

Kafka API—Types, use cases and compatible solutions











Kafka API
In the dynamic world of real-time data streaming, Application Programming Interfaces (APIs) serve as communication endpoints, facilitating seamless interactions between various software applications. Among these, Apache Kafka®’s API stands out, known for its exceptional capabilities in handling real-time data.
This article explores the inner workings of the Kafka API, examining its types, uses in real-world scenarios, and discussing limitations that arise in specific contexts. We then explore how Red Panda, a robust alternative, aims to overcome these limitations and enhance Kafka's performance.
Summary of Kafka API concepts
We will look at the following topics in this article:
| Producer API | Allows applications to send streams of data to topics in the Kafka cluster. |
| Consumer API | Permits applications to read data streams from topics in the Kafka cluster. |
| Streams API | Acts as a stream processor, transforming data streams from input to output topics. |
| Connect API | Enables the development and running of reusable producers or consumers that connect Kafka topics to existing data system applications. |
| Admin API | Supports administrative operations on a Kafka cluster, like creating or deleting topics. |
| Kafka API use cases | Real-time analytics, event sourcing, log aggregation, message queuing, and stream processing. |
| Kafka API compatible alternative | Redpanda streaming data platform. |
Kafka APIs - an overview
The Kafka API is instrumental in providing a programming interface that allows applications to produce, consume, and process streams of records in real time. It serves as a communication point between the Kafka server and its users and handles real-time data feeds with low latency at scale. These attributes make it a tool of choice for use cases involving real-time analytics, event sourcing, and many other data-intensive operations.

There are five main types of Kafka API, each serving a distinct purpose within the Kafka ecosystem.
Producer API
By converting data into a format suitable for the Kafka broker, the Producer API plays a vital role in data ingestion, ensuring that data streams correctly to the desired Kafka topic.
The following Java code demonstrates how the Producer API sends messages to specific Kafka topics.
Consumer API
The Consumer API extracts data from Kafka. You can subscribe to one or more topics and pull data from them into your application. Here is a simple example of a Kafka Consumer API in Java.
This code creates a Kafka consumer that subscribes to a topic named myTopic. It sets up necessary properties, including bootstrap servers, group IDs, and key/value deserializes. Then it enters an infinite loop where it continuously polls for new records from the topic and prints out the offset, key, and value of each record.
[CTA_MODULE]
Streams API
The Streams API performs complex transformations and processes by aggregating data or joining multiple streams. For instance, suppose you have a sales data stream and want to compute the total sales per region in real time. This is a job perfectly suited for Kafka Streams.
In KSQL (Kafka's SQL-like stream processing language), the code might look something like this:
In this example, CREATE STREAM defines a stream of sales data. The CREATE TABLE statement creates a new table aggregating this data by region. The result is updated in real-time as new sales records arrive, thanks to Kafka Streams. This is a simple example, but the Streams API is capable of much more complex processing and transformations.
Connect API
The Connect API serves as a bridge between Kafka and other data systems. It is useful when importing or exporting data between Kafka and external systems like databases, log files, or other message queues.
Let us put this into perspective with a brief example. This can be done using Kafka Connect along with a pre-built connector for your database.
In this Java snippet, we are setting up a JDBC source connector to stream changes from a MySQL database into Kafka. We configure the connector with the necessary properties, such as the JDBC connection URL and the column to use for incrementing offsets (in this case, an 'id' column). We then use Kafka Connect's REST API client to add the connector to our Kafka Connect cluster.
Admin API
The Admin API enables effective management of Kafka. For example, you can use it to:
- Create new topics within a Kafka cluster which can then be used for producing and consuming messages.
- Manage user-level permissions, ensuring secure and controlled access to Kafka resources.
- Inspect cluster configurations for effective monitoring and optimization of Kafka resources.
Here's a simple example of how to create a new topic using the AdminClient API in Java:
In this code snippet, we first create an instance of AdminClient which is configured to connect to a Kafka cluster on localhost:9092. Then, we define a new topic with the name myNewTopic, 1 partition, and a replication factor of 1. Finally, we use the AdminClient instance to create the new topic in the Kafka cluster.
Kafka API use cases
Some use cases for Kafka API include:
Real-time analytics
Kafka API is instrumental in powering real-time analytics in various fields. By consuming data streams through the Consumer API and producing result streams through the Producer API, real-time analytics engines provide insights as events occur, aiding in prompt decision-making.
Event sourcing
Event sourcing is a programming paradigm that saves all changes to the application state as a sequence of events. Kafka APIs enhance system traceability and debugging in event streaming. They handle, store, and process large event streams at scale.
Log aggregation
Log aggregation involves collecting and storing logs from various sources in a centralized location. The Producer API sends logs to Kafka, while the Consumer API consumes these logs. Kafka is a centralized, scalable, and reliable log management solution that aids in monitoring and debugging.
Message queuing
In a microservices architecture, services often need to communicate with each other. Kafka API facilitates such interactions by acting as a message broker. Messages produced by one service are consumed by another, allowing for effective inter-service communication.
Stream processing
The Kafka Streams API is used in applications that require continuous computation and manipulation of data streams, such as real-time data transformation, aggregation, or join operations. You can use them in applications like real-time fraud detection, finance, and live leaderboards in gaming.
[CTA_MODULE]
Limitations of Kafka
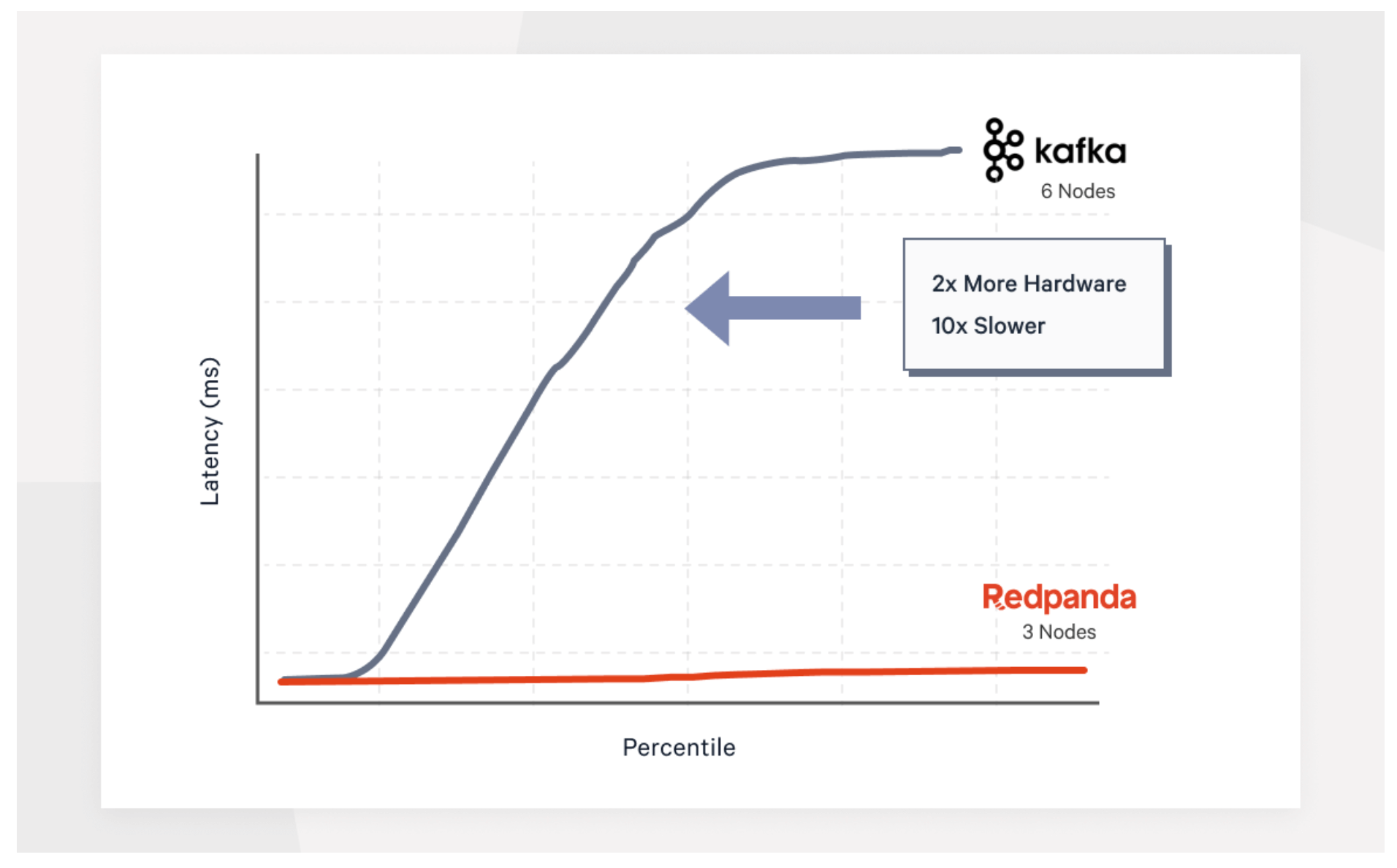
As powerful and versatile as Kafka API is, it isn't without its limitations and challenges. Understanding these issues can provide a more comprehensive perspective on using Kafka in real-world applications:
Dependency on ZooKeeper
Kafka relies heavily on Apache ZooKeeper™ to maintain its cluster state, perform leader elections, and manage topic and ACL metadata. This dependency introduces additional operational complexity and is a potential point of failure.
Data replication delays
Although Kafka provides strong durability guarantees, under heavy load or in the event of network partitions, there can be a noticeable lag in data replication across brokers. This can lead to data inconsistency issues in highly latency-sensitive applications. The reason behind this is that Kafka needs to ensure that data is committed to the leader partition first and then replicated to follower partitions.
If there is a high volume of data to process or if network issues occur, it can take time for all the followers to catch up with the leader. This replication lag can potentially lead to temporary data inconsistency issues in highly latency-sensitive applications, where real-time data consistency across all replicas is crucial.
Complex configuration
Kafka is highly configurable and offers many settings to fine-tune its performance. However, this flexibility often translates into complexity, especially for newcomers. Incorrect configurations can impact the system's efficiency and reliability.
Memory management
Kafka uses the JVM heap space and the OS page cache for buffering messages before they are sent to the consumers. As such, it may not be suitable for systems with limited memory.
Redpanda: a Kafka API-compatible streaming data alternative
A high-performance streaming platform, Redpanda presents an exciting advancement in real-time data processing. By eliminating the dependency on ZooKeeper and introducing a raft-based consensus algorithm, Redpanda offers a simplified, more reliable system. Its architecture is streamlined to reduce potential failure points and improve the system's resilience.
Unlike Kafka, which relies on JVM and OS page caching, Redpanda is written in C++, leading to more efficient hardware usage and better overall performance. This ensures more predictable latencies, an essential factor for real-time applications.
Redpanda further enhances usability by simplifying setup and configuration. It offers a single binary installation with sensible defaults, reducing the burden on users. Its' tune for the hardware approach adapts the performance according to the available resources, providing optimal results without extensive manual tuning.
In addition, Redpanda improves upon Kafka's data replication process. It ensures the data is immediately consistent after being written, eliminating replication lag and providing stronger data guarantees.
Redpanda amplifies the capabilities of Kafka API while alleviating its limitations. It enhances performance, improves ease of setup, and delivers efficient hardware usage - making it a compelling choice for users looking for advanced real-time data streaming solutions.
[CTA_MODULE]
Conclusion
Kafka APIs like Producer, Consumer, Streams, Connect, and Admin APIs have many use cases and applications. However, Kafka's limitations—such as its dependency on ZooKeeper, potential data replication delays, complex configuration, memory management issues, and lack of advanced queuing features—impact usage.
Redpanda overcomes these challenges, offering a more efficient, reliable, and user-friendly alternative. It is compatible with Kafka API so that you can migrate to Redpanda without significant code changes. With a simplified setup process, it significantly reduces operational complexity.
[CTA_MODULE]