





Full CDC semantics land in the Iceberg output for Redpanda Connect
Your lakehouse mirrors the database, instantly.

Switching from Kafka to Repanda is easier than you think. In this post, Pathway proves it with an example video-on-demand platform.








Switching from Kafka to Redpanda is straightforward. First, replace Kafka and ZooKeeper services with a Redpanda service in your Docker setup. Then, update the server's address in the settings to connect Pathway and the stream producer to Redpanda. You can also use dedicated Redpanda connectors for consistency. Lastly, update the server name for the stream generator. Note that Redpanda discards incoming messages while a topic is being created.
This blog outlines a few steps to implement a data streaming solution with Kafka. First, you need to configure Kafka and ZooKeeper. Then, generate the data stream using a Python script to read a CSV file and send each rating to Kafka using the kafka-python package. Next, connect Pathway to Kafka and process the data. Finally, run the results and update the rankings whenever a new rating changes the top results.
Sending results back to Redpanda instead of a CSV file is more efficient for handling data streams. It also allows the data to be accessible to everyone in the organization in real time. Redpanda is optimized for handling data streams, making it a more suitable solution than sending data in a CSV file.
Redpanda is considered a "drop-in replacement" for Kafka because it is fully Kafka API-compatible. There are no new binaries to install, no new services to deploy and maintain, and the default configuration just works. If the server name remains the same, you don't need to change your Pathway code.
This is usually done with data science functions trained on large amounts of data to be accurate enough to make decisions on. But the brainiacs over at Pathway have cracked the nut on doing the same thing with small amounts of data, in real time, against streaming data coming directly from Apache Kafka®. The same code base can be used for event-driven and microbatch architectures in Pathway.
Pathway loved the idea of having a smaller footprint at mega scale and faster performance, but first wanted to confirm whether Redpanda truly is a "drop-in replacement" for Kafka. So, we put it to the test.
In this post, we walk you through a practical example of using Pathway on both Apache Kafka and Redpanda to show just how easy it is to make the switch. If you want to replicate this yourself, you can find the source code in this GitHub repository.
Picture this: you’ve just been hired by a trendy video-on-demand (VOD) platform. Your first task is to identify the most popular movies in the catalog. Specifically, you want to find the K movies with the highest scores and see how many ratings those movies received.
For example, this is what the expected table for K=3 could be:
MovieID
Average
RatingNumber
218
4.9
7510
45
4.8
9123
7456
4.8
1240
The ratings are received as a data stream through a Kafka instance, and you output the table to a CSV file.
We’ll need the following components:
Each component will be hosted in a different docker container. The stream producer sends the ratings to Kafka on the topic ratings. Pathway listens to the topic, processes the stream, and then outputs the ranking in a CSV file best_rating.csv.
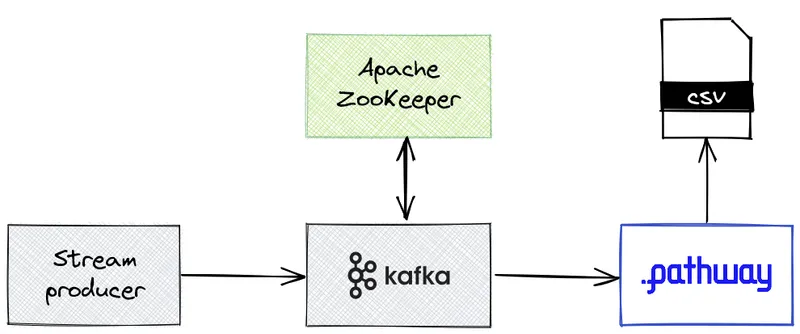
Pathway and the stream generator have their own Dockerfile to install all the required dependencies. The stream is then created by streaming the lines of a static data dataset.csv.
This will be the structure of our project:
├── pathway-src/
│ ├── Dockerfile
│ └── process-stream.py
├── producer-src/
│ ├── create-stream.py
│ ├── dataset.csv
│ └── Dockerfile
├── docker-compose.yml
└── MakefileKafka and ZooKeeper are configurable in the docker-compose.yml file. To keep things simple, we can skip the security mechanisms.
// docker-compose.yml
version: "3.7"
name: tuto-switch-to-redpanda
networks:
tutorial_network:
driver: bridge
services:
zookeeper:
image: confluentinc/cp-zookeeper:5.5.3
environment:
ZOOKEEPER_CLIENT_PORT: 2181
networks:
- tutorial_network
kafka:
image: confluentinc/cp-enterprise-kafka:5.5.3
depends_on: [zookeeper]
environment:
KAFKA_AUTO_CREATE_TOPICS: true
KAFKA_ZOOKEEPER_CONNECT: "zookeeper:2181"
KAFKA_ADVERTISED_HOST_NAME: kafka
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka:9092
KAFKA_BROKER_ID: 1
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
KAFKA_JMX_PORT: 9991
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT
KAFKA_INTER_BROKER_LISTENER_NAME: PLAINTEXT
CONFLUENT_SUPPORT_METRICS_ENABLE: false
ports:
- 9092:9092
command: sh -c "((sleep 15 && kafka-topics --create --zookeeper zookeeper:2181 --replication-factor 1 --partitions 1 --topic ratings)&) && /etc/confluent/docker/run "
networks:
- tutorial_networkHere we’re sending the messages to a topic called ratings, created in the command setting.
We start with a CSV dataset with the following columns: userId (int), movieId (int), rating (float), and timestamp (int). This is the schema chosen by GroupLens for their MovieLens25M dataset: we provide a toy dataset as an example, but the project will work with the whole MovieLens25M dataset.
To generate the stream, you can use a simple Python script to read the CSV file line by line, and each rating will be sent to Kafka using the kafka-python package.
// ./producer-src/create-stream.py
import csv
import json
import time
from kafka import KafkaProducer
topic = "ratings"
#We wait for Kafka and ZooKeeper to be ready
time.sleep(30)
producer = KafkaProducer(
bootstrap_servers=["kafka:9092"],
security_protocol="PLAINTEXT",
api_version=(0, 10, 2),
)
with open("./dataset.csv", newline="") as csvfile:
dataset_reader = csv.reader(csvfile, delimiter=",")
first_line = True
for row in dataset_reader:
# We skip the header
if first_line:
first_line = False
continue
message_json = {
"userId": int(row[0]),
"movieId": int(row[1]),
"rating": float(row[2]),
"timestamp": int(row[3]),
}
producer.send(topic, (json.dumps(message_json)).encode("utf-8"))
time.sleep(0.1)
producer.send(topic, "*COMMIT*".encode("utf-8"))
time.sleep(2)
producer.close()Note that we connect to kafka:9092 and not localhost.
This script will have its own container:
// docker-compose.yml
stream-producer:
build:
context: .
dockerfile: ./producer-src/Dockerfile
depends_on: [kafka]
networks:
- tutorial_networkYou only need to use a Python image and install the associated package:
// ./producer-src/Dockerfile
FROM python:3.10
RUN pip install kafka-python
COPY ./producer-src/create-stream.py create-stream.py
COPY ./producer-src/dataset.csv dataset.csv
CMD ["python", "-u", "create-stream.py"]Now you have a stream generated from the dataset and sent to Kafka. At this point, you simply need to connect Pathway to Kafka and process the data.
To connect to Kafka, configure the connection:
// ./pathway-src/process-stream.py
rdkafka_settings = {
"bootstrap.servers": "kafka:9092",
"security.protocol": "plaintext",
"group.id": "0",
"session.timeout.ms": "6000",
}To establish a more secure connection using a SASL-SSL authentication over a SCRAM-SHA-256 mechanism, you can do the following:\
// ./pathway-src/process-stream.py
rdkafka_settings = {
"bootstrap.servers": "server:9092",
"security.protocol": "sasl_ssl",
"sasl.mechanism": "SCRAM-SHA-256",
"group.id": "$GROUP_NAME",
"session.timeout.ms": "6000",
"sasl.username": "username",
"sasl.password": "********"
}Connect to the ratings topic using a Kafka connector:
// ./pathway-src/process-stream.py
t_ratings = pw.kafka.read(
rdkafka_settings,
topic_names=["ratings"],
format="json",
value_columns=[
"movieId",
"rating",
],
types={"movieId": pw.Type.INT, "rating": pw.Type.FLOAT},
autocommit_duration_ms=100,
)You’re only interested in the movieId and rating columns, so there’s no need to include the others. Now, define a function to find the best-rated movies:
def compute_best(t_ratings, K):
t_best_ratings = t_ratings.groupby(pw.this.movieId).reduce(
pw.this.movieId,
sum_ratings=pw.reducers.sum(pw.this.rating),
number_ratings=pw.reducers.count(pw.this.rating),
)
t_best_ratings = t_best_ratings.select(
pw.this.movieId,
pw.this.number_ratings,
average_rating=pw.apply(
lambda x, y: (x / y) if y != 0 else 0,
pw.this.sum_ratings,
pw.this.number_ratings,
),
)
t_best_ratings = t_best_ratings.select(
movie_tuple=pw.apply(
lambda x, y, z: (x, y, z),
pw.this.average_rating,
pw.this.number_ratings,
pw.this.movieId,
)
)
t_best_ratings = t_best_ratings.reduce(
total_tuple=pw.reducers.sorted_tuple(pw.this.movie_tuple)
)
t_best_ratings = t_best_ratings.select(
K_best=pw.apply(lambda my_tuple: (list(my_tuple))[-K:], pw.this.total_tuple)
)
t_best_ratings = flatten_column(t_best_ratings.K_best).select(
pw.this.K_best
)
t_best_ratings = t_best_ratings.select(
movieId=pw.apply(lambda rating_tuple: rating_tuple[2], pw.this.K_best),
average_rating=pw.apply(lambda rating_tuple: rating_tuple[0], pw.this.K_best),
views=pw.apply(lambda rating_tuple: rating_tuple[1], pw.this.K_best),
)
return t_best_ratingsUsing the function, your final file will look like this:
// ./pathway-src/process-stream.py
import pathway as pw
import time
rdkafka_settings = {
"bootstrap.servers": "kafka:9092",
"security.protocol": "plaintext",
"group.id": "0",
"session.timeout.ms": "6000",
}
t_ratings = pw.kafka.read(
rdkafka_settings,
topic_names=["ratings"],
format="json",
value_columns=[
"movieId",
"rating",
],
types={"movieId": pw.Type.INT, "rating": pw.Type.FLOAT},
autocommit_duration_ms=100,
)
t_best_ratings = compute_best(t_ratings, 3)
# We output the results in a dedicated CSV file
pw.csv.write(t_best_ratings, "./best_ratings.csv")
# We wait for Kafka and ZooKeeper to be ready
time.sleep(20)
# We launch the computation
pw.run()Set up a dedicated container:
// docker-compose.yml
pathway:
build:
context: .
dockerfile: ./pathway-src/Dockerfile
depends_on: [kafka]
networks:
- tutorial_network// ./pathway-src/Dockerfile
FROM python:3.10
RUN pip install --extra-index-url https://packages.pathway.com/966431ef6b789140248947273e541114f6679aa3436359bb5d67064b5693047a90ec699d6a pathway
COPY ./pathway-src/process-stream.py process-stream.py
CMD ["python", "-u", "process-stream.py"]Use the following toy dataset:
// ./producer-src/dataset.csv
userId,movieId,rating,timestamp
1,296,5.0,1147880044
1,306,3.5,1147868817
1,307,5.0,1147868828
1,665,5.0,1147878820
1,899,3.5,1147868510
1,1088,4.0,1147868495
2,296,4.0,1147880044
2,306,2.5,1147868817
2,307,3.0,1147868828
2,665,2.0,1147878820
2,899,4.5,1147868510
2,1088,2.0,1147868495
3,296,1.0,1147880044
3,306,2.5,1147868817
3,307,4.0,1147868828
3,665,2.0,1147878820
3,899,1.5,1147868510
3,1088,5.0,1147868495You should get the following results:
movieId,average_rating,views,time,diff
296,5,1,1680008702067,1
306,3.5,1,1680008702167,1
[...]
296,3.3333333333333335,3,1680008703767,-1
1088,3.6666666666666665,3,1680008703767,1
296,3.3333333333333335,3,1680008703767,1
899,3.1666666666666665,3,1680008703767,-1As expected, the top three results are updated whenever the ranking changes due to a new rating.
Congratulations! You can now find the K best-rated movies on your VOD platform. However, your team has discovered a new alternative to Kafka: Redpanda—which is known for being simpler, faster, and more cost-effective.
With Redpanda, the project is straightforward. All you need is:

Let's see how to deploy Redpanda in Docker and how it impacts your project.
(You can skip this section if you already have an existing Redpanda instance)
First, remove the two services kafka and zookeeper, and replace them with a redpanda service:
// ./docker-compose.yml
services:
redpanda:
command:
- redpanda
- start
- --kafka-addr internal://0.0.0.0:9092,external://0.0.0.0:19092
- --advertise-kafka-addr internal://redpanda:9092,external://localhost:19092
- --pandaproxy-addr internal://0.0.0.0:8082,external://0.0.0.0:18082
- --advertise-pandaproxy-addr internal://redpanda:8082,external://localhost:18082
- --schema-registry-addr internal://0.0.0.0:8081,external://0.0.0.0:18081
- --rpc-addr redpanda:33145
- --advertise-rpc-addr redpanda:33145
- --smp 1
- --memory 1G
- --mode dev-container
- --default-log-level=debug
- --set redpanda.enable_transactions=true
- --set redpanda.enable_idempotence=true
- --set redpanda.auto_create_topics_enabled=true
image: docker.redpanda.com/redpandadata/redpanda:v23.1.2
container_name: redpanda
volumes:
- redpanda:/var/lib/redpanda/data
networks:
- tutorial_networkYou must now connect Pathway and the stream producer to redpanda instead of kafka. This could have been avoided by naming the Kafka container differently or by naming the Redpanda container kafka.
As previously mentioned, we need to update the server's address in the settings:
// ./pathway-src/process-stream.py
producer = KafkaProducer(
bootstrap_servers=["redpanda:9092"],
security_protocol="PLAINTEXT",
api_version=(0, 10, 2),
)That’s it! The setting will work exactly the same as with Kafka. However, for consistency, there are also dedicated Redpanda connectors. There’s no difference between Kafka and Redpanda connectors since the same connector is used under the hood.
With the Redpanda connector, here’s what your ./pathway-src/process-stream.py file looks like:
// ./pathway-src/process-stream.py
import pathway as pw
import time
rdkafka_settings = {
"bootstrap.servers": "redpanda:9092",
"security.protocol": "plaintext",
"group.id": "0",
"session.timeout.ms": "6000",
}
t_ratings = pw.redpanda.read(
rdkafka_settings,
topic_names=["ratings"],
format="json",
value_columns=[
"movieId",
"rating",
],
types={"movieId": pw.Type.INT, "rating": pw.Type.FLOAT},
autocommit_duration_ms=100,
)
t_best_ratings = compute_best(t_ratings, 3)
# We output the results in a dedicated CSV file
pw.csv.write(t_best_ratings, "./best_ratings.csv")
# We wait for Kafka and ZooKeeper to be ready
time.sleep(20)
# We launch the computation
pw.run()If you don't care about the names of the connector and server, you don't have to change the file at all.
As with Pathway, you need to update the server name (if required) for the stream generator:
// ./producer-src/create-stream.py
producer = KafkaProducer(
bootstrap_servers=["redpanda:9092"],
security_protocol="PLAINTEXT",
api_version=(0, 10, 2),
)Small problem—if you look at the results now, we have an empty best_ratings.csv.
This comes from creating the ratings topic. While the topic was ready with Kafka, it was created at the reception of the first message with Redpanda. Creating a topic makes Redpanda discard the messages until it’s ready. Sending a message at the beginning of the computation should solve this:
// ./producer-src/create-stream.py
producer.send(topic, "*COMMIT*".encode("utf-8"))
time.sleep(2)Note that this difference comes from Redpanda—not Pathway. Pathway will receive and process the data the same way regardless of whether Kafka or Redpanda is used. Kafka and Redpanda are responsible for handling messages: Redpanda discards the incoming messages while the topic is created.
Despite the fix, the final file is very similar to the one for the Kafka version:
// ./producer-src/create-stream.py
from kafka import KafkaProducer
import csv
import time
import json
topic = "ratings"
#We wait for Kafka and ZooKeeper to be ready
time.sleep(30)
producer = KafkaProducer(
bootstrap_servers=["kafka:9092"],
security_protocol="PLAINTEXT",
api_version=(0, 10, 2),
)
producer.send(topic, "*COMMIT*".encode("utf-8"))
time.sleep(2)
with open("./dataset.csv", newline="") as csvfile:
dataset_reader = csv.reader(csvfile, delimiter=",")
first_line = True
for row in dataset_reader:
# We skip the header
if first_line:
first_line = False
continue
message_json = {
"userId": int(row[0]),
"movieId": int(row[1]),
"rating": float(row[2]),
"timestamp": int(row[3]),
}
producer.send(topic, (json.dumps(message_json)).encode("utf-8"))
time.sleep(0.1)
producer.send(topic, "*COMMIT*".encode("utf-8"))
time.sleep(2)
producer.close()You can take a look at the project sources in our GitHub repository. With this, the results are the same as with Kafka:
movieId,average_rating,views,time,diff
296,5,1,1680008702067,1
306,3.5,1,1680008702167,1
[...]
296,3.3333333333333335,3,1680008703767,-1
1088,3.6666666666666665,3,1680008703767,1
296,3.3333333333333335,3,1680008703767,1
899,3.1666666666666665,3,1680008703767,-1You've successfully computed the K best-rated movies using Redpanda, and your ranking is automatically updated thanks to Pathway. But after taking a closer look, you realize you've been sending your results in a CSV file, which isn't the most suitable for handling a data stream.
Not only that, but the file stays on your local computer, preventing others in the organization from accessing the data in real time.
Your team suggests sending the results back to Redpanda into an “output topic” instead. Redpanda is optimized for handling data streams, making it a more efficient and effective solution than sending data in a CSV file. By doing this, you can ensure the data is accessible to everyone who needs it in real time.
Connecting to Redpanda with Pathway is as easy as connecting to Kafka. You just have to use a Redpanda connector, which is exactly the same as the Kafka connector:
rdkafka_settings = {
"bootstrap.servers": "redpanda:9092",
"security.protocol": "plaintext",
"group.id": "$GROUP_NAME",
"session.timeout.ms": "6000",
}
pw.redpanda.write(
t_best_ratings,
rdkafka_settings,
topic_name="best_ratings",
format="json"
)As previously mentioned, you can also establish a more secure connection using a SASL-SSL authentication over a SCRAM-SHA-256 mechanism (e.g. connecting to Redpanda Cloud) as follows:
rdkafka_settings = {
"bootstrap.servers": "redpanda:9092",
"security.protocol": "sasl_ssl",
"sasl.mechanism": "SCRAM-SHA-256",
"group.id": "$GROUP_NAME",
"session.timeout.ms": "6000",
"sasl.username": "username",
"sasl.password": "********",
}Conclusion: it’s simple to switch from Kafka to Redpanda!Congratulations! You just built a best-rated movie application in Pathway and made it work with Redpanda. Being fully Kafka API-compatible, Redpanda truly acts as a drop-in replacement—there are no new binaries to install, no new services to deploy and maintain, and the default configuration just works.
If the server name remains the same, you have nothing to do with your Pathway code! For consistency, you can use Pathway's Redpanda connectors, which work exactly the same as Kafka connectors. To learn more about Redpanda, browse the Redpanda blog for more tutorials on how to easily integrate with Redpanda, or dive into one of the many free courses at Redpanda University.
To keep exploring, try Redpanda for free! If you get stuck, have a question, or want to chat with the team and fellow Redpanda users, join the Redpanda Community on Slack.
Machine learning and artificial intelligence are powerful, but when you combine them with real-time data, they become extra meaningful if you want to act now. Let's say you have geospatial data and want to map out geofences on the fly in realtime, or get alerts on anomalies without having any parameters pre-defined, or perhaps you want to quickly know what sensors are having issues.
Subscribe to our VIP (very important panda) mailing list to pounce on the latest blogs, surprise announcements, and community events!
Opt out anytime.

