





Real-time Change Data Capture with Redpanda Connect and MySQL
Stream every insert, update, and delete from your database the moment it happens
Learn about nine different stream processing engines that you can configure to ingest events from Redpanda for stream processing.








Yes, Apache Flink, an open source framework for distributed stream processing, can be used with Redpanda for producing to and consuming from Kafka topics with exactly-once guarantees.
Kafka Streams is a client library for processing and analyzing data stored in a Kafka cluster. It provides a Domain Specific Language (DSL) for performing operations on streams, such as joins, filtering, aggregations, and windowing. While Kafka Streams was originally built for Kafka, it seamlessly integrates with Redpanda, enabling you to switch your existing Kafka Streams applications without code changes.
Apache Spark's high-level API, Structured Streaming, supports stream processing on continuous unbounded streams of data. It is well integrated with Apache Kafka, so it works seamlessly with Redpanda too. Structured Streaming extends the Spark SQL API to allow computation to be expressed in the same way as you would query a static RDD, but for streams.
ksqlDB is a database purpose-built for stream processing applications on top of Apache Kafka®. It combines a stream processor and a streaming database in a single system, enabling developers to build streaming applications with a SQL-like language. You can configure ksqlDB with Redpanda to build a wide variety of use cases. It can ingest events from a stream and turn that into a materialized view that updates incrementally as new events arrive.
Redpanda is a high-throughput, low-latency streaming data platform that can ingest data from various sources at scale. It works with stream processors, which are applications that consume data in a streaming fashion, apply transformations or computations on incoming data streams, and write the final output to Redpanda or another system, or trigger an action in real-time. Since Redpanda is compatible with Kafka APIs, all stream processing technologies that work with Kafka can seamlessly work with Redpanda as well.
Redpanda is a streaming data platform capable of high-throughput and low-latency data ingestion from data sources at scale. A stream processor is an application that consumes data in a streaming fashion, applies transformations or computations on incoming data streams, and writes the final output to Redpanda, a different system, or triggers an action in real-time.
You can find many stream processors today capable of consuming data from streaming data platforms such as Apache Kafka. Since Redpanda is compatible with Kafka APIs, all stream processing technologies working with Kafka can seamlessly work with Redpanda as well.
In this post, we will discuss nine stream processors that work with Redpanda to build different stream processing use cases.
The following is a high-level overview of the Redpanda’s stream processing ecosystem, featuring event producers, stream processors, and different data consumers as key building blocks.
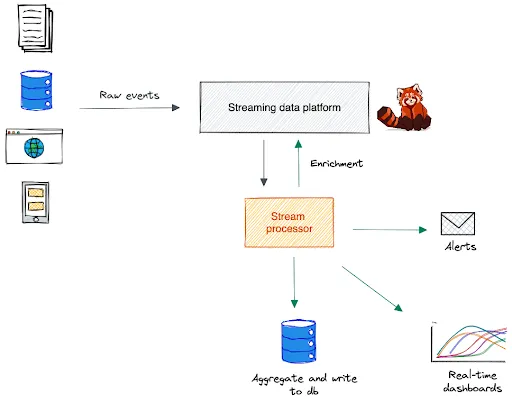
Event producers capture the real-time state changes that occur in source systems as “events''. For example, a new order was placed, a customer checked out from a hotel room, or an IoT sensor emitted a temperature reading; all represent events – immutable facts belonging to the past. Once captured, event producers publish them to Redpanda immediately.
Stream processors subscribed to Redpanda topics can consume these events as a stream – a time-ordered never ending flow of events, allowing you to process them without waiting for the entire data set. You can program the stream processor to apply a set of operations/functions on the incoming stream. They can vary between stateless operations like mapping and filtering, or stateful operations like aggregations and windowing.
You can think of stream processing as a directed acyclic graph (DAG) of operators as follows.

The processed output of the stream processor is written to Redpanda, a different system, or used to trigger an alert for further human intervention. For example, a stream processor can aggregate temperature readings for the past five minutes and trigger an alarm, if the average temperature exceeds a specified threshold. Examples for popular stream processing use cases are as follows:
Let’s discuss several stream processors that work with Redpanda. Each technology mentioned here is tried and tested against Redpanda. You can follow the accompanying blog post or the YouTube video for more information.
Kafka Streams is a client library for processing and analyzing data stored in a Kafka cluster, where in the input and output data can reside on different Kafka topics. While you can achieve the same with standard Kafka producer and consumer APIs, Kafka Streams goes beyond them and provides the core API for stream processing on the JVM, supporting languages like Java, Scala, Clojure, etc.
Kafka Streams provides developers with a Domain Specific Language (DSL) to perform operations on streams, such as joins, filtering, aggregations, and windowing in a declarative manner. While Kafka Streams was originally built with Kafka in mind, it seamlessly integrates with Redpanda as well, enabling you to switch your existing Kafka Streams applications without code changes.
To read more about Redpanda and Kafka Streams integration, visit the following blog post.
How to integrate Kafka Streams with Redpanda
ksqlDB is a database purpose-built for stream processing applications on top of Apache Kafka®. ksqlDB combines a stream processor and a streaming database in a single system, enabling developers to build streaming applications with a SQL-like language. It leverages the existing Kafka ecosystem components – Kafka ConnectⓇ and Kafka StreamsⓇ to bring data from different sources, process them, and send the output to different systems.
ksqlDB can ingest events from a stream and turn that into a materialized view that updates incrementally as new events arrive. You can query these materialized views using SQL, as if you were querying a database table. Its ability to manipulate streams with SQL benefits many developers to build streaming applications in a language-neutral environment.
You can configure ksqlDB with Redpanda in a seamless manner to build a wide variety of use cases. The following blog post walks you through the process of creating a materialized view with Redpanda and ksqlDB.
How to use ksqlDB and Redpanda to build a materialized cache.
Apache Flink is a framework and distributed stream processor for stateful computations over unbounded and bounded data streams. That means Flink can process continuous unbounded data streams (stream mode) as well as finite data sets as batches (batch mode).
Flink is a distributed system, requiring you to deploy a Flink cluster on multiple nodes. As a developer, you write a stream processing logic as a Flink application and deploy it on a Flink cluster. Flink provides several programming interfaces for developers, including Java and Python APIs, and an SQL interface.
The Connectors in Flink enables reading data from and writing data to external systems. The Kafka connector integrates Flink with Apache Kafka for producing to and consuming from Kafka topics with exactly-once guarantees. You can use the same connector for Redpanda integration as well.
For more information about Redpanda and Flink integration, you can refer to the following blog post.
Building a real-time word count application using Apache Flink and Redpanda
Apache SparkⓇ is a stream processing framework originally built to address the limitations of the MapReduce algorithm by allowing functions to be executed iteratively on a Resilient Distributed Dataset (RDD), which is an abstraction of a dataset that is logically partitioned and cached in memory on many machines. Over the years Spark has evolved to include further abstractions on top of the core RDD concept, including Spark SQL, MLLib, and Spark Streaming®.
Besides its speed, Apache Spark has a high-level API called Structured StreamingⓇ, which extends the core Spark API to support stream processing on continuous unbounded streams of data. Internally, a stream is divided into micro-batches (sequence of RDDs) that are continuously processed by the Spark engine to generate batches of results. Furthermore, Structured Streaming extends the Spark SQL API to allow computation to be expressed in the same way as you would query a static RDD, but for streams. That way, you would query a stream and a static data set with the same API abstraction.
Spark Structured Streaming is well integrated with Apache Kafka, so it works seamlessly with Redpanda too. For more information on Redpanda and Spark integration, you can refer to the following blog posts.
Using Spark Streaming and Redpanda for real-time data analytics
Structured stream processing with Redpanda and Apache Spark
Materialize is a fast, distributed SQL database built on the Timely Dataflow programming model.
Similar to ksqlDB, Materialize is also capable of building a materialized view from a stream and updating it incrementally as new data comes.
Materialize is wire-compatible with Postgres and allows you to write streaming processing applications with standard SQL. Compute and storage separation, active replication, multi-way SQL joins, and low-latency makes Materialize stand out from the crowd.
Materialize provides a built-in Kafka source for streaming data ingestion from Kafka, which you can use for Redpanda as well. For more information on Redpanda and Materialize integration, you can refer to the following blog post and the YouTube video.
Using Materialize and Redpanda for real-time IoT data streaming
Materialize and Redpanda Community Meetup
Bytewax is an up-and-coming data processing framework that is built on top of Timely Dataflow, which is a cyclic data flow computational model. At a high-level, dataflow programming is a programming paradigm where program execution is conceptualized as data flowing through a series of operator based steps.
Although the Timely Dataflow library is written in Rust, it provides a binding for Python, allowing you to process streams within a Python consumer itself. For example, you can use a Python client for Kafka for data ingestion and feed them to Bytewax for stream processing. Same code will work for Redpanda as well.
For more information on Redpanda and Bytewax integration, you can refer to the following blog post.
Building an anomaly detection application with Redpanda and Bytewax
Timeplus is a real-time analytics platform, capable of providing low-latency stream processing on both streaming and historical data. It is available as a hosted SaaS platform and leverages SQL for writing stream processing logic. Timeplus Cloud provides you with extended support for data ingestion from streaming sources such as Kafka and Redpanda, also the built in support data visualization as well.
For more information on Redpanda and Timeplus integration, you can refer to the following blog post and the YouTube video.
Realizing low latency streaming analytics with Timeplus and Redpanda
Timeplus Redpanda Integration Demo
Faust is a stream processing library, porting the ideas from Kafka Streams to Python. Faust natively integrates with Kafka for streaming data ingestion and allows you to write stream processing logic in your Python application. That means you can use all your favorite Python libraries when stream processing: NumPy, PyTorch, Pandas, NLTK, Django, Flask, SQLAlchemy, and more.
Faust utilizes RocksDB for state persistence, which is a key-value store written in C++ that is optimized for lightning-fast performance. That enables you to perform stateful operations on an abstraction called a "table," which is a named and distributed collection of key-value pairs which you can interface with regular dictionaries from Python.
For more information on Redpanda and Faust integration, you can refer to the following blog post.
Stream processing with Redpanda and Faust
Benthos is an open source stream processor that provides data mapping, filtering, hydration and enrichment capabilities across a wide range of connectors. It is driven by a minimal, declarative configuration spec, and with a transaction based architecture it eliminates the development effort of building resilient stream processing pipelines.
Written in Go and deployed as a static binary, Benthos allows you to define the stream processing logic with a declarative configuration (in YAML).
For more information on Redpanda and Benthos integration, you can refer to the following blog post.
We're bringing simple back (to streaming)
In this post, you learned a list of stream processing technologies that seamlessly integrate with Redpanda. This list is supposed to grow in future as more Kafka-compatible stream processors come in. Its high performance, operational simplicity, and Kafka compatibility make Redpanda as the best data source for your stream processing workloads.
Take Redpanda for a test drive here. Check out our documentation to understand the nuts and bolts of how the platform works, or read our other blogs to see the plethora of ways to integrate with Redpanda. To ask our Solution Architects and Core Engineers questions and interact with other Redpanda users, join the Redpanda Community on Slack.
Subscribe to our VIP (very important panda) mailing list to pounce on the latest blogs, surprise announcements, and community events!
Opt out anytime.

