

Apache Kafka limitations











Kafka limitations
Data streaming has become an integral part of the modern software stack. Products ranging from multiplayer games to e-commerce websites rely heavily on their data streaming infrastructure to analyze and react to user inputs. Apache Kafka® is a popular data-streaming solution. However, the underlying architecture of Kafka has several limitations and can become increasingly more complex to manage at scale.
Redpanda is a fast-growing data-streaming solution that speaks the same language as Kafka in a more optimized, efficient manner. In this article, we use it as a basis for comparison to highlight Kafka’s limitations. Redpanda is implemented in C++, making it much more performant and cost-efficient than Kafka, which is implemented in Java. It also provides some critical architectural benefits out of the box (that we will cover further down.)
This article takes an in-depth look at the limitations of Kafka and presents an alternative solution for replacing its functionality with a more performing and feature-rich yet fully compatible platform.
Summary of Kafka limitations
Here is a broad overview of the differences between Redpanda and Kafka.
Kafka’s architectural limitations
Redpanda, from the inside out, is architected for efficiency and simplicity, seen not only in the platform's performance but also in the ease of user experience. The entire lifecycle of Redpanda, from installation, configuration, and operation—to later steps like upgrades and failover scenarios, is designed to be more accessible and simpler than Kafka. We will look at some specific examples below.
Single-binary architecture
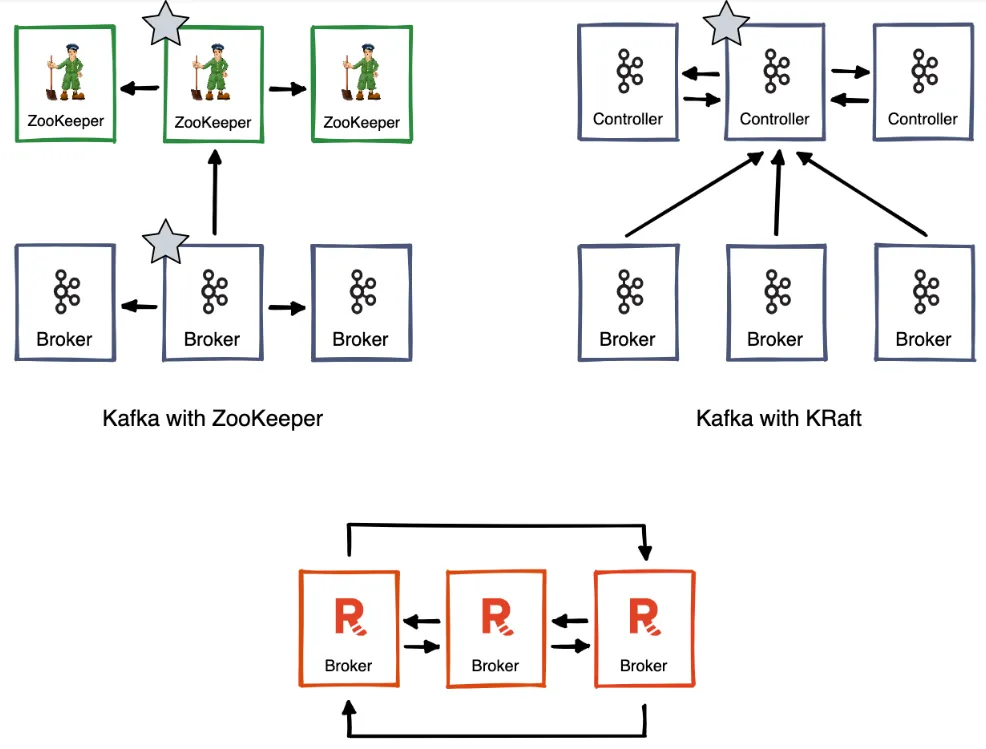
A typical Kafka cluster consists of multiple Kafka brokers, an auxiliary cluster of coordinators like Apache ZooKeeper™ (though this has changed to KRaft with more recent versions), a schema registry, and other services like proxy, connectors, and so on.

In contrast, Redpanda is shipped as a single, fully contained binary that operates all the services listed above. It packages all dependencies in the binary, and installation is as simple as running the binary on a compatible operating system. This makes getting a Redpanda cluster up and running much easier and faster. It also has a host of secondary benefits, such as:
- Easier monitoring through a single cohesive framework with no need to parse and match logs from separate services
- Coherent documentation that is easier to follow since all components are installed via the same binary
- Easier upgrades because we do not need to manage the versioning and compatibility of individual components in the cluster separately
- More resilience, because we only need to plan for the failure of an entire node as opposed to multiple possible errors in each independent service
[CTA_MODULE]
Native coordination using the Raft protocol (no more ZooKeeper)
Redpanda uses the well-known Raft protocol for distributed coordination, consensus, and metadata replication, removing the need for a dedicated external coordinator like ZooKeeper. Recent versions of Kafka (since 3.4.0) also support Raft-based cluster coordination. However, Redpanda has been built using the Raft mechanism from day one, allowing for multiple optimizations and enhancements.
For example, Kafka's Raft implementation (KRaft) marks some brokers explicitly as controllers and others as brokers for managing data. There are different quorum requirements for controllers and brokers. Redpanda, on the other hand, has each node in the cluster automatically configured to use Raft for coordination.
Some other improvements in Redpanda's implementation include priority-based voting, prevotes, cluster reconfiguration, and out-of-band heartbeat generation.
While the technical details of these features are beyond the scope of this article, we can say that Redpanda's cluster coordination and data management using Raft is easier to use, easier to understand, and much more streamlined than Kafka's relatively recent attempt.
Embedded schema management - no separate schema registry
Separating schema from data significantly reduces the amount of data communicated in each message—the schema is registered once with a separate "schema registry" and then encoded in a compressed format. The message consumer asks the registry for the corresponding schema and decodes the message. To achieve schema registry benefits In Kafka, you must install, configure, and manage another component alongside the Kafka cluster.
In contrast, in Redpanda, each node functions as a message broker and schema registry. The exact Raft-based mechanism stores the schema, and separate API endpoints are exposed to register and query schemas from any node. So we get all the benefits of the schema registry without any of the management overhead.
Redpanda Console - easier configuration and management
Redpanda Console is an intuitive and convenient graphical user interface that you can use to interact with a Redpanda cluster, a Kafka cluster, or any solution that adheres to the Kafka API. It makes these interactions much more convenient than the usual command line interfaces.
It also has several features like push notifications, message filtering and search, and many useful debugging features to use when something goes wrong with your data stream.
[CTA_MODULE]
Kafka’s storage management limitations
One major issue with Kafka's infinite log-based streaming mechanism, is that no data is ever deleted automatically. This can lead to cluster storage running out of capacity very fast, especially in high-throughput environments. Kafka users typically work around the problem using techniques like log compaction, where only the most recent messages having a given key are retained and older messages are deleted.
Furthermore, as message keys may themselves become irrelevant over time, topic TTLs are configured and messages older than a certain time are deleted irrespective of their keys. Deciding which messages are old enough to delete can get tricky given that there are usually multiple consumers with different processing times and priorities, and it can be difficult to find the right TTL for each application.
Redpanda cloud-first storage - seamless infinite data retention
Redpanda provides an elegant solution to this conundrum through its built-in cloud-first storage mechanism. Instead of being deleted, older messages are moved to less expensive cloud-based object storage. This mechanism is fully invisible to the message consumer. A message would be queried using the usual protocol, and the Redpanda cluster figures out if message data is available locally or retrieves it from the cloud.
That means that the cluster never runs out of storage capacity, and yet, no messages need to be deleted!
Cloud-first storage also makes it easier to scale a Redpanda cluster, since storage capacity is no longer a constraint. The worst that can happen is that fewer messages would be stored locally, and message retrieval might be slower for some consumers.
Another benefit of cloud-first storage is that it enables disaster recovery out of the box. Even if something goes wrong with the cluster, you can use object store messages to rebuild topics later on a separate cluster. Redpanda stores sufficient metadata in the object store by default to make recovery easier.
Remote Read Replicas - effective topic replication
Remote read replicas are a neat way to replicate topics between Redpanda clusters that use the same tiered storage model to make the best use of the cloud. Read replicas allow you to set up a read-only topic in a Redpanda cluster that gets topic messages from the object store archive of a separate cluster.
This allows you to bring messages closer to consumers, and you can extend the feature even further using hardened mechanisms provided by object stores. For example, a producer in the United States could efficiently and reliably send messages to a consumer as far away as Singapore, as illustrated below:
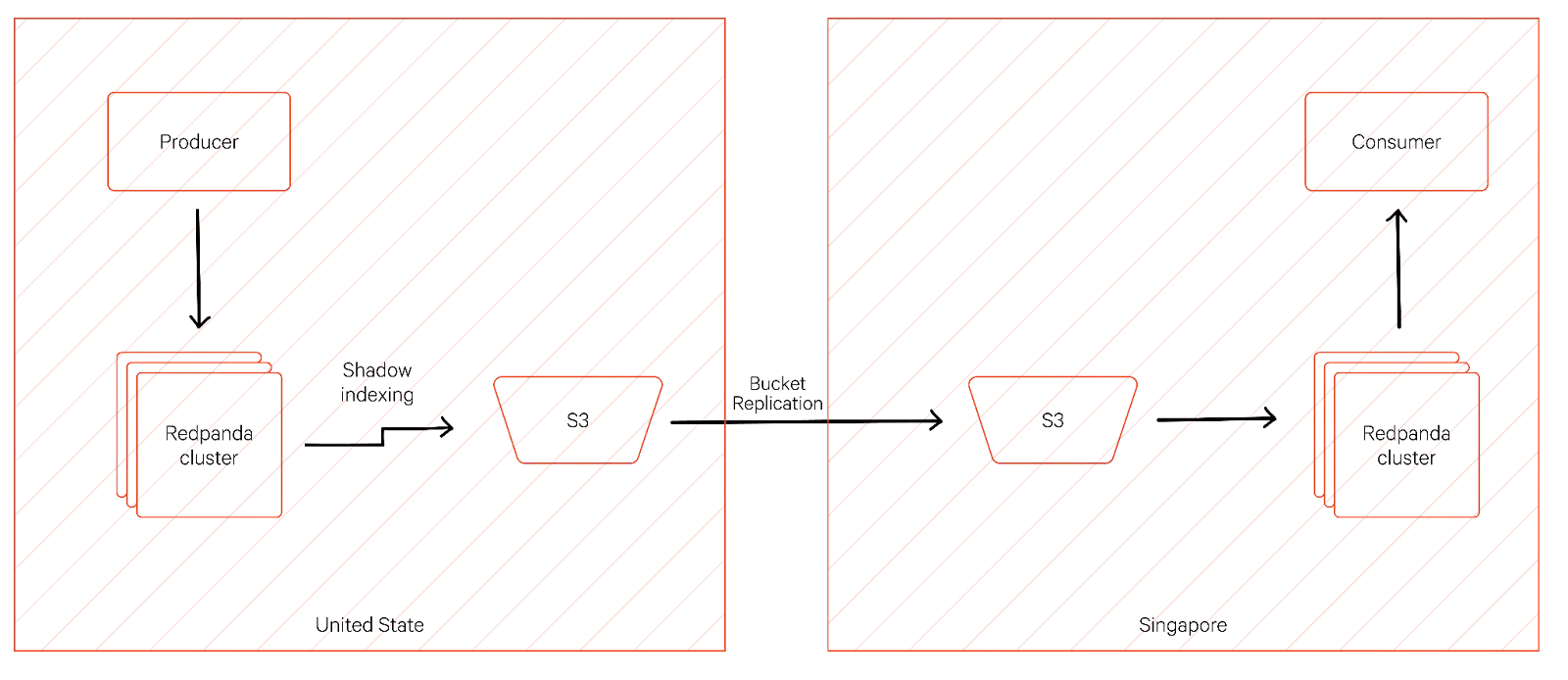
You can easily and seamlessly replace complex message replication mechanisms like Kafka Mirrormaker.
Kafka’s performance limitations
Redpanda is designed to maximize the hardware it is running on and get messages from producer to consumer as fast as possible. To this end, Redpanda's processes are architected to make better use of modern systems, with more CPU cores, faster networks, and faster storage like NVMe disks.
This has led to consistently better benchmark performance over Kafka, especially in the context of tail latencies (latencies that go above the 99.99th percentile). These latencies may seem so rare as to be insignificant but become very relevant in data streaming applications that handle millions of messages at any given time.
Some examples of Redpanda's features that enable performance are listed below.
C++ implementation
Redpanda is implemented in C++ (as opposed to Kafka's JVM-based implementation), enabling it to interact with the underlying node operating system at a much lower level. It uses this proximity to the kernel to best effect- pinning threads to CPU Cores, intelligently managing memory, and so on, all to eke out the best performance possible from the available hardware.
Redpanda autotune
The Redpanda CLI provides an autotune feature that scans details of the hardware it is running on and optimizes Linux kernel settings for maximum performance. These settings include:
- Disabling power-saver modes
- Running CPU at 90% utilization
- Driving SSDs at maximum throughput
- Disabling RAM swapping so that Redpanda controls how much memory is allocated to different processes
All these measures enable Redpanda to fully take control of the underlying hardware to run fast and, equally importantly, predictably.
One thread per core
Since Redpanda is optimized for modern systems, it operates on the principle that disk I/O is very fast. Because of this, it does not use heavy CPU measures like context switching and thread swapping- in modern systems, these operations are actually slower than disk I/O! Redpanda runs using a single thread pinned to each core of the CPU, which runs from beginning to end without ever being allowed to be idle. One thread per core enables full usage of faster disks and overall much faster execution.
Cost of ownership
Redpanda performs better on fewer resources and eliminates the requirement of auxiliary components like ZooKeeper, Schema Registry, and Mirrormaker. So, it is much more cost-effective to run a Redpanda cluster than a Kafka cluster with a comparative performance. In our Redpanda vs. Kafka performance comparison, we can see Redpanda clusters being up to 6x less expensive than their corresponding Kafka clusters across various cluster sizes and capacities.
Compatibility with the Kafka API
After reading about all the ways in which Redpanda does better than Kafka, it may be hard to believe that it is still identical in terms of the API interface. However, the producer and consumer API interfaces of Redpanda are identical to those of Kafka, so no code changes are needed in existing applications. Any existing Kafka client will work seamlessly with a Redpanda cluster.
Redpanda has been tested and validated against a number of Kafka clients implemented in a host of languages, including Java, Go, Python, Rust, and Node.js. It also has an active and responsive support team that quickly addresses any issues that may arise with other clients.
Beyond this, Redpanda also is being actively developed to ensure that any remaining gaps with the Kafka interface are addressed immediately and that no new gaps should develop.
Bottom line: It’s safe to say that we can seamlessly replace our Kafka clusters with simpler, less expensive Redpanda clusters without impacting any of our producers or consumers.
[CTA_MODULE]
Conclusion
You can get several performance and ease-of-use benefits by switching from Kafka to Redpanda while still leveraging the familiar Kafka API. Redpanda is much faster than Kafka because of its C++ implementation and is optimized for modern hardware. Its Tiered Storage mechanism eliminates worries about storage capacity and data bloat. Its focus on the user experience through convenient features like the Redpanda Console and its single binary installation and upgrade process make it much simpler to use.
Overall, Redpanda makes a strong case for being the next logical step as a next-gen data streaming solution in an increasingly data-driven world. To learn more, read our blog post on when to choose Redpanda instead of Kafka.
[CTA_MODULE]