

Kafka retention—Types, challenges, alternatives











Kafka retention
Apache Kafka® adopts a unique architectural approach to the publish/subscribe messaging concept by storing events as an append-only commit log. Instead of overwriting or modifying data, Kafka retains a complete history of events in the order they were received. Each event, or message, is appended to the end of the log, creating an immutable sequence of records. This log-based structure ensures that events are never modified, preserving data integrity.
This design choice brings several benefits, including fault tolerance, durability, scalability, and replayability; However, it makes data retention a critical aspect. If the defined retention period for a topic is too short, important data could be removed before it is consumed, leading to data loss But if it is set for too long, the ever-growing data volume poses local storage concerns which can crash a broker—and eventually the cluster.
This article explores Kafka retention policies that strike a balance between storage limitations and data archiving requirements. We look at retention considerations for various industry use cases and also discuss key challenges and solutions.
Summary of key Kafka retention concepts
What is Kafka retention?
Kafka retention refers to the configurable duration for which data is retained within the Kafka topic. It determines how long messages are stored in Kafka topics before they are eligible for deletion. Data retention is often required for a sufficient duration to ensure:
- Reconstruction of data pipelines or systems in the event of failures or data loss
- Replication to other Kafka clusters for data redundancy
- Support of real-time analytics and trend analysis
- Satisfaction of auditing and legal obligations
By setting a retention policy, you can control the lifespan of data in Kafka, ensuring durability, fault tolerance, and the ability to replay or process historical events.
In Kafka, a segment is a portion of the Kafka topic's commit log that contains a sequential set of messages or events. Each segment is a fixed-size disk file. As new messages are appended to the log, segments are created and filled up until they reach their maximum size.
The retention policy operates at the segment level rather than the individual message level. When the retention period for a Kafka topic expires, Kafka identifies and deletes entire segments that fall outside the retention window. This approach ensures that Kafka can efficiently reclaim disk space by removing entire segments rather than individual messages.
[CTA_MODULE]
Role of Kafka segments in retention
Kafka's segment-based retention approach optimizes storage utilization while ensuring that expired data can be systematically and reliably removed from the commit log. Segments define the granularity for data retention and enable efficient deletion based on the retention (i.e., “Cleanup”) policy.
Here's how Kafka segments and retention are related.
Segment size controls retention
Kafka allows configuring the maximum size of each segment in a topic's log. When the segment reaches its size limit, a new segment is created, and subsequent messages are appended to the new segment. This segment size impacts the granularity and efficiency of data deletion during retention. Smaller segment sizes result in finer-grained retention but may increase storage overhead due to a larger number of segments. On the other hand, larger segment sizes optimize storage but delay the deletion of expired data.
Segment configuration—log.segment.bytes
Once the log segment has reached the size specified by the log.segment.bytes parameter, which defaults to 1 GB, the log segment is closed and a new one is opened. Once a log segment has been closed, it can be considered for expiration. A smaller log-segment size means that files must be closed and allocated more often, which reduces the overall efficiency of disk writes. Adjusting the size of the log segments can be important if topics have a low produce rate.
For example, if a topic receives only 100 megabytes per day of messages, and log.segment.bytes is set to the default, it takes 10 days to fill one segment. Messages don’t expire until the log segment is closed.
Segment configuration—log.segment.ms
It specifies the amount of time after which a log segment should be closed. The parameters log.segment.bytes and log.segment.ms are not mutually exclusive properties. Kafka closes a log segment either when the size limit is reached or when the time limit is reached, whichever comes first. By default, there is no setting for log.segment.ms, which results in only closing log segments by size.
Types of Kafka retention
Apache Kafka provides two types of retention policies.
Time-based retention
Time-based retention policy is particularly useful in scenarios where data has a pre-determined lifespan—for instance when regulatory requirements mandate data retention for a specific duration.
Time-based retention configurations are given below.
These configuration settings determine how long messages or events are retained within Kafka brokers based on their timestamp. The default retention period is seven days. The policy applies globally to all topics within a Kafka cluster unless overridden at the topic level.
Once the configured retention time is up, the closed segment is marked for deletion or compaction depending on the configured cleanup policy. For example, if the retention policy is set to one day, Kafka automatically deletes closed segments that are older than a day.
It is important to note that time-based retention does not determine the exact time of deletion for every message—only the retention time after a log closes. For instance, consider a scenario where log.retention.hours is set to 168 and the segment size limit is 1 GB.
Let’s assume It takes seven days for producers to generate enough messages to fill the segment. Kafka retains the segment for seven days after the segment is full. So the first message in the segment is actually deleted 14 days after it was added to the log. As it was added on the first day, it stays in the segment for seven days until the segment closes and then seven more days of retention.
[CTA_MODULE]
Size-based retention
Another way to expire messages is based on the total number of bytes of messages retained. The relevant configuration is given below.
The log.retention.bytes parameter is applied per partition. This means that if you have a topic with 8 partitions, and log.retention.bytes is set to 1 GB, the amount of data retained for the topic is 8 GB at most. Note that all retention is performed for individual partitions, not the topic. This means that should the number of partitions for a topic be expanded, the retention increases automatically.
This policy is not popular as it does not provide good visibility about message expiry. However, it can be useful in a scenario where we need to control the size of a log due to limited disk space.
Kafka retention challenges
Managing retention in Kafka comes with its fair share of challenges. Let’s take a look at a few of them below.
Capacity planning
Retaining data for extended periods results in significant storage requirements. As data volume grows over time, you have to ensure that the Kafka cluster scales to handle increased storage demands. Proper capacity planning involves considering both current and future storage needs. Predicting and allocating sufficient storage capacity to accommodate the desired retention duration is crucial.
Balancing data freshness and storage costs
Different use cases have varying requirements for data freshness. Some use cases prioritize real-time data, while others may focus on cost optimization over immediate access to the most recent data. Striking the right balance between retaining fresh data and managing storage costs can be challenging. Exploring cost-effective storage options, such as tiered storage or data lifecycle management strategies, manages storage costs while retaining essential historical data.
Dynamic configuration changes
Use cases and business needs evolve over time, requiring adjustments to retention configurations. Defining appropriate thresholds for retention-related metrics, such as storage usage and data age, helps trigger timely actions or notifications when retention parameters need adjustment. However, changing retention settings dynamically in Kafka clusters is challenging due to potential impacts on data integrity and cluster performance.
Regulatory risks
Meeting compliance and regulatory requirements regarding data retention is challenging. Ensuring data is retained for the mandated duration and implementing proper auditing mechanisms are essential for regulatory compliance. Consideration must be given to any legal obligations that impact data retention. Adhering to specific data retention policies or contractual obligations is crucial to avoid legal risks.
How Redpanda improves Kafka retention challenges
We have seen how managing retention in Kafka comes with its own set of challenges. The configuration options it provides can sometimes be daunting for a user as the settings need to be carefully tuned or storage costs can spiral out of control very quickly. One relatively new solution to the problem of ever-growing data volume due to longer retention periods is Redpanda.
Redpanda is a C++ based streaming data platform that offers notoriously better performance and more convenient data retention than Kafka.
Multi-tiered storage approach
Redpanda uses a multi-tiered approach to data retention, keeping recent messages in local memory and periodically archiving older messages to less expensive, cloud-based object storage. It offers this tiered storage by default.
Tiered Storage helps to lower storage costs by offloading log segments to object storage. You can specify the amount of storage you want to retain in local storage. You don't need to specify which log segments you want to move because Redpanda moves them automatically based on cluster-level configuration properties. Tiered storage indexes where data is offloaded, so it can look up the data when you need it.
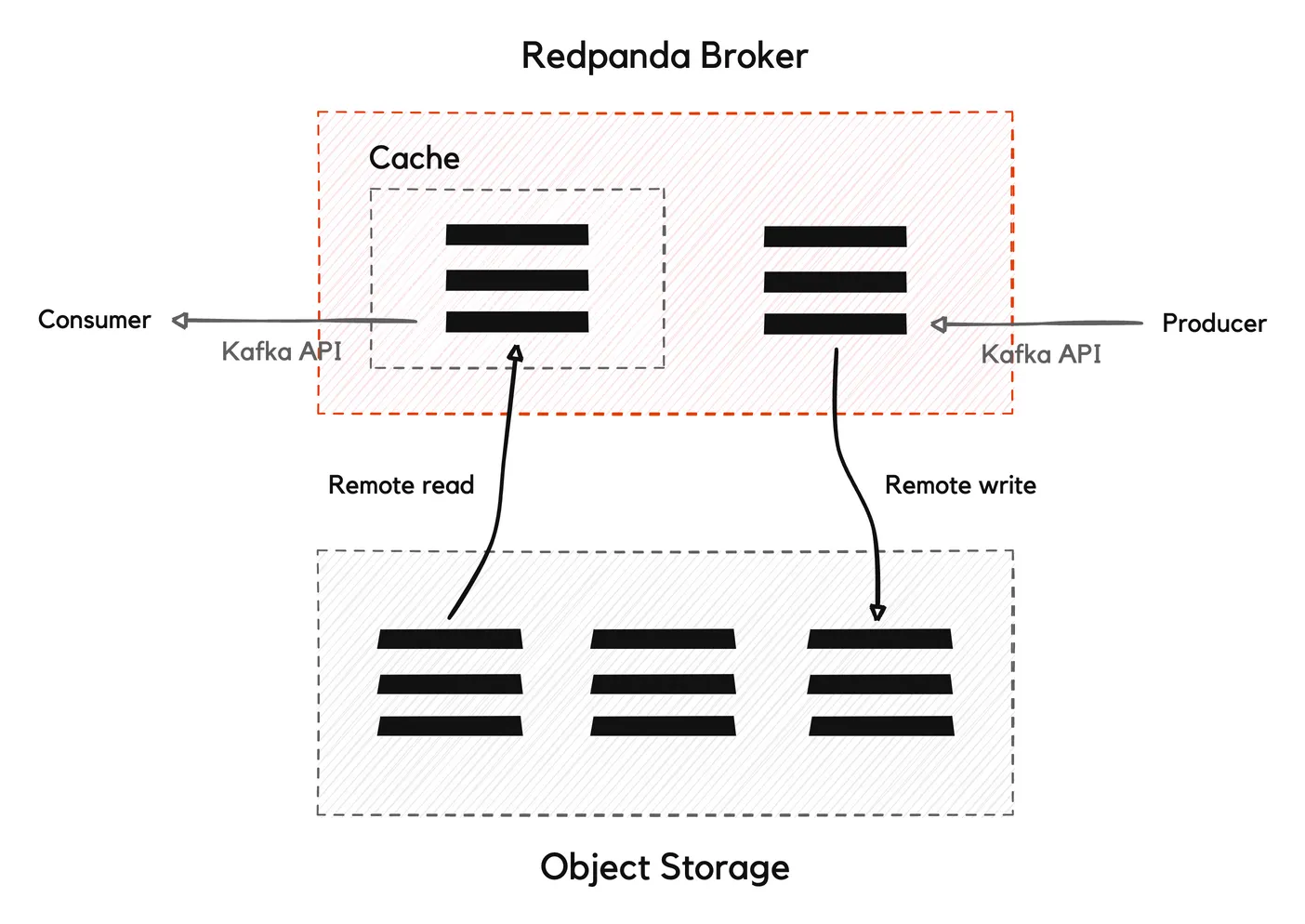
For example, you can have a hot tier consisting of high-performance and expensive storage like solid-state drives (SSDs) or in-memory storage for storing frequently accessed or recent data. The hot tier ensures that the most critical data is readily available for fast processing.
On the other hand, you can have a cold tier composed of lower-cost and higher-capacity storage options such as traditional hard disk drives (HDDs) or cloud object storage. The cold tier is used for storing less frequently accessed or older data that may not require immediate processing.
[CTA_MODULE]
Conclusion
Kafka retention has long been a critical aspect of data processing and storage, ensuring durability and fault tolerance; However, as organizations face the challenge of managing ever-increasing data volumes and storage costs, exploring alternative solutions becomes imperative.
Emerging technologies like Redpanda present a promising alternative to Kafka retention by addressing some of its inherent limitations. With Redpanda's innovative approach to storage and data management, organizations can benefit from improved scalability, reduced storage costs, and simplified data retention policies.
As the industry continues to evolve, it is essential to consider new solutions like Redpanda alongside Kafka retention to meet the evolving demands of data-driven organizations.
[CTA_MODULE]