

Data pipeline architecture—Principles, patterns, and key considerations











Data pipeline architecture
The data engineering lifecycle defines the various stages data must go through to be useful—such as generation, ingestion, processing, storage, and consumption. A data pipeline is an automated implementation of the entire data engineering lifecycle.
It facilitates continuous data processing for fast data consumption by applications like machine learning, BI tools, and real-time data analytics. Each pipeline component performs one stage of the cycle and creates an output that is automatically passed to the next component.
A data pipeline architecture is a blueprint of the pipeline independent of specific technologies or implementations. Having a well-architected data pipeline allows data engineers to define, operate, and monitor the entire data engineering lifecycle. They can track the performance of each component and make controlled changes to any stage in the pipeline without impacting the interface with the previous and subsequent stages. Data flows through the cycle continuously and seamlessly over a long period.
This article explores data pipeline architecture principles and popular patterns for different use cases. We also look at different factors that determine data pipeline design choices.
Summary of key concepts
Principles in data pipeline architecture design
A data pipeline architect should keep some basic principles in mind while designing any data pipeline. Data pipelines deal with large amounts of data, and some attributes below are essential for any component that processes data at scale.
Loose coupling
Each component of the data pipeline should be independent, communicating through well-defined interfaces. This allows individual components to be updated or changed at will without affecting the rest of the pipeline.
Scalability
It is possible that data flows vary over time, with large bursts in the number of events occurring during certain events (like festival sales for e-commerce websites, for example). In such cases, rather than over-provisioning the pipeline so that it can handle the higher load at all times, it is more cost-efficient and flexible to give the pipeline the ability to scale itself with increasing and decreasing data flow.
Reliability
The data pipeline is critical when downstream applications consume processed data in near real-time. It should be designed with fallback mechanisms in case of connectivity or component failure to ensure minimal or no data loss while recovering from such scenarios.
Security
With the exponential increase in data available for processing, keeping it secure has become all the more important. Data pipelines have a large attack surface because of all the components involved in processing and transforming data that could be potentially dangerous if accessed by malicious entities. Any data pipeline must be architected with security in mind.
Flexibility
Because of the large scale and vast applications of a data pipeline, it is highly possible that the expectations from the pipeline change over time. It is almost guaranteed that the technologies and implementations of individual components will change. A good data pipeline architecture is flexible, so you can incorporate such changes with minimal impact.
[CTA_MODULE]
Data pipeline architectural patterns
Over time, certain architectural patterns that have proven themselves useful for multiple applications have been given names and can be easily adapted by engineers while creating their own data pipelines. Some of them are listed below, along with scenarios where they can be used in your data pipelines.
Data warehouse
The data warehouse architecture consists of a central data hub where data is stored and accessed by downstream analytics systems. In general, the data warehouse is characterized by strict structure and formatting of data so that it can be easily accessed and presented.
A typical data warehouse pipeline consists of the following stages:
- Extraction - in this stage, data is extracted, or pulled, from the source systems
- Transformation - the extracted data is transformed to match the structure of the data to what the warehouse expects
- Loading - transformed data is pushed into the data warehouse storage system
Downstream applications are aware of the structure of the data in the warehouse and can access it at will.
In older data warehouses, the extract-transform-load (ETL) system was external to the actual data warehouse and ran as a separate component. However, in modern cloud-based data warehouses, it is sometimes preferable to transform the data within the data warehouse itself, since the warehouse is located in the cloud and has a large amount of computational resources. Such data warehouses are called ELT warehouses.

Data warehouses are useful in scenarios where downstream applications rely on a highly structured data format, such as analytics and reporting. ELT warehouses are increasingly valuable for modern-day applications that handle event streams because of their ability to collect multiple events in the staging area and then load and transform them together.
Data lake
Data lakes are a more flexible data pipeline architecture that relies on cloud-based infrastructure to be cost-effective while enabling a huge variety of data processing use cases. It does not enforce structure on data stored within it, accepting data from a large variety of sources and storing it as is.
All the transformations and processing are done on-demand based on the downstream application's needs through data processing clusters running frameworks like MapReduce or Spark.
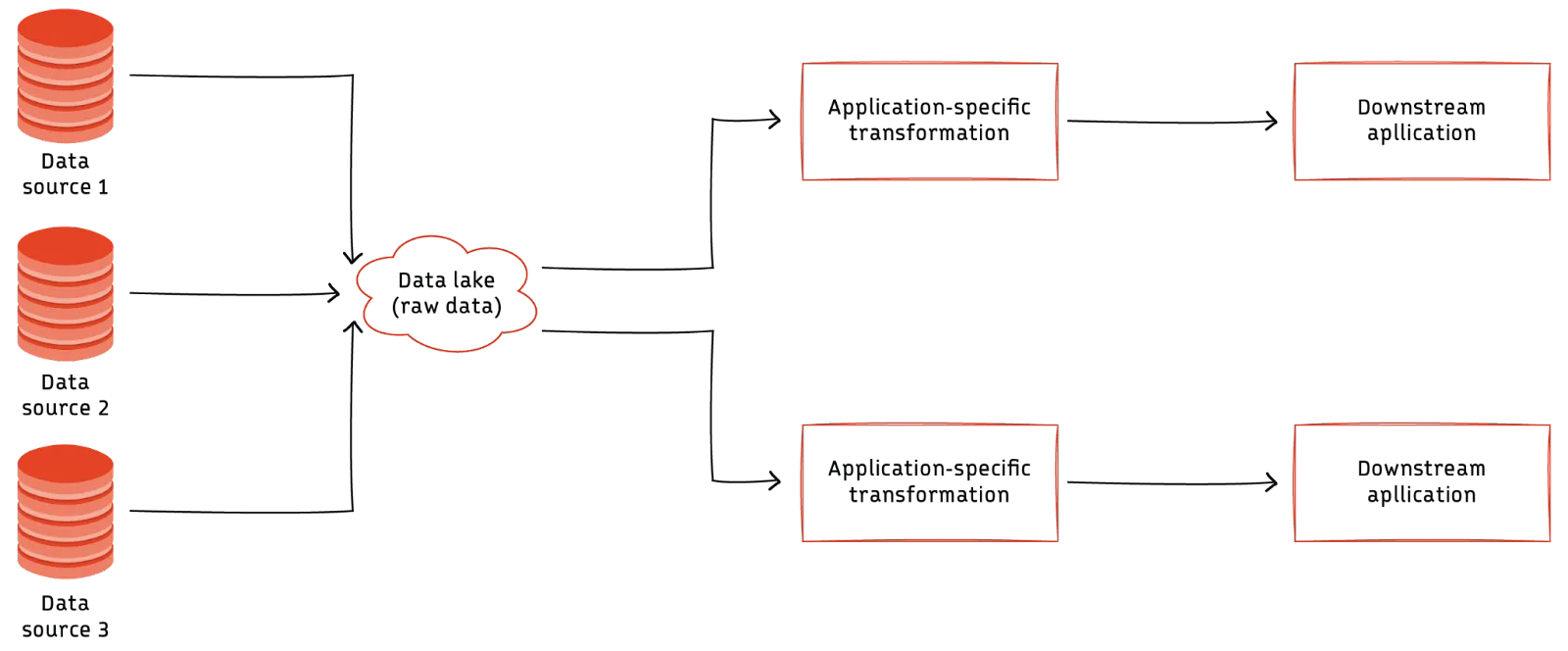
Data lake pipelines are useful for applications that process data in multiple ways and it is not efficient to add structure to the data up-front. While these pipelines are very flexible, they can become inefficient and expensive if not managed properly. Data lakes are used by highly data-intensive companies that use processed data for many machine learning and analytics use cases.
Dataflow pipeline
Dataflow pipelines are data pipelines for data streaming applications. They typically use a data streaming platform like Kafka or Redpanda as the data transfer layer, with data being ingested as small messages.
Transformations are also done using data streams- each incoming message is passed through a series of data streams (or Kafka topics) while being transformed each time. Downstream applications directly listen to output streams for individual transformed messages or access batches in the form of aggregations.
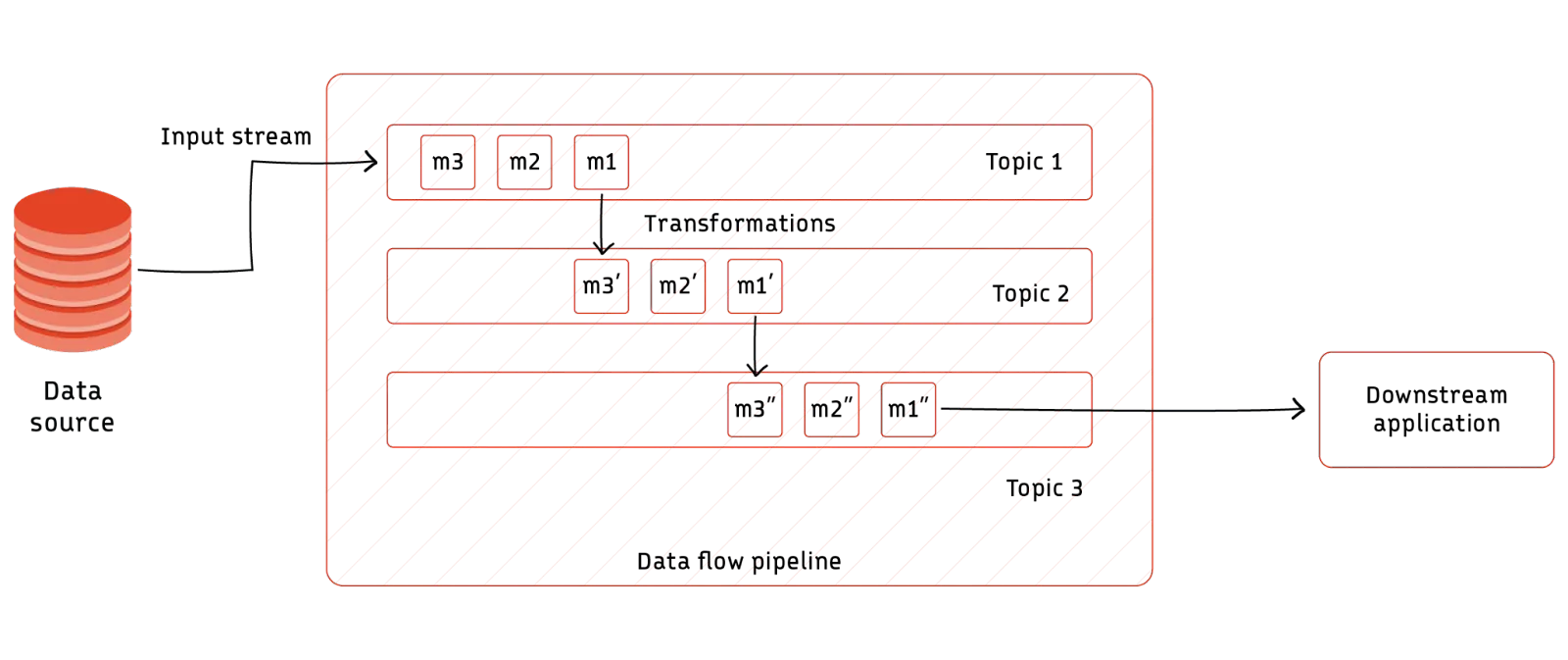
A good example of a technology we can use to create a dataflow pipeline is Apache Flink®. Using Flink, we can create data streams, and then use transformation functions to create derived streams from our original stream.
Code example
A simple example of how Flink can be used to create and derive streams is below. We create a stream of string messages and then use a transformation function to change the data type of the messages to integer:
DataStream<String> input = ...;
DataStream<Integer> parsed = input.map(new MapFunction<String, Integer>() {
@Override
public Integer map(String value) {
return Integer.parseInt(value);
}
});Many more such transformations are possible—we can even use join functions to merge messages from multiple streams into the output stream.
Tools like Flink can help create powerful streaming data pipelines that transform and deliver events to downstream applications as they occur.
IoT data pipeline
With the increasing number of IoT devices being adopted for many business and consumer requirements, data pipelines for IoT have become more and more popular. These pipelines usually consist of one additional component called an IoT gateway.
IoT devices tend to have less computing power and memory. An IoT gateway is a common connection point that IoT devices can connect to and send data without doing much processing on it. The gateway has more sophisticated business logic for filtering and routing the data correctly, and usually, a single gateway collects data from multiple devices.
Once the data arrives at the gateway, it is usually passed to a dataflow or other data streaming pipeline for processing before being sent to various downstream applications.

Because of IoT devices' fluctuating connectivity and low capabilities, an IoT pipeline needs to be much more resilient to operational failures. Hence, it is essential to have a powerful gateway. IoT pipelines are useful in applications such as home monitoring systems, vehicle connectivity systems, scientific data collection from remote sensors, etc.
[CTA_MODULE]
Factors impacting data pipeline architecture choice
As data processing becomes more commonplace and different use cases arise, new types of data pipeline architecture, other than those mentioned above, are coming to the fore. Some examples are:
- Data mesh
- Data fabric
- Metadata-first architecture
You can choose your data pipeline architecture based on data attributes and application requirements. As long as application functions and requirements do not change, its pipeline architecture will remain consistent. We give some key considerations below.
Data source
The source from which the data flows into the pipeline can be one of many possibilities, including relational database systems like SQL, NoSQL databases like Cassandra, modern systems like IoT swarms, and even something as simple as .csv files. Each data source has distinct behavioral attributes like:
- Amount of time for which it stores data after generation
- How changes to data over time are communicated to the data pipeline by the source system—push vs. pull CDC explained in detail in a later chapter of the guide
- Events that trigger data movement
- Existence of duplicates
Such factors affect the design of the data pipeline architecture.
Ingestion and storage
The amount of data and the way it is ingested into the pipeline determines a lot about the pipeline architecture. For example, some applications stream data continuously to the pipeline, others send data only when events occur, while others transmit data in distinct batches of a particular size. Sometimes, it may be up to the data pipeline to decide the frequency at which it will ingest data from the source, in which case you can make decisions based on the abilities and needs of the downstream application.
The data pipeline also needs to cache data, both during and after processing so that downstream applications can access the processed data. Various storage systems, each with different data access capabilities and performance and reliability guarantees, are available. It is essential to choose the right kind of storage system (or systems) while architecting our data pipeline, as this single component significantly impacts the entire pipeline's performance.
Consumption
Data pipelines serve a variety of applications, including machine learning applications, data analytics, business intelligence tools, and so on. Each of these requires different transformations and has different ways of receiving the data from the pipeline. For example, many machine learning models require large data batches to gain meaningful insight, while business intelligence tools require real-time data.
[CTA_MODULE]
Conclusion
Data pipelines are critical in the modern world of intelligent and self-aware software applications, which depend on near-real-time data analysis at an unbelievable scale. They enable and automate data flow through ingestion, preparation, processing, and storage. Data pipeline architecture is the blueprint behind pipeline design for any application.
As technologies evolve, the specific technologies and components used in a certain pipeline could change many times, but the pipeline architecture may remain constant. Your architecture must be scalable, reliable, secure, and flexible to adapt quickly to future changes. You can choose from several pipeline architecture patterns based on your data source, destination, and processing requirements.
[CTA_MODULE]