

Kafka Raft vs. ZooKeeper vs. Redpanda











Kafka Raft
Kafka Raft, or KRaft, is a consensus protocol in Apache Kafka®. It aims to remove Kafka’s dependency on Apache ZooKeeper™—an open-source distributed server coordination platform. KRaft is based on the Raft consensus protocol and addresses several potential failures in large Kafka clusters. Moving away from ZooKeeper simplifies Kafka’s architecture and removes the need for deploying two separate distributed systems to be fully operational.
That said, Kafka was not designed with KRaft in mind. Hence the migration has introduced several additional layers to Kafka deployments. If you are looking for a distributed streaming platform built with Raft as a consensus protocol from the ground up, check out Redpanda.
This article covers Kafka Raft, how it compares to ZooKeeper, the improvements it brings to Kafka, and its limitations.
Summary of key Kafka Raft concepts
The introduction of Kafka Raft-based quorum controller helps to manage cluster metadata in a robust and scalable way. This improves many operational aspects of Kafka.
Understanding Zookeeper-based Kafka architecture
Kafka is a distributed streaming data platform and a reliable event store. Kafka architecture consists of a set of brokers assembled as a cluster with one of them designated as the Kafka controller or the leader broker. By default, the broker who gets started first becomes the controller.
Its working model comprises message producers, consumers, and topics. The topics are stored as multiple partitions, and partitions have replicas. Different brokers store partition replicas, with one of the brokers being the designated leader for each partition.
A controlling mechanism that keeps track of the state of topics, partitions, and brokers is needed for such an architecture to work. This is where ZooKeeper comes in. ZooKeeper manages the following activities in a Kafka Cluster.
- Monitors the heartbeat messages from brokers and keeps track of the Kafka controller.
- Stores the partition metadata that includes the state of in-sync replicas and the broker that acts as the partition's leader.
- Stores the details of the topics like a list of topics, number of partitions for each topic, location of replicas, configuration details for topics, etc.
As you can observe, Zookeeper plays a key role during changes in a Kafka cluster—for instance, broker failures, onboarding new brokers, new topics, deletions, etc.
Reasons for moving away from ZooKeeper
Even though ZooKeeper is a reliable distributed coordination system, it creates several bottlenecks within the Kafka deployment architecture.
Complicated deployment
While Zookeeper is an integral part of Kafka’s architecture, it is is an auxiliary application for Kafka's functionality. It is yet another distributed system that requires additonal hardware provisioning, administration, and monitoring. As a result, developers have to manage two loosely coupled applications, increasing the operational complexity of a Kafka deployment. Removing the dependency on Zookeeper reduces the operational burden of Kafka.
Additionally, Zookeeper-based Kafka can only be started with multiple daemons. Removing the ZooKeeper dependency helps Kafka support a single-node deployment for development or testing purposes.
Availability issues
There are scenarios where ZooKeeper leaves Kafka brokers in a divergent state. At times notifications about state changes may only reach some brokers, and ZooKeeper mode does not have any recovery strategies other than a fixed amount of retries. Moving away from ZooKeeper allows Kafka to use its own topics to store the events related to state changes.
The state is stored as a set of events in a predefined Kafka topic with each event having an offset. In the event of a failure, brokers easily catch up and synchronize by replaying all events after their current offset. This helps in lowering the latency of metadata reads. Hence Kafka can recover a lot more quickly while in KRaft mode compared to Zookeeper mode.
Security and scalability
ZooKeeper was a limiting factor for the maximum number of partitions in a cluster. Replacing ZooKeeper helps Kafka to support a much larger number of partitions. Ensuring Zookeeper’s security model and upgrades are in sync with Kafka is complex. Removing Zookeeper simplifies Kafka’s security model.
[CTA_MODULE]
ZooKeeper mode vs. KRaft mode
KRaft is a consensus protocol that simplifies the leader election and logs replication. In ZooKeeper-based architecture, any broker node could be designated the Kafka Controller. In Kafka Raft-based architecture, only a few nodes are set as potential controllers. Kafka controller is elected from the possible list of controllers through the Raft consensus protocol.
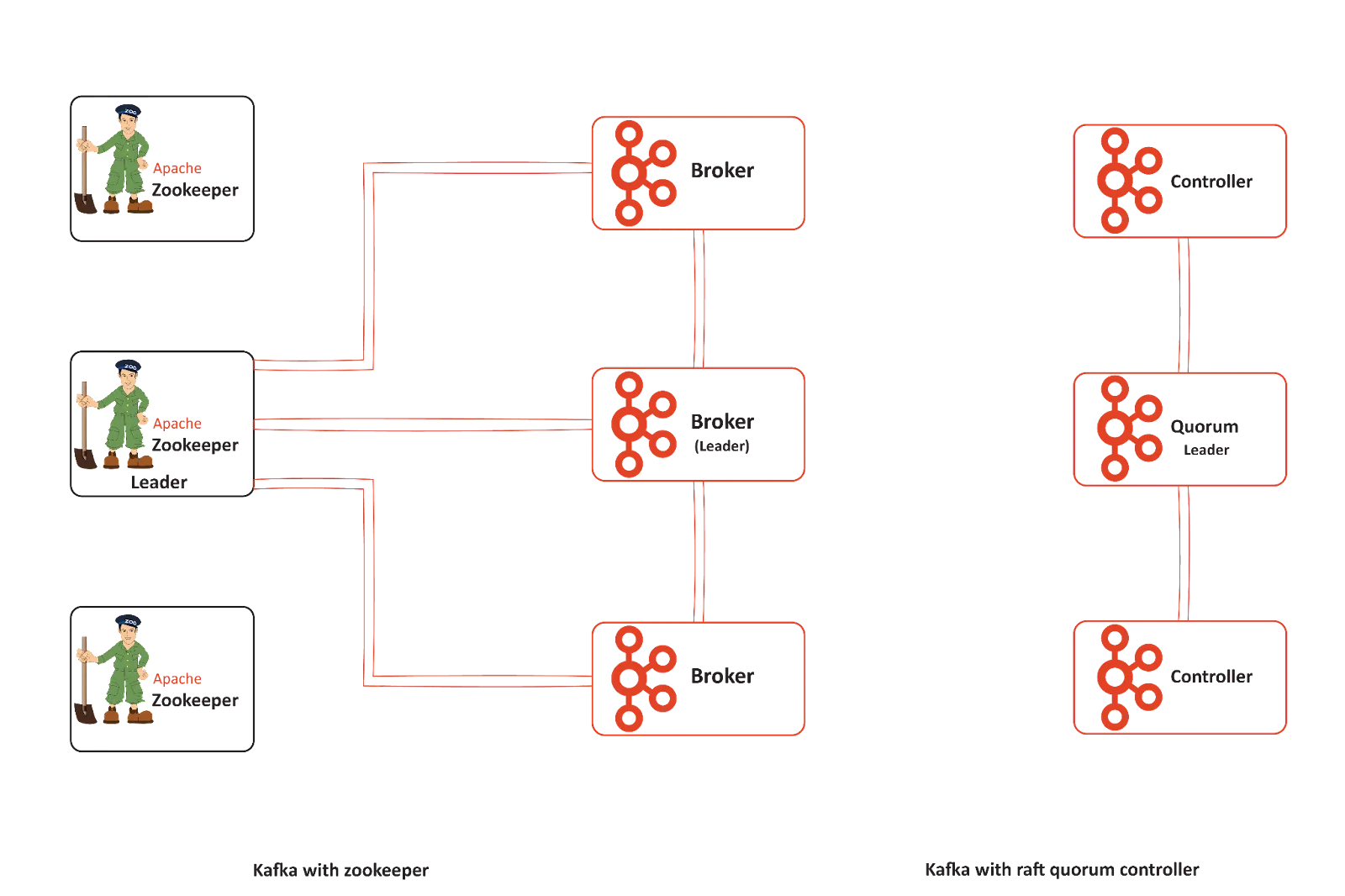
Metadata storage
While using ZooKeeper as the quorum controller, Kafka stores information about the Kafka controller in ZooKeeper. While using the Kafka Raft protocol, such metadata is stored in an internal topic within Kafka called ‘__cluster_metadata’. This topic contains a single partition.
State storage
Kafka Raft uses an event-sourcing-based variant of the Raft consensus protocol. Since the events related to state changes are stored in a Kafka topic, the quorum's state can be recreated at any point in time through a replay. This differs from ZooKeeper-based architecture in which state changes were isolated events with no ordering maintained within them.
Setting up Kafka with Raft
You can quickly start Kafka in Raft mode using the default configuration files bundled with Kafka. Kafka requires JDK as a prerequisite. Assuming you have an instance with a JDK setup, run the steps below.
Download the latest version of Kafka here and extract it.
tar -xzf kafka_2.13-xxx.tgz
cd kafka_2.13-xxx
Use the below command to generate the cluster's unique id.
KAFKA_CLUSTER_ID="$(bin/kafka-storage.sh random-uuid)"bin/kafka-storage.sh format -t $KAFKA_CLUSTER_ID -c config/kraft/server.propertiesUse the default Kafka raft property files to start the Kafka broker.
bin/kafka-server-start.sh config/kraft/server.propertiesThats it! Kafka in Raft mode should now be running in your system.
[CTA_MODULE]
Limitations of KRaft
Even though removing ZooKeeper is a step in the right direction for improving Kafka, the implementation of Kafka mode has several limitations. First, the integration can only be done in stages since Kafka was not envisioned with Raft in mind. The quorum controller and Kafka leader election have moved to Raft-based implementation, but the partition replication still follows Kafka’s quorum consensus algorithm.
Also, Kafka’s implementation of Raft is pull-based and comes with additional complexities. The pull-based implementation results in conflicts during the leader step down and adds an additional latency in the metadata commit process. Moving to Kafka Raft mode is a significant change, and organizations that use older versions of Kafka must do a complete upgrade and migration to accommodate it.
In the original Raft protocol paper, the leaders actively send requests to followers Alternatives like Redpanda use the push-based method.
Kafka Raft mode vs. Redpanda
Redpanda is a simple, powerful, and cost-efficient streaming data platform that is compatible with Kafka APIs while eliminating Kafka complexity. Even though Redpanda and Kafka share the same specifications for their consumer and producer APIs, the underlying architecture differs.
Kafka’s quorum controller system is implemented based on a modified version of the Raft consensus protocol. This version of Raft uses a pull-based system where brokers pull details from the quorum controller rather than the push-based system that the original Raft implementation used.
In the case of Redpanda, every partition forms a Raft consensus group consisting of its brokers within Redpanda. Redpanda nodes deploy as self-sufficient processes with built-in schema registry, HTTP proxy, Kafka API-compatible message, and Raft-based data management. Redpanda has been designed with Raft as the consensus protocol. Redpanda has already implemented partition replication and partition leader election based on Raft, while Kafka has not.
We actually performed a Redpanda vs. Kafka with Raft performance benchmark, and on its nearest comparison, Redpanda is still 10x faster at tail latencies than Kafka with Raft, with Redpanda running three nodes and Kafka running four nodes—and a further three nodes for KRaft, totaling seven extra nodes.
[CTA_MODULE]
Conclusion
Removing ZooKeeper and replacing it with Quorum Controller using Raft consensus simplifies Kafka architecture and security model to a great extent. Scaling is improved since Kafka in KRaft mode supports much larger partition counts. Kafka now supports single daemon installation, and the startup script is more straightforward.
That said, Kafka Raft integration still needs to be completed. At the moment, there are several additional layers compared to the ideal case. If you want a streaming platform based on Raft built from the ground up, check out Redpanda.
[CTA_MODULE]