




Drag, drop, done: a visual composer for Redpanda Connect
Boxes and arrows for people who move billions of events a day. No per-row invoice required.

Want to start streaming data with Redpanda? Here's a dev-friendly intro to kickstart your journey.








In today’s data-driven world, the ability to efficiently process and analyze real-time data streams is becoming increasingly crucial for building modern applications. Redpanda, a streaming platform built on the Apache Kafka® protocol, offers developers a simple, reliable, and scalable solution for handling high-volume streaming data.
As a Developer Advocate at Redpanda, I often get questions from developers like:
“What is Redpanda?”
“What does it do?”
“How does it solve my streaming data problem?”
“What APIs do you support for reading and writing data?”
The list goes on. The more questions I got, the more determined I was to write this post with clear-cut explanations of Redpanda and its capabilities.
Whether you’re new to streaming data or looking to expand your streaming capabilities, this comprehensive guide will equip you with the skills and knowledge to harness the full potential of Redpanda.
Let’s start from the top.
Redpanda is a cutting-edge streaming data platform designed to handle real-time data streams with exceptional performance and scalability. Built on the Kafka protocol, Redpanda delivers low-latency, high-throughput streaming data processing, making it ideal for building real-time applications and event-driven architectures.
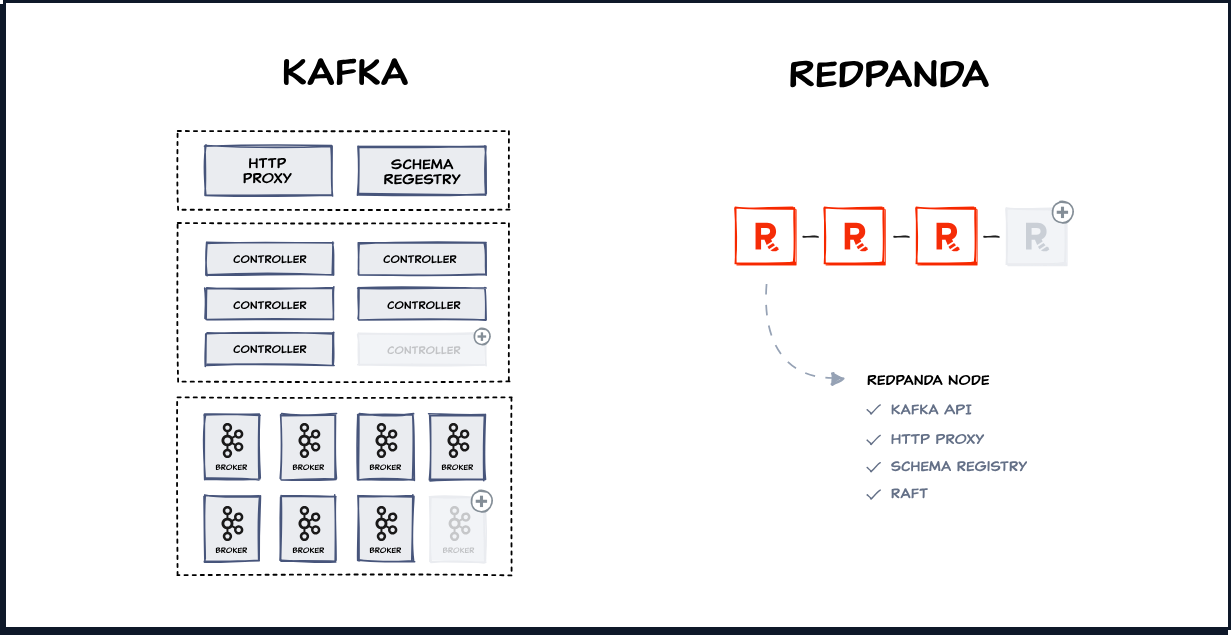
Written from scratch in C++, Redpanda uses a thread-per-core architecture for 10x lower latencies, deploys as a self-sufficient single binary (without the need for external dependencies like JVM and Apache ZooKeeper™), and is essentially a lighter, faster, and simpler to operate Kafka alternative.
To answer this question properly, we first need to define what streaming data is.
Streaming data is all about data streams — a continuous, never-ending data flow with no beginning or end. The data is incrementally made available over time so you can act upon it without having to download it first.
A data stream consists of a series of data points ordered in time, each representing an “event” or a change in the state of a system. For example, a stream of e-commerce orders, temperature sensor readings, or clicks on a website.
In an event-driven architecture, event streams flow from their producers to consumers in real time, allowing consumers to process events as they are received, enabling immediate analysis, insights, and responses.
Redpanda fits into this architecture as an event broker, providing the following benefits to producers and consumers.
Redpanda speaks the Kafka language — producers and consumers use Apache Kafka APIs to read from and write data to Redpanda.
If you have experience with Kafka, you’ll notice that Redpanda has all the same concepts, such as brokers, topics, partitions, segments, replicas, and more.
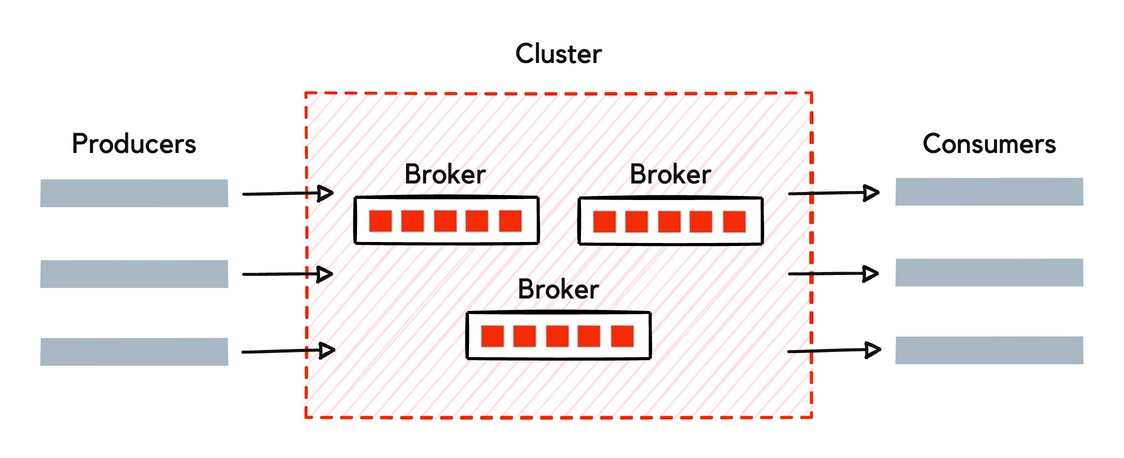
Producers are client applications that send data to Redpanda in the form of events. Redpanda safely stores these events in sequence and organizes them into topics, representing a replayable log of changes in the system.
Topics are partitioned and replicated across brokers in the cluster for scalability and high availability. Each event written to a partition is ordered and assigned with a unique offset — a monotonically increasing integer indicating an event’s relative position in the partition.
Consumers are client applications subscribing to Redpanda topics to read events asynchronously. A consumer fetches records from a partition from the last read offset.
Multiple consumers can form a consumer group, allowing them to simultaneously read from multiple partitions of the same topic without stepping on each other’s toes.
As a streaming data platform, Redpanda caters to multiple user personas, including developers, operators, data engineers, and architects.

Here’s a brief summary of how each of these personas can use Redpanda.
Application developers — Build, test, and deploy event-driven applications that produce and consume event streams to Redpanda. Event-driven microservices, real-time analytics applications, and real-time dashboards are popular use cases.
Data engineers — Create streaming ETL pipelines to transfer data between Redpanda and external systems. You can use existing data engineering tools to streamline the integration process. For example, Kafka Connect connectors are compatible with Redpanda, along with most stream processors, including Spark and Apache Flink, so you can transform, filter, and enhance streams in real time.
Operators/SREs — Configure, deploy and monitor Redpanda clusters in production. To streamline your workflow, use the deployment automation tools, such as Helm charts, Docker images, and Ansible/Terraform scripts.
Enterprise/solutions architects — Design large-scale, event-driven systems around Redpanda with reliability, cost-efficiency, and security in mind. Multi-AZ/DC Redpanda clusters, the cloud-first storage model, and flexible deployment options — including self-hosted, dedicated, and BYOC Redpanda clusters — are among your design choices.
Redpanda offers intuitive capabilities to help developers stay in control of their streaming data applications. Here’s what you can expect when using Redpanda.
Developers can leverage Kafka clients to produce and consume data from Redpanda. Clients developed for Kafka versions 0.11 or later are currently compatible. Modern clients auto-negotiate protocol versions or use an earlier version accepted by Redpanda brokers.
Clients for these programming languages have been validated at the time of this writing. Clients that haven’t been validated are still compatible, particularly those based on librdkafka. This compatibility enables Kafka developers a smooth migration path to Redpanda, as well as a seamless integration with existing Kafka client applications.
Redpanda nodes deploy as self-sufficient processes with built-in schema registry, HTTP proxy, Kafka API-compatible message, Raft-based data management, and control. They’re free from external dependencies like JVM, ZooKeeper, or KRaft servers.
Plus, a smaller compute footprint and fewer components mean instantaneous boot times, simpler CI/CD integration, and more reliable production environments.
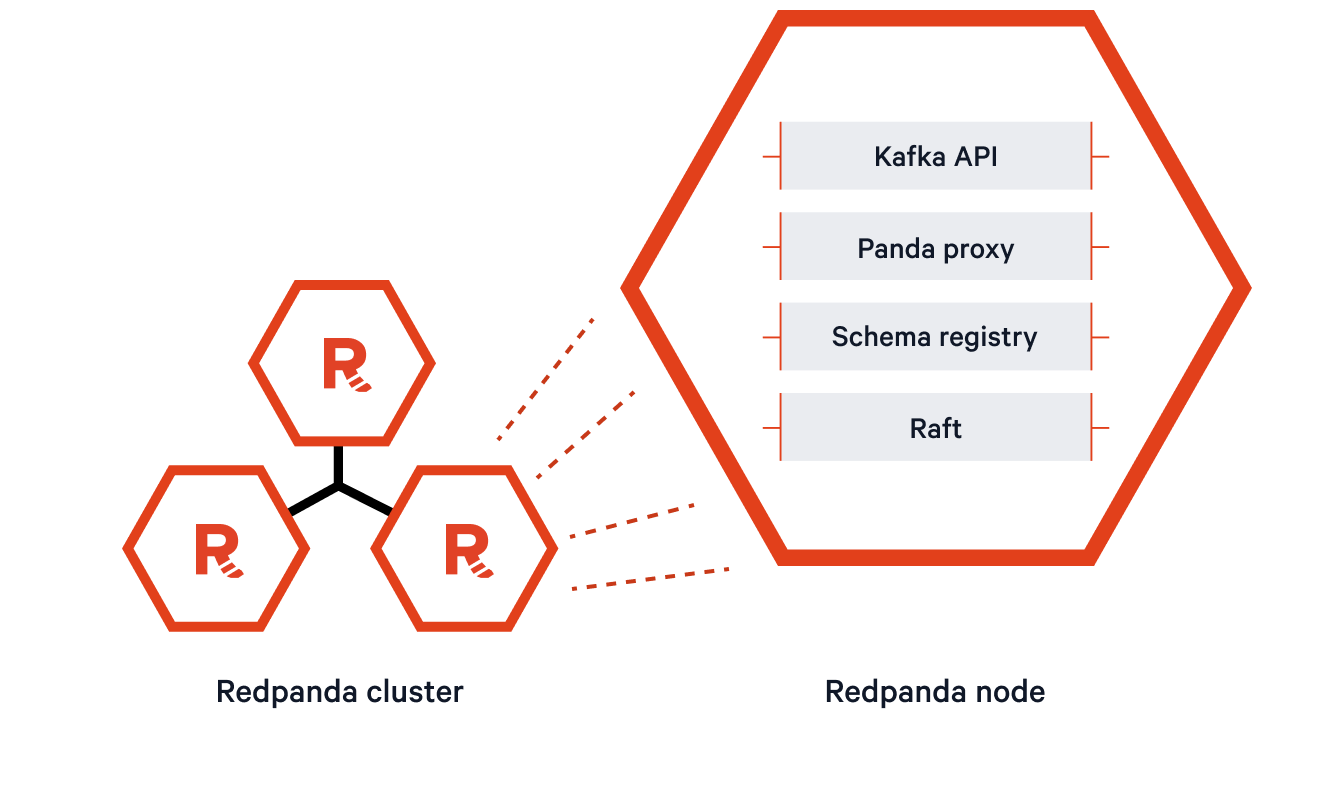
From a developer’s point of view, this single binary distribution simplifies deployment, enables easy upgrades, supports portability, and facilitates testing and development. These benefits empower developers to focus more on building robust streaming applications and less on managing complex infrastructure.
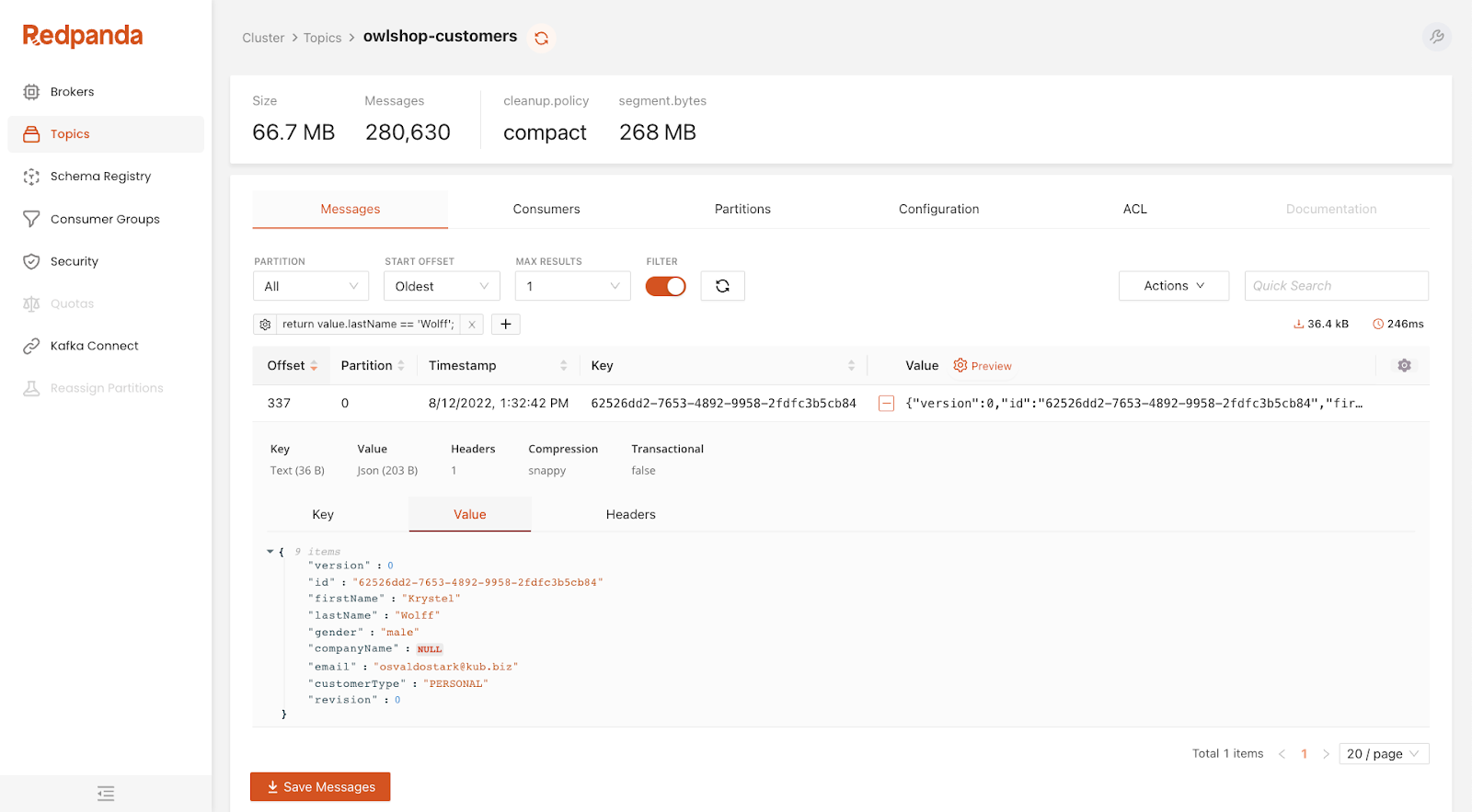
Redpanda Console is the web-based control plane for Redpanda. It provides a user-friendly interface for managing and monitoring Redpanda clusters.
The console streamlines common operational tasks, such as topic management, partition configuration, and replication settings. Additionally, it offers built-in monitoring and metrics functionality, enabling developers to track crucial performance indicators and identify potential issues in real time.
The console also allows browsing topics in a Redpanda cluster, allowing developers to filter messages and see their content, making troubleshooting and diagnostics easier for clients.
Redpanda Keeper (rpk) is a CLI utility, a single tool for managing the entire Redpanda cluster. It handles everything from low-level tuning to node configuration and tasks like topic creation.
Apache Kafka used to be the top streaming superpower, but as modern data demands continue to skyrocket, Kafka has now become synonymous with complex deployments and near-impossible scaling.
Redpanda was designed from the ground up with developers in mind. That means it’s purposefully built to be simpler to operate and manage while streaming data 10x faster using 6x fewer resources (compared to Kafka). And, since it’s a drop-in replacement for Apache Kafka, it works with the entire Kafka API ecosystem — no code changes needed.
Another significant factor to consider is Redpanda’s cloud-first storage for extra reliability, infinite data retention, and easier app development. Not to mention Redpanda’s thread-per-core architecture, which takes advantage of modern hardware features like memory-mapped files and kernel bypass networking for exceptional performance.
All of this makes Redpanda particularly attractive for latency-sensitive or high-performance use cases, like financial trading, AI and ML, retail, and IoT devices.
The bottom line is that while Kafka boasts a mature and extensive ecosystem, Redpanda offers a smarter, leaner alternative that’s ideal for environments where simplicity, performance, and ease of management are top priorities.
As the demand for real-time data processing continues to grow, Redpanda stands out as a lean and modern streaming platform that empowers developers to harness the potential of real-time data processing.
With its high-performance architecture, simplified operations, and drop-in compatibility with the Kafka ecosystem, Redpanda offers a compelling alternative to traditional streaming platforms for beginners and experienced professionals alike.
By understanding the fundamental concepts, exploring the advanced features, and leveraging developer-friendly tools, you can unlock the full potential of Redpanda to build robust and scalable streaming applications.
So take the first step on your streaming data journey and try Redpanda! You can find Redpanda Community Edition on GitHub or try Redpanda Cloud for free. Then go ahead and dive into the Redpanda Blog for examples and step-by-step tutorials.
If you get stuck or have questions, ask away in the Redpanda Community on Slack.
Subscribe to our VIP (very important panda) mailing list to pounce on the latest blogs, surprise announcements, and community events!
Opt out anytime.

