the organizations are responsible for managing large amounts of data.
Scaling
Two main approaches to scaling are horizontal and vertical. Horizontal scaling adds machines or resources to the existing infrastructure to distribute workload. Vertical scaling enhances the capabilities of individual components or nodes in the system to handle higher data processing demands.
Spark Streaming scales well horizontally and vertically, but its primary strength is scaling horizontally. This allows it to handle variable and increasing data volumes, making it suitable for large-scale stream processing applications.
Flink also adds more nodes to distribute processing tasks and handles large data loads efficiently. However, Flink’s numerous features require careful configuration and monitoring for optimal performance at scale. For example, if you are using it to stream and process large data volumes, you will need to carefully configure many tasks and subtasks, as well as the memory and CPU resources allocated to each task.
Kafka’s distributed architecture enables horizontal scalability to handle increasing data volume. However, it uses a log-based storage approach, which appends messages to immutable commit logs. This approach requires regular maintenance and data cleanup at scale. As data accumulates over time, the log size can grow significantly, potentially impacting storage costs and performance. Regular maintenance tasks, such as monitoring log sizes, adjusting retention policies, and performing log compaction, become essential at scale, creating challenges.
Redpanda takes a different approach to logging than Kafka, resulting in improved scale performance. Redpanda uses a log-structured merge tree (LSM tree) approach, a data structure optimized for high-volume data ingestion and retrieval. LSM trees work by merging smaller segments of data into larger segments, which improves performance over time. Redpanda also includes a data-skipping feature, allowing efficient and targeted access to specific data segments. This is useful for applications that need to quickly retrieve specific data values, such as real-time analytics or machine learning applications.
Reliability
Reliability refers to the tool’s ability to recover from failure and ensure data integrity is maintained and data is available. Data engineers typically look for several essential traits in data streaming tools, such as fault tolerance, durability, and effective monitoring and alerting.
Spark Streaming’s fault tolerance mechanisms—checkpointing and replay, enable reliable data processing—even in the face of failure. It achieves reliable data processing by checkpointing the application state to durable storage and replaying lost or corrupted data.
Flink addresses reliability by periodically checkpointing the state to durable storage, which guarantees exactly-once semantics for all messages. Additionally, it uses backpressure to prevent data loss effectively.
Kafka also offers three delivery guarantees for reliable data processing: at least once, exactly once, and at most once.
- At-least-once guarantees that each message is delivered at least once but may be delivered multiple times.
- Exactly-once guarantees that each message is delivered exactly once.
- At-most-once guarantees that each message is delivered at most once.
These guarantees ensure that each message is delivered and processed as intended, which prevents data loss or duplication. The choice of each guarantee should be based on the performance needs of your application. Different delivery guarantees offer different trade-offs between performance and reliability.
Redpanda has its own methods of providing reliability, including a self-healing mechanism. This mechanism automatically detects and recovers from failures and ensures Redpanda can continue to operate even if there is a hardware failure, network outage, or software bug.
[CTA_MODULE]
Summary of data streaming technologies
When you implement a data streaming pipeline, you have to pick and choose different technologies to suit your use case.
It is important to note that Redpanda is a drop-in Kafka replacement that can run with any Kafka client. It is designed to maximize the hardware it is deployed on and deliver messages from producer to consumer as fast as possible. To this end, Redpanda's processes are architected to better use modern systems, with more CPU cores, faster networks, and faster storage like NVMe disks. This has led to consistently better benchmark performance over Kafka.
Redpanda can act as a data source for both Spark Streaming and Flink—ingesting data and passing it onto Flink or Spark Streaming for further transformation. Redpanda, as an upstream data source, provides a better developer experience as it is a fully managed deployment, provides cost-effective data storage, and uses fewer resources than other data ingestion platforms like Kafka.
Learn more about Kafka limitations and alternatives in our Kafka alternatives guide.
[CTA_MODULE]