

Kafka throughput—Trade-offs, solutions and alternatives











Kafka throughput
Kafka throughput is the measurement of the number of messages that an Apache Kafka® cluster processes in a specific period. It is one of the critical performance metrics in Kafka and is often a key determinant of the efficiency of data streaming operations. Kafka's architecture facilitates throughput by leveraging the distributed, partitioned, and replicated log service provided by its brokers.
However, several challenges can impact efficiency, such as the factors influencing throughput and the trade-offs between data retention and storage capacity. This article offers insights for achieving optimal Kafka throughput and explores Redpanda features that solve many of the challenges.
Summary of key concepts
| Factors affecting Kafka throughput | - Number of partitions - Message size - Kafka topic configurations - Hardware |
| Impact of high Kafka throughput | Ever-growing record log that causes storage and retention challenges. |
| Kafka throughput trade-off | Longer data retention aids in delayed consumption and recovery, but demands more storage. Consider the implications of message compaction and potential data fidelity loss. |
| Redpanda: An Alternative to Kafka | Redpanda has a modern and lightweight design that increases throughput with the same hardware resources. It also addresses the fundamental challenges associated with Kafka's log-based streaming mechanism, particularly those related to storage capacity management and data deletion. |
| Advantages of Redpanda over Kafka | - Efficient data deletion - Dynamic data replication - Buffer cache |
Factors affecting Kafka throughput
A Kafka cluster consists of multiple brokers, where each broker handles a subset of the overall load. The data (messages) are divided into smaller units known as partitions, which can be processed independently, thereby supporting parallel processing and enhancing throughput.
Moreover, Kafka achieves higher throughput by using a "zero-copy" methodology that directly transfers the bytes from the file system to the network buffer, bypassing the application buffer. This method significantly reduces the number of I/O operations and increases the rate at which messages are processed.
Several factors can impact Kafka's throughput:
Number of partitions
A higher number of partitions allows for further concurrency and increases the overall throughput. However, it also depends on how data is distributed across these partitions. An efficient partition strategy ensures that load is balanced across all partitions, preventing some from overloading while others remain idle.
In contrast, an excessive number of partitions may cause performance degradation due to increased overhead factors. These factors include augmented network traffic, the additional load on Apache ZooKeeper™, heightened metadata overhead, and elevated disk usage.
Configuration settings
Various settings like batch size, buffer memory, and compression settings can also impact the throughput. For example, the size of the messages being processed influences the throughput. Larger messages may require more resources to process, thereby reducing the throughput. The configuration of Kafka topics can also impact throughput, such as the number of replicas and the cleanup policy.
Hardware
The speed of the disk, the network, and the available CPU resources directly influence the throughput. Better hardware usually means better throughput.
[CTA_MODULE]
Kafka throughput trade-off: retention vs. storage
At the heart of Kafka's architecture is its infinite log-based streaming mechanism. This involves maintaining a continuously growing log of records that serve as the basis for message streaming. These records, or messages, are stored in topics, which are further divided into partitions across various brokers for parallel processing. Kafka consumers read these logs at their own pace, allowing for real-time as well as delayed consumption.
A significant feature of this mechanism is that Kafka does not automatically delete consumed messages. Instead, it keeps them for a configured retention period, enabling multiple consumers to read the same data independently and allowing for data reprocessing if required.
As data continues to stream in, Kafka's storage usage can increase dramatically, especially in high throughput data streaming scenarios. Kafka’s data retention policy, while beneficial for certain use cases, can become a burden in terms of managing storage resources and ensuring smooth performance.
Challenges with Kafka's data deletion
Given that Kafka retains all messages for a specified retention period (which could be infinite), managing storage is tricky. Consider a high throughput Kafka setup where millions of messages are being produced every minute. Given Kafka's data retention policy, these messages stay in the system until the retention period elapses. This continuous inflow and retention of messages can lead to rapid storage capacity exhaustion.
For instance, if your Kafka setup is processing a million messages per minute, and each message is 1KB in size, your storage requirements could potentially grow by approximately 1.4 TB per day. If your retention period is set to one week, that could mean almost 10 TB of storage is required just to keep up with message retention.
Common workarounds
To mitigate these storage challenges, several workarounds can be applied. One common strategy is configuring Topic Time-To-Live (TTL).
Kafka allows you to set a retention time for each topic. After the configured time period, the messages are automatically purged from the system, thereby freeing up storage space. However, this strategy requires careful planning, as once the data is deleted, it cannot be reprocessed. Determining the retention period is not a mere administrative decision but a strategic choice that impacts storage capacity, system performance, and overall operational costs.
Another workaround is to use compacted topics. A compacted topic in Kafka retains only the latest record for each message key, thereby reducing the storage requirement considerably. However, compacting messages can lead to a potential loss of data fidelity as all previous versions of a message for a particular key are discarded. This can be a significant drawback, especially for use cases where preserving the entire history of changes is crucial.

Impact on different consumers
The implications of trade-offs between data retention and storage capacity vary for different consumers, depending on their processing times and priorities. For consumers that process data in near real-time, a shorter data retention period suffices. They can maintain relatively lower storage capacities while still meeting their data consumption needs. These consumers might also benefit from compaction as it reduces the volume of data they need to process, while the latest state of each message key is likely to be the most relevant for their needs.
In contrast, consumers with delayed processing, perhaps due to complex computational requirements or low-priority tasks, may require longer retention periods. This ensures the data remains available when the consumer is ready to process it, but also means these consumers need to provision for higher storage capacities. For these consumers, compaction might also lead to crucial historical data being unavailable by the time they are ready to process it.
This variance in consumer requirements adds an additional layer of complexity to managing Kafka throughput. Therefore, it is essential for businesses to understand their data consumption patterns, processing requirements, and priorities to configure their Kafka setup optimally. Ultimately, the goal is to strike a balance that meets consumer needs while also managing storage resources effectively.
[CTA_MODULE]
How Redpanda handles Kafka throughput challenges
Redpanda is a streaming data platform that serves as a drop-in replacement for Kafka. However, it has its own unique features and improvements that make it stand out.
Redpanda operates within the same framework of a log-based data streaming system, but it has been designed to provide better performance and a more simplified user experience.
One of the distinctive features of Redpanda is its ability to lower latency and improve throughput with the same hardware resources, thanks to its modern and lightweight design. It addresses some of the fundamental challenges associated with Kafka's log-based streaming mechanism, particularly those related to storage capacity management and data deletion.
More efficient data deletion
Redpanda introduces a more efficient data deletion strategy. Rather than solely relying on topic-level configurations, Redpanda uses a segment-based approach. Each segment has its time-to-live (TTL), after which the data is automatically deleted, freeing up storage space.
Dynamic data replication
Redpanda optimizes disk space usage by taking a more dynamic approach to data replication. In Kafka, the storage footprint can triple due to mandatory replication for high availability. In contrast, Redpanda uses consensus replication, significantly reducing the storage footprint without compromising data durability or availability.
Buffer cache
Redpanda employs an intelligent buffer cache that proactively evicts data segments when storage is low, ensuring optimal use of storage resources.
By addressing these issues, Redpanda offers a promising alternative to Kafka, especially for organizations struggling with storage management and the delicate balance of data retention versus storage capacity.
Comparing Redpanda and Kafka
While both Kafka and Redpanda serve as data streaming solutions, they have distinctive features and performance characteristics that set them apart.
Throughput
Kafka is highly appreciated for its exceptional throughput capabilities. However, it's worth noting that Redpanda's design allows it to match and sometimes even exceed Kafka's throughput performance. Redpanda's lighter, no JVM footprint and optimized design contribute to its excellent performance.
Data retention
Kafka's data retention strategy, while useful for ensuring a comprehensive historical log, can lead to storage issues due to its infinite log-based streaming mechanism. Redpanda, on the other hand, addresses this by implementing a segment-based approach to data deletion, providing a more manageable balance between data retention and storage.
Storage capacity management
Kafka requires a significant amount of storage space, largely due to its replication strategy. Moreover, its data deletion strategy can lead to storage space exhaustion if not properly managed. Redpanda, by contrast, uses a more dynamic approach to data replication and an intelligent buffer cache, significantly reducing the storage footprint without compromising data durability.
Summary: comparison table
| Features | Kafka | Redpanda |
|---|---|---|
| Throughput | High | High, can exceed Kafka’s performance |
| Data retention | Infinite log-based streaming | Segment-based data deletion |
| Storage management | Requires significant storage, risk of exhaustion | Efficient replication and buffer cache, less storage use |
| Ease of use | Complex setup (requires JVM, ZooKeeper) | Simplified setup (no JVM, ZooKeeper dependencies) |
| Data replication | Triplicate replication for high availability | Consensus replication, less storage footprint |
Redpanda vs. Kafka throughput case studies
Various businesses across different sectors have recognized Redpanda's advantages and adopted them in their data streaming processes.
Lacework
Lacework, a cloud security services company, turned to Redpanda to manage its increasing data streaming demands. Redpanda provided a solution that excelled in scalability, reliability, and efficiency, handling Lacework's 14.5GB per second of data at peak loads and simplifying its operational processes. Additionally, Redpanda's flexible, cloud-agnostic nature proved critical for Lacework's future growth across multiple cloud providers.
Alpaca
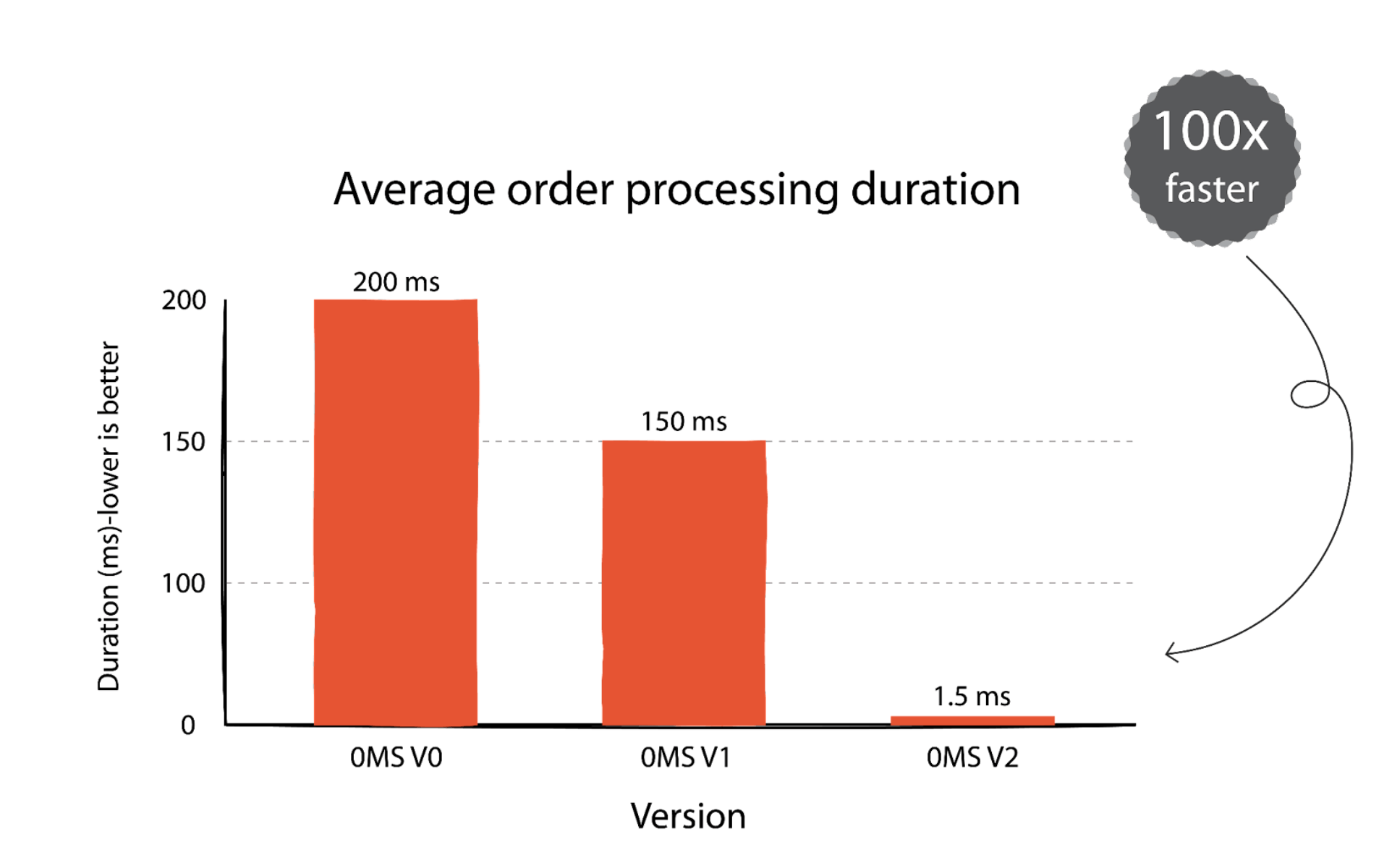
Alpaca has launched its new Order Management System (OMS v2), which dramatically improved order processing speed, achieving this increase in part through implementing Redpanda for their Distributed Write Ahead Log (WAL). Redpanda allows for efficient state recovery, and durability, and offers the opportunity for other services to consume trade and order events in a decoupled manner, contributing significantly to the enhanced system performance.
[CTA_MODULE]
Conclusion
While Kafka is an open-source and commonly used event-streaming platform, it's not without its challenges, especially when it comes to managing throughput. The inherent complexities of Kafka's architecture, combined with its storage and retention demands, can pose difficulties for businesses striving for optimal performance.
Enter Redpanda, a modern alternative tailored to overcome these very challenges. Redpanda eliminates many of Kafka's complexities, offering a streamlined approach designed to achieve lower latencies and higher throughput. Its innovative storage engine ensures minimal data loss, even in the face of hardware failures.
In the end, the choice isn't just about picking an event-streaming platform; it's about aligning with the future. For businesses seeking a blend of simplicity, high performance, and cost-efficiency, Redpanda emerges as a compelling choice. As always, making an informed decision requires understanding one's unique requirements, scale, and goals.
[CTA_MODULE]