




Stream Oracle changes to ClickHouse in real time with Redpanda Connect
A hands-on walkthrough of our new Oracle CDC connector
How Fortis Games is building a developer-friendly games data platform focused around self-service using Redpanda, Flink, ClickHouse, and Iceberg









Redpanda uses Prometheus natively for monitoring, making it simple for developers to scrape the data they need from the cluster without having to request custom data pulls. This feature aligns with the belief that data subsystems should act like a utility where developers can put data in and know that it will work.
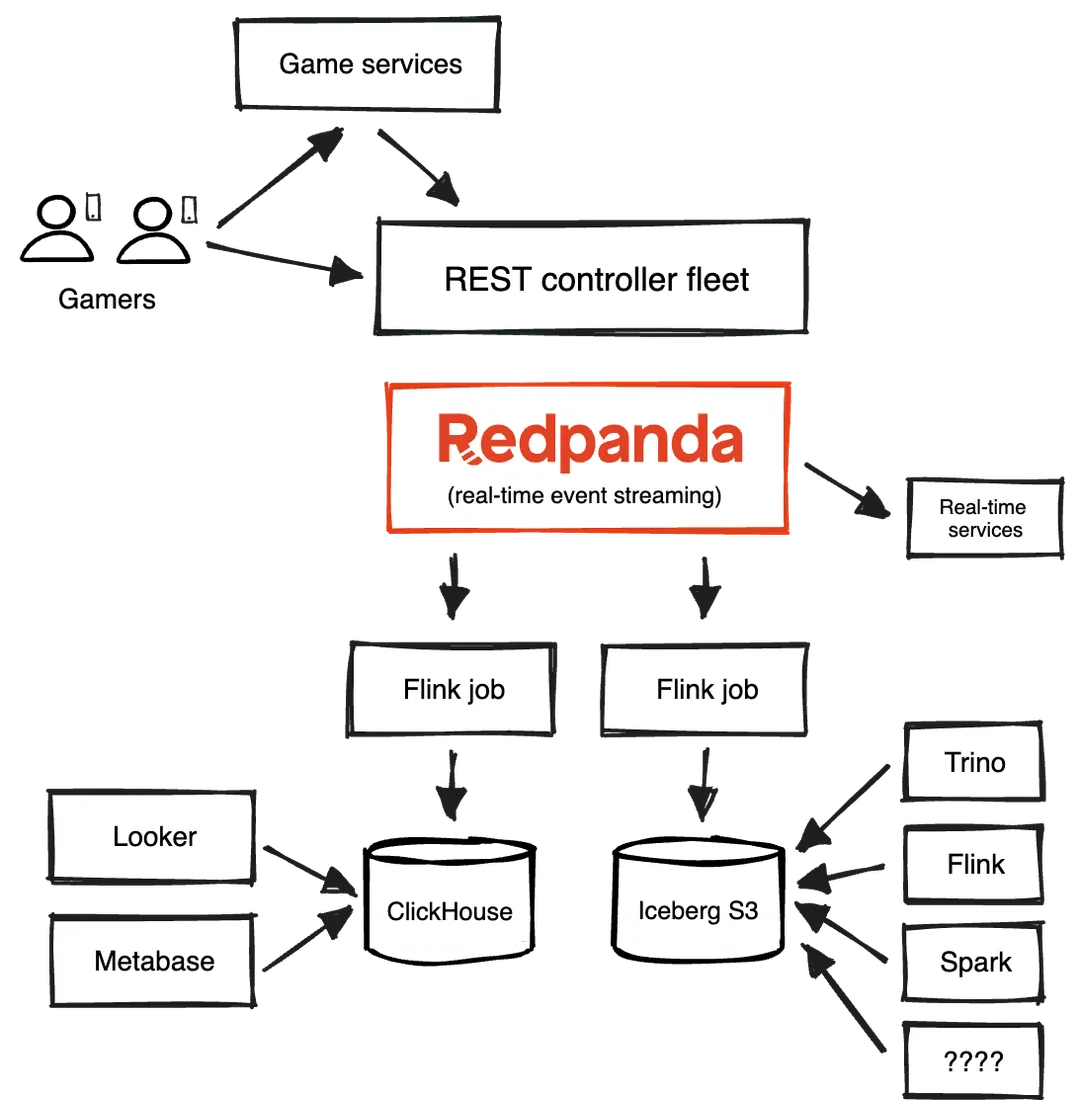
Developers use an analytics SDK provided by Fortis Games, which enables them to send game telemetry of any kind to a REST fleet of servers that can accept HTTP POST. This data is then immediately sent to Redpanda with a linger time of less than 100 milliseconds. The data streams in Redpanda are processed in real time using Apache Flink® and written to a ClickHouse data warehouse for online data analytics. The real-time data is also sent to a data lake using Apache Iceberg, where it can be analyzed using Spark jobs, custom Flink jobs, and big SQL queries.
Redpanda's BYOC deployment model provides a fully managed service for cluster administration, including automatic upgrades, built-in connectors, and 24x7 support, while allowing Fortis Games to retain complete control over their data and infrastructure inside their own VPC (virtual private cloud). This model simplifies the process for end users, the game developers, making it easier for them to access the data they need from the cluster.
Fortis Games is building a data platform that is "game-agnostic" and can support any new game in development, regardless of the data needs. The platform is designed to be self-service for game developers, allowing them to plug directly into the stack using data formats and protocols they're already familiar with. The aim is to improve gameplay experience without developers having to understand the backend infrastructure.
Fortis Games chose Redpanda for its performance, stability, and scalability. The design choices of Redpanda, such as a C++ and thread-per-core architecture, tiered cloud storage, and a Raft-based consensus system, resonated with the data engineering team at Fortis Games. Redpanda also eliminates the administrative overhead generally associated with Kafka solutions, making it easy to deploy, manage, and scale.
At Fortis Games, we’re focused on creating new games for mobile, PC, and console where players belong, that challenge their minds, build connections and inspire communities. To deliver that experience, we personalize player experiences by tapping into real-time game data—and this requires us to have a scalable, flexible, fast, and developer-friendly data infrastructure.
Our data team is highly seasoned and has worked on AAA blockbuster games, supporting data pipelines built on the likes of Apache Kafka® and Confluent. When we came to Fortis, we opted to build our fresh new real-time data infrastructure on Redpanda, a streaming data platform that gives us Kafka compatibility but without the usual pains of Kafka management.
In this post, we’ll provide a look at how our data team designed a games data platform that would provide everything our developers need to create games where players belong, without having to know a thing about the backend infrastructure.
Fortis is building games for multiple different platforms and play styles, and so first and foremost, we wanted to create a data platform that was “game-agnostic” and could support any new game in development, regardless of the data needs. This goes against the grain of the traditional approach in the games industry, where each game or studio within a publisher might have its own, tailored data infrastructure.
In our experience, that kind of siloed approach slows things down, because game developers within the same publisher have to work with different data teams and different pipelines to get what they need to improve gameplay experience. As a player-first company, we can’t afford those high latencies in gamer satisfaction.
We also needed our data platform to be self-service for game developers, so they can plug directly into the stack using data formats and protocols that they’re already familiar with. We don’t want our game developers to even have to pronounce “Kafka,” let alone have to think about how it works: A developer should be able to easily send freeform JSON to the platform where it can be pushed downstream for real-time analytics and dashboards, or used in event-driven applications such as leaderboards.
For example, the developer might want to create real-time dashboards to understand contextual information about players — items they accumulated, areas of the map they tend to hang out in, the accuracy they have with various weapons, etc. — so they can make smarter decisions that improve the game.
Factors such as engagement rates on new game elements, the impact of new patches, and whether certain weapons are overpowered can all be rapidly incorporated into game development, which helps Fortis keep its player base happy.
To support these requirements, we built a highly scalable, flexible, high-performance, and easy-to-use data platform using Redpanda.
Here’s how it works. Our developers use an analytics SDK we provide, which enables them to send game telemetry of any kind to a REST fleet of servers that can accept HTTP POST. This uniform data about game events is loosely verified (What game is it? Timestamp? Event name? Player ID?) and then immediately sent to Redpanda with a linger time of less than 100 milliseconds.
The data streams in Redpanda are processed in real time using Apache Flink® and written to a ClickHouse data warehouse for online data analytics. ClickHouse allows us to store all data from all games in a landing table where we can run game-specific and event-specific lookups that are insanely fast. The real-time data is also sent to a data lake using Apache Iceberg, where it can be analyzed using Spark jobs, custom Flink jobs, and big SQL queries, such as for eight-month aggregations of events.
Redpanda provides the simplicity, scale, and speed that form the foundation of our real-time data infrastructure. We have tested the data platform for up to 100 million users with zero performance blips. And because Redpanda is Kafka compatible, it “just works” with the great ecosystem tools we already love like Flink and Apache Spark™. By combining Redpanda with other best-of-breed tools like ClickHouse and Iceberg, we have created a modern real-time analytics platform that can support our game developers today and many years into the future.
So you may be thinking, this all sounds great, but why did you choose Redpanda specifically for your streaming data engine, when there are tried and tested tools like Apache Kafka out there? Let’s go through the reasons.
At Fortis Games, we’re building for the future of the games industry, and we want to use the best-of-breed solutions out there that can scale as our requirements grow and evolve. We don’t want to make compromises. We were impressed with how the Redpanda engineers obsess and the attention they paid to performance and stability, doing whatever they need to shave microseconds off a single CPU call.
As the Principal Data Engineer at Fortis Games, the design choices of Redpanda founder Alex Gallego resonated with me: a C++ and thread-per-core architecture that squeezes every drop of performance out of hardware, which makes all the difference for our p99s (not to mention reducing our infra bill); tiered cloud storage that enables us to retain data long term without performance loss, and a Raft-based consensus system that is easy to understand and helps us ensure zero data loss.
Second, we knew the pains of managing Kafka and Confluent firsthand and wanted a solution that eliminated the administrative overhead generally associated with Kafka solutions. In other words, we didn’t want to tune a JVM (Java virtual machine) ever again!
In fact, I myself had suffered many sleepless nights at my previous game publisher, trying to get Kafka and Confluent to handle the scale of a million-person live service with 100GB/min throughput and peaks of 100K transactions per second. Inevitably, these solutions resulted in late-arriving data that could add up to seconds if not minutes, which was detrimental to the online systems I owned the service-level objectives (SLOs) for. No way was I going through that again.
Fortunately, Redpanda removes 90% of the headaches of Kafka, because it’s so easy to deploy, manage and scale. As a single binary, Redpanda bypasses the external dependencies and components that make Kafka overly complex, like the JVM and Apache ZooKeeper™. With Redpanda, we don’t have to deal with any of those tiresome relics of Kafka’s 12-year-old design, like Linux page caching or garbage collection.
Plus, Redpanda’s BYOC (bring your own cloud) deployment model gives us a fully managed service for cluster administration — including automatic upgrades, built-in connectors, and 24x7 support — while retaining complete control over our data and infrastructure inside our own VPC (virtual private cloud).
Redpanda also translates to simplicity for our end users, the game developers. For example, because Redpanda uses Prometheus natively for monitoring, it’s simple for developers to scrape the data they need from the cluster without having to request custom data pulls via Slack.
I believe that data subsystems should act like a utility and you shouldn’t have to think about brokers and partitions. You should just be able to put data in and know that it will work. Redpanda gives us that confidence — and it means I don’t get roused from my sleep or a night out with friends because something went wrong with a Kafka cluster.
At Fortis Games, we are building games that are going to redefine player-driven experiences, and a big part of how we deliver that is in how we leverage real-time data.
That means our streaming data engine is a critical infrastructure asset. Redpanda gives us a strong, reliable foundation to build a data platform for the future of games and players. It also does this while helping us to control costs as we scale. For example, Redpanda runs on approximately one-third the compute resources as Kafka, which saves us infrastructure costs right out of the gate.
Plus, Redpanda BYOC’s data sovereignty model lets us leverage our existing discounts with our cloud service provider, something we can’t get from other Kafka vendors. All in all, Redpanda is costing us about one-quarter of what we would be paying with a standard Kafka solution, due to its high resource efficiency and flexible deployment options.
As a data engineer, I put a lot of stock into the hard work of other engineers who are building software that makes life easier for developers. Redpanda is just that type of software: It’s simple, it has a high-performance design that saves us time and money, and it’s extremely reliable at scale. We’re looking forward to riding the real-time data waves with Redpanda to our next 100 million players and beyond.
For more stories about how Redpanda has helped companies stream data easier and at lower cost, check out our customers page. If you haven’t already, try Redpanda and join the Redpanda Community on Slack to chat directly with our team.
------ Originally published on The New Stack. ------
Subscribe to our VIP (very important panda) mailing list to pounce on the latest blogs, surprise announcements, and community events!
Opt out anytime.

