

Kafka MirrorMaker—Tutorial, best practices and alternatives











Kafka MirrorMaker
Kafka MirrorMaker is the Apache Foundation's solution for inter-cluster topic replication for Apache Kafka®. Kafka MirrorMaker was initially developed as a replication solution to maintain secondary clusters for high availability and aggregation.
However, modern SaaS applications require large deployments spanning multiple global data centers. This led to the development and release of Kafka MirrorMaker 2, with more features and better support. Developers now use MirrorMaker 2 in a wide range of applications, including as a communication channel for sending messages between Kafka clusters located in separate data centers.
In this article, we look at the architecture and functioning of Kafka MirrorMaker 2, learn how to set up topic replication, and discuss some problems and alternative solutions.
Summary of key concepts
We will look at the following topics in this article:
Cross-cluster messaging - what and why?
Kafka clusters run on one or more connected Kafka nodes, with each topic being partitioned across nodes to enable faster reads and greater parallelism. Producers send messages to the cluster via a coordinator like Apache ZooKeeper™. ZooKeeper is responsible for routing messages to the right node in the cluster.
However, there are three main reasons why messages must be sent between Kafka clusters.
Unidirectional message replication
The first example of cross-cluster messaging is creating two Kafka clusters for disaster recovery. One of the clusters is the primary, or active, cluster, and all applications communicate via this cluster. A secondary cluster is created and kept available so that applications can switch over to the secondary cluster if something goes wrong with the active cluster. Since message processing takes time, it becomes necessary to replicate all messages from the primary cluster to the secondary cluster to ensure minimal downtime and data loss.
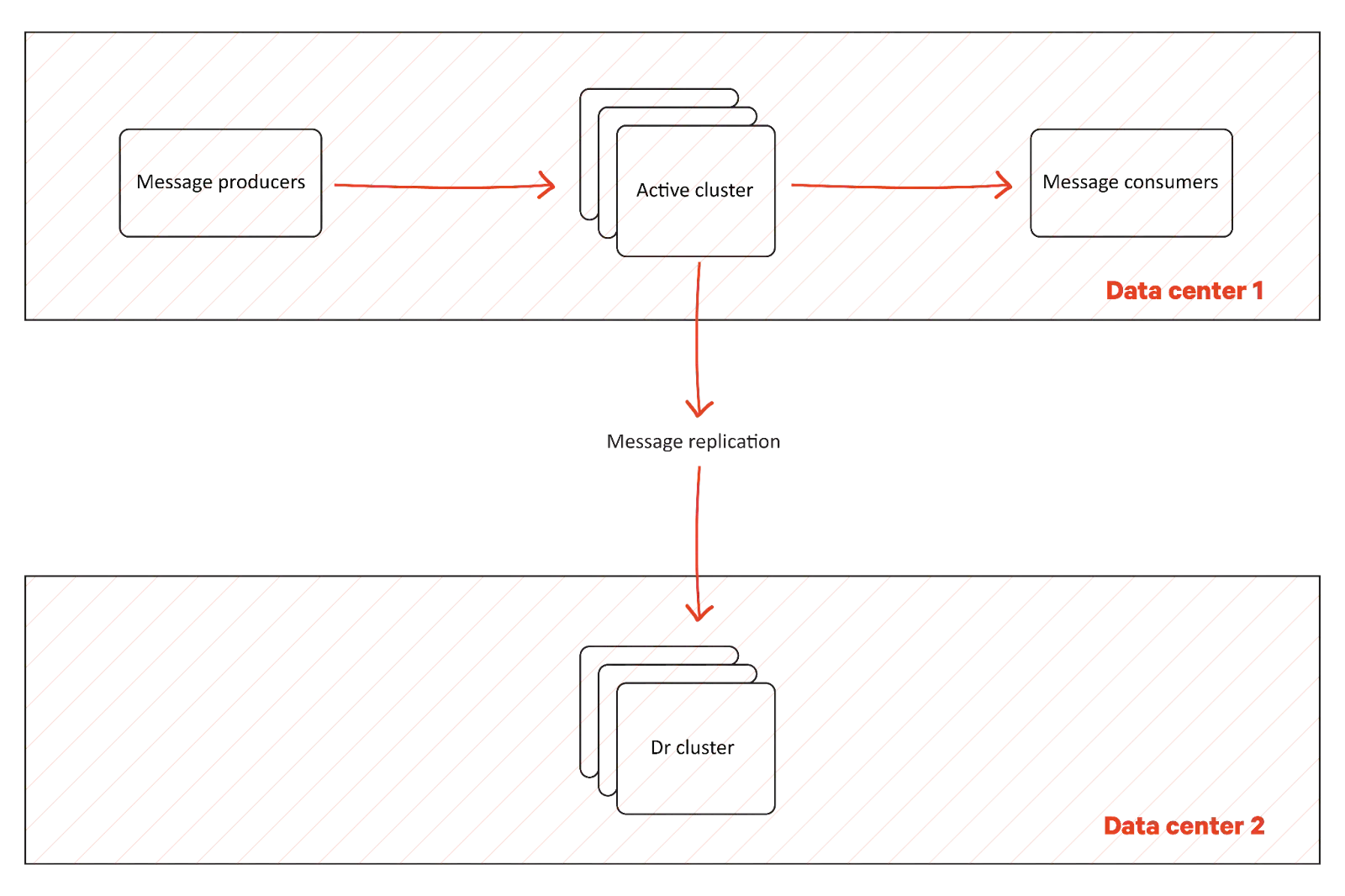
From the message replication solution perspective, the following scenarios also require a unidirectional flow of messages (always from one cluster to the other).
- Cluster migration from one data center to another or from on-premises data centers to the cloud.
- Compliance scenarios require some confidential data to be moved to a separate, secure cluster.
Bidirectional replication
Some situations require more complex inter-cluster synchronization and messaging. For example, consider services deployed in different regions in a given public cloud that communicate with each other via Kafka topics. You could create a single Kafka cluster spanning both regions, sometimes called stretch clusters.
However, a stretch cluster is prone to disconnections and latency issues between regions and can bring down the availability and performance of the entire cluster. Also, if some of the services are deployed in on-premises data centers, there would be a cost associated with moving data between nodes in the cluster. In such situations, it becomes more efficient to have separate clusters in each region and have a controlled cross-cluster channel through which only necessary messages can be sent across regions.
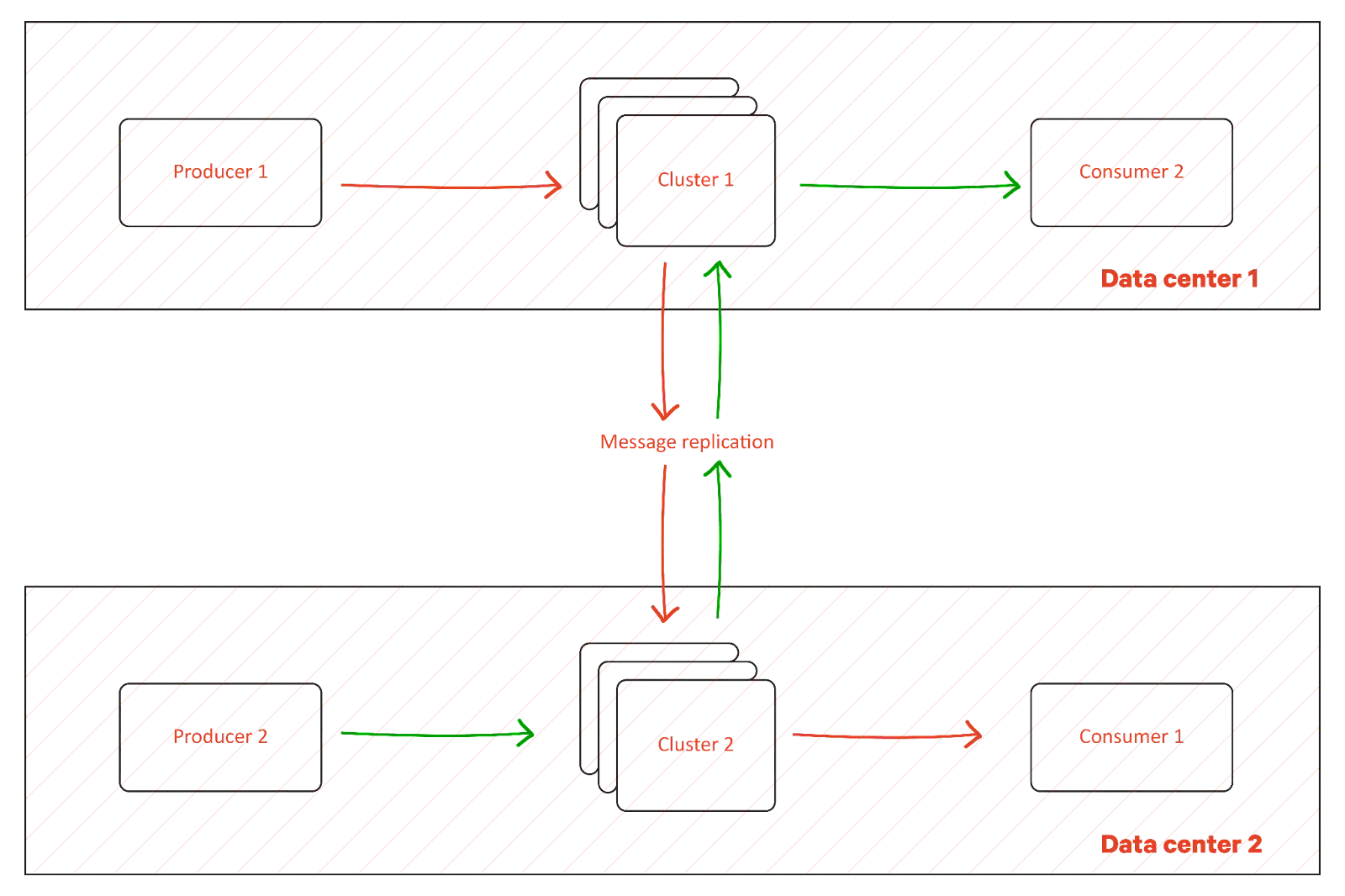
As mentioned above, such deployments allow data to be kept closer to the consumer and avoid connectivity issues.
Message broadcasting and aggregation
The third example of cross-cluster communication is a central Kafka cluster that broadcasts the same messages to multiple secondary clusters. It is useful in architectures where only small worker components are deployed across data centers and need instructions from a central component.
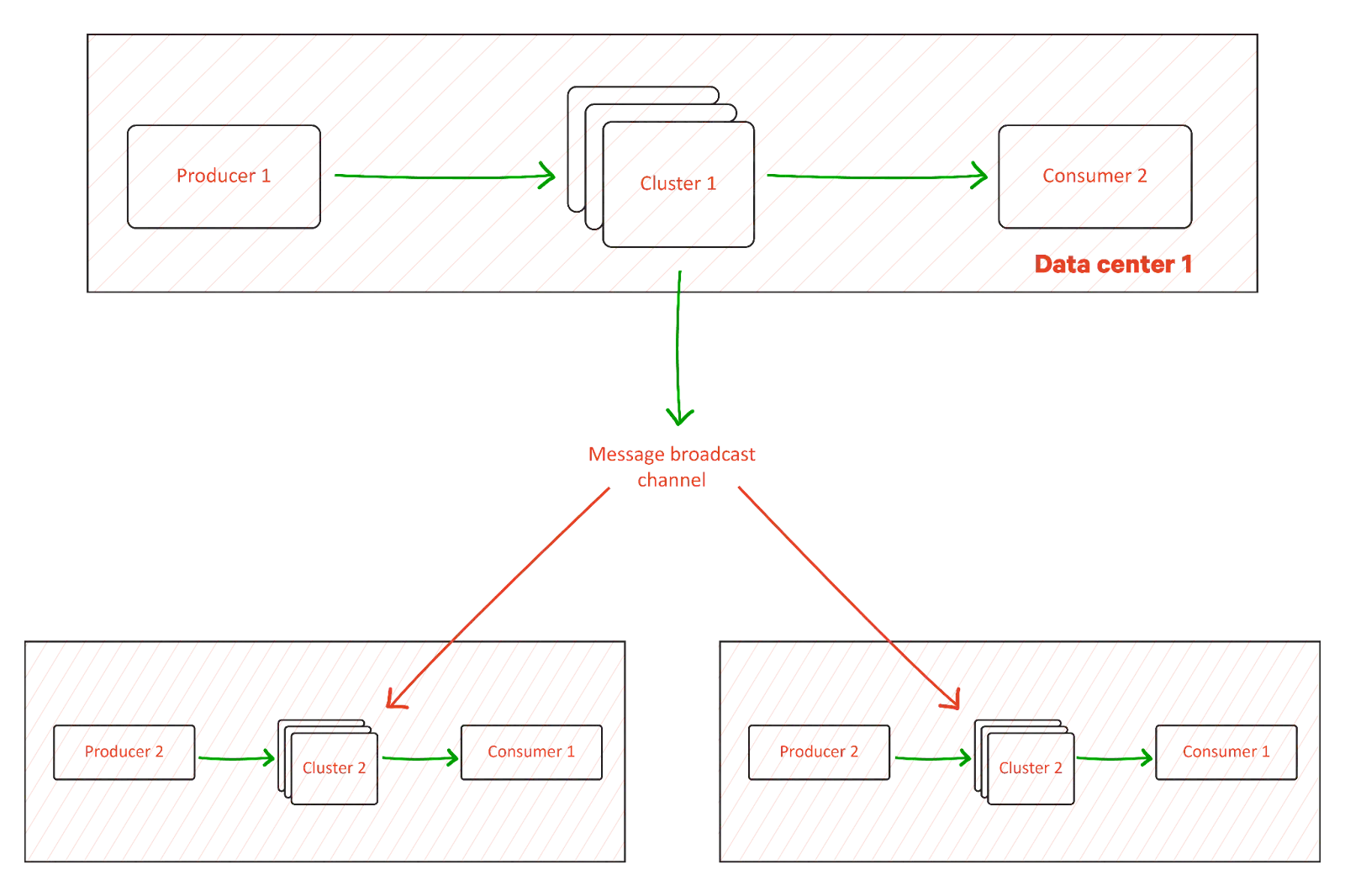
It is also possible that the communication happens in the reverse direction, for example, when you aggregate data from different locations to a central one for analytics or other secondary data processing applications.
[CTA_MODULE]
Kafka MirrorMaker
Kafka MirrorMaker provides the solution for creating communication channels between multiple Kafka clusters. It ensures that messages sent to the source topic are delivered automatically and continuously to the corresponding topic in the target cluster, automatically handling temporary network outages. You can deploy it to handle unidirectional, bidirectional, or multiway communication between your Kafka clusters.
Architecture
MirrorMaker comprises a connected pair of a standard Kafka consumer and a Kafka producer. The consumer listens for messages on the source topic and passes them to the producer, which continuously writes them to the corresponding topic in the target cluster.
Kafka MirrorMaker 2, released in December 2019 as a part of Apache Kafka 2.4.0, added multiple improvements to this basic architecture and effectively replaces MirrorMaker 1 in most scenarios.
Kafka Connect framework
MirrorMaker 2 leverages the Kafka Connect framework to consume and produce messages internally. It functions as a separate, intermediate cluster that can handle multiple replicated topics between a pair of Kafka clusters in either direction.
Offset mapping
Kafka MirrorMaker 2 adds offset translation between source and target clusters, so consumers switching over to the target cluster can track which messages have been processed and which haven't.
Cluster prefixes
MirrorMaker 2 adds cluster prefixes to replicated topics, so replicated topics in the target cluster are prefixed with the ID or name of the source cluster. This feature avoids confusion between replicated and created topics. It can also help prevent unintentional situations where a replicated topic in the target cluster starts getting replicated back to the original cluster. However, for situations like disaster recovery, we may need replicated topics to have the exact same name as the original topics. In such situations, we can turn off this feature.
Dynamic rule changes
Kafka MirrorMaker 2 adds dynamic deny listing/allow listing of topics to replicate, removing the need to restart MirrorMaker each time the rules need to be changed.
Deployment example
A two-cluster deployment with Kafka MirrorMaker 2 works as shown in the diagram below.

To achieve bidirectional message replication between clusters C1 and C2, we create two pairs of connectors in our MirrorMaker cluster. The system works as follows.
- The source connector C-B listens to messages from topic B in cluster C1 and writes them to an internal Kafka topic.
- The sink connector PB writes messages from the internal topic to a replicated topic C1.Topic B in cluster C2.
- The replicated topic in C2 is prefixed with the cluster id C1, to indicate that it is a replicated topic.
- The consumer in C2 simply subscribes to Topic B in cluster C2 and receives messages.
The consumer in C2 is not aware of the location of the producer or the existence of the source cluster. This makes the overall configuration of the producers and consumers very convenient, especially in scenarios where they would need to fail over between the clusters multiple times.
Kafka MirrorMaker setup tutorial
In this tutorial, we create two Kafka clusters and a MirrorMaker cluster, and setup replication. The tutorial steps have been performed on a Linux machine with docker installed.
We have intentionally used simple docker commands to create Kafka containers and start replicating topics. These steps can be encapsulated and maintained through a Docker Compose file for more permanent deployments.
MirrorMaker setup
First, create a basic Kafka MirrorMaker configuration file, as shown below.
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# see org.apache.kafka.clients.consumer.ConsumerConfig for more details
# Sample MirrorMaker 2.0 top-level configuration file
# Run with ./bin/connect-mirror-maker.sh connect-mirror-maker.properties
# specify any number of cluster aliases
clusters = A, B
# connection information for each cluster
# This is a comma separated host:port pairs for each cluster
# for e.g. "A_host1:9092, A_host2:9092, A_host3:9092"
A.bootstrap.servers = <localhost_ip>:9092
B.bootstrap.servers = <localhost_ip>:9093
# enable and configure individual replication flows
A->B.enabled = true
# regex which defines which topics gets replicated. For eg "foo-.*"
A->B.topics = .*
# Setting replication factor of newly created remote topics
replication.factor=1
############################# Internal Topic Settings #############################
# The replication factor for mm2 internal topics "heartbeats", "B.checkpoints.internal" and
# "mm2-offset-syncs.B.internal"
# For anything other than development testing, a value greater than 1 is recommended to ensure availability such as 3.
checkpoints.topic.replication.factor=1
heartbeats.topic.replication.factor=1
offset-syncs.topic.replication.factor=1
# The replication factor for connect internal topics "mm2-configs.B.internal", "mm2-offsets.B.internal" and
# "mm2-status.B.internal"
# For anything other than development testing, a value greater than 1 is recommended to ensure availability such as 3.
offset.storage.replication.factor=1
status.storage.replication.factor=1
config.storage.replication.factor=1
#Whether to periodically check for new topics and partitions
refresh.topics.enabled=true
#Frequency of topic refresh
refresh.topics.interval.seconds=10
# customize as needed
# replication.policy.separator = _
# sync.topic.acls.enabled = false
# emit.heartbeats.interval.seconds = 5After creating A and B aliases for our clusters, we enabled topic replication from A (kafka1) to B (kafka2) for all topics. The rest of the configuration properties set replication factors for all created and metadata topics. You can set more properties for higher customization that are not shown above.
Please note: Redpanda (a simpler Kafka alternative) simplifies MirrorMaker2 installation significantly. The Redpanda Connectors container includes MirrorMaker2. All you have to do is start the container and configure Redpanda Console to connect to the service. Once you’re done, use Redpanda Console to set up the MirrorMaker2 connections, configuration, and authentication details. You can also use the Redpanda Connectors REST API to configure connectors programmatically.
The Connectors container needs to run in an environment adjacent to the destination Redpanda cluster. The container needs to connect to every broker in the Redpanda cluster and source cluster.
[CTA_MODULE]
Kafka cluster creation
Next, create two simple, single-node Kafka clusters (along with one ZooKeeper™ node each for coordination). Note that we have used ZooKeeper™ nodes for cluster coordination in this tutorial. You could also deploy your Kafka clusters without ZooKeeper™ and use some Kafka nodes as coordinators. This will not impact the functioning of Kafka MirrorMaker.
Cluster 1
docker run --name zookeeper1 \
-p 2181:2181 \
-e ZOOKEEPER_CLIENT_PORT=2181 \
-e ZOOKEEPER_TICK_TIME=2000 \
-d confluentinc/cp-zookeeper:latestdocker run --name kafka1 \
-p 29092:29092 -p 9092:9092 \
-e KAFKA_BROKER_ID=1 \
-e KAFKA_ZOOKEEPER_CONNECT=<localhost_ip>:2181 \
-e KAFKA_LISTENER_SECURITY_PROTOCOL_MAP="PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT" \
-e KAFKA_ADVERTISED_LISTENERS="PLAINTEXT://localhost:9092,PLAINTEXT_HOST://localhost:29092" \
-e KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR=1 \
-e KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS=0 \
-e KAFKA_TRANSACTION_STATE_LOG_MIN_ISR=1 \
-e KAFKA_TRANSACTION_STATE_LOG_REPLICATION_FACTOR=1 \
-d confluentinc/cp-kafka:latest
Cluster 2
docker run --name zookeeper2 \
-p 2182:2181 \
-e ZOOKEEPER_CLIENT_PORT=2181 \
-e ZOOKEEPER_TICK_TIME=2000 \
-d confluentinc/cp-zookeeper:latestdocker run --name kafka2 \
-p 29093:29092 -p 9093:9092 \
-e KAFKA_BROKER_ID=2 \
-e KAFKA_ZOOKEEPER_CONNECT=<localhost ip>:2182 \
-e KAFKA_LISTENER_SECURITY_PROTOCOL_MAP="PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT" \
-e KAFKA_ADVERTISED_LISTENERS="PLAINTEXT://localhost:9093,PLAINTEXT_HOST://localhost:29092" \
-e KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR=1 \
-e KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS=0 \
-e KAFKA_TRANSACTION_STATE_LOG_MIN_ISR=1 \
-e KAFKA_TRANSACTION_STATE_LOG_REPLICATION_FACTOR=1 \
-v <directory_containing_config_file>:/config
-d confluentinc/cp-kafka:latestRemember to update the <localhost_ip> and <directory_containing_config_file> values (highlighted above) to the appropriate values in your setup.
- <localhost_ip> is the ip address of the machine where docker is running
- <directory_containing_config_file> is the directory where we created the MirrorMaker config file in step 1
Wait for a few seconds after running the above commands, and then check the logs of the kafka1 and kafka2 containers to ensure that the clusters are running fine.
List topics
Next, list the topics in both clusters using the following commands.
docker exec -it kafka1 kafka-topics --bootstrap-server localhost:9092 --list
docker exec -it kafka2 kafka-topics --bootstrap-server localhost:9093 --listNo topics should be output since we have yet to create any.
Start Kafka MirrorMaker
You can start MirrorMaker as shown below. Be sure to replace <config_file_name> with the name of your saved config file.
docker exec kafka2 connect-mirror-maker /config/<config_file_name>Note that we have run MirrorMaker on kafka2, since it is better to have MirrorMaker colocated with the target cluster. In our simple deployment, we are also reusing the target broker as the MirrorMaker broker. You can run MirrorMaker on a separate, third cluster if you want more control and scale.
Check MirrorMaker
You will see logs of the MirrorMaker process start to show. If you see a log4j exception, you can pass log4j properties to the kafka2 container using the environment variable KAFKA_LOG4J_OPTS. List topics again in both clusters using the commands above. You will see metadata and heartbeat topics created by Kafka MirrorMaker.
Create topics
Once MirrorMaker is running, you can create a topic in each cluster using the following commands.
docker exec -it kafka1 kafka-topics --bootstrap-server localhost:9092 --create --topic topic1
docker exec -it kafka2 kafka-topics --bootstrap-server localhost:9093 --create --topic topic2Now if you list topics in kafka2, you should see an additional topic called A.topic1. This is the replicated topic created by MirrorMaker. Since we have only enabled replication from cluster A to cluster B, MirrorMaker will not create a corresponding topic for topic2 in cluster A.
You can use the Kafka console producer to produce messages to topic1 in kafka1, and a console consumer to consume those messages from A.topic1 in kafka2. You can play around with the MirrorMaker configuration file and see how the topic replication changes accordingly.
Kafka MirrorMaker best practices
To achieve smooth communication between clusters, you can do the following.
Target-based deployment
Run a distributed MirrorMaker cluster with multiple nodes to ensure better performance and high availability of the MirrorMaker cluster itself. As far as possible, deploy the Kafka MirrorMaker cluster in the target data center. This ensures that message delivery to the target (and eventually to the consumers) is done with minimal latency and fewer interruptions, and with lesser buffering of messages in the MirrorMaker cluster.
Performance tuning
You should plan for the added load on the source cluster introduced by the additional MirrorMaker consumers. That way, actual local consumers from the same topics are not affected. This added load will primarily be network bandwidth usage. Also, remember to track the MirrorMaker consumer offsets to monitor replication lag. You can catch longer network outages early and ensure that too much load is not introduced on the MirrorMaker cluster.
Kafka MirrorMaker limitations
Kafka MirrorMaker 2, while definitely a valuable tool for cross-cluster message replication, still has some limitations.
Increased costs
Along with the actual replicated data, MirrorMaker metadata such as heartbeats, offset sync, and so on causes some continuous data movement between clusters, even when the actual topics are fairly quiet. Depending on where the source and target clusters are deployed, this can consume bandwidth and increase latencies.
Decreased performance
Processes such as failing over between data centers require additional steps to ensure data is not lost or processed multiple times. In addition, in situations requiring bidirectional replication, having the MirrorMaker cluster colocated with the target cluster will not always be possible. This can lead to additional buffering and message latencies for one of the clusters. All this can slow down your application performance.
Schema management challenges
Often, messages are sent with an encoded schema to reduce the size of each message. The schema is maintained separately using components such as the Schema Registry. Using Kafka MirrorMaker requires additional handling to replicate schema between the source and target clusters, and introduces some limitations to features such as schema versioning.
Limitations of Kafka in general
On a more general level, Kafka has several issues and limitations. For example, because of how topics are designed (as append-only logs), long-term use of Kafka leads to an ever-increasing memory requirement. In addition, commonly used solutions like deleting older messages mean that only a limited amount of history can be maintained, which can cause issues for larger enterprise applications. Other limitations include JVM issues such as garbage collection.
Thus, nowadays, products are looking to new-age Kafka alternatives that provide better functionality and more convenient features.
Redpanda
Redpanda is a C++-based solution offering better performance and more convenient data retention than Kafka. It uses a multi-tiered approach to data retention, keeping recent messages in local memory and periodically archiving older messages to less expensive, cloud-based blob storage. While compatible with the Kafka API, Redpanda has been created with a focus on better performance, ease of use, and convenient features.
Redpanda's approach to message replication
Disaster recovery
In the context of cross-cluster replication for disaster recovery, Redpanda's modern approach to data retention can completely eliminate the need for a separate solution like MirrorMaker in scenarios where some downtime is acceptable in a disaster.
All messages are periodically archived in cloud storage and contain all metadata necessary to start a new cluster elsewhere with the same messages and topics. So, we can operate a single Redpanda cluster and rest assured that our messages are safe. If there is an issue in the original cluster, we can use the data from cloud storage to start a new cluster and continue processing messages seamlessly.
Message replication for reduced latency
In the context of latency reduction, a feature called Remote Read Replicas uses cloud storage replication to keep two Redpanda clusters in different regions synchronized. Here, too, the messages and topics that have been archived to cloud storage are replicated to a region closer to the customer. Remote read replicas use this data to create a read-only cluster with a lower latency from which client applications can consume messages.
Thus, Redpanda can significantly simplify complex product deployments, eliminating the need for auxiliary solutions like MirrorMaker.
[CTA_MODULE]
Conclusion
Replication of messages between Kafka clusters is an increasingly common requirement in large-scale distributed applications for reasons such as disaster recovery, compliance, and latency. Kafka MirrorMaker (especially the newer MirrorMaker 2) is a relatively simple solution for this requirement, using Kafka's native Connect framework and providing scalability and automation. However, there are still some limitations and issues with Kafka MirrorMaker and with Kafka itself. Therefore, it can be worth considering alternative solutions like Redpanda. Here is a detailed guide on migrating to Redpanda from Kafka services.
[CTA_MODULE]