

Data warehouse vs. data lake—Complete guide for data engineers











Data warehouse vs. data lake
Data lakes and data warehouses are two common architectures for storing enterprise data. In a June 2020 Gartner survey, 80% of executives responsible for data or analytics reported they had invested in a data warehouse or were planning to within 12 months, and 73% already used data lakes or intended to within 12 months.
Although data warehouses and lakes have some functional overlap, key distinctions exist between how the two architectures store and access data. Data engineers and developers must understand the differences to make the right choices for their business use cases.
This article briefly defines each term before diving into the key distinctions and understanding the use cases for each type of system.
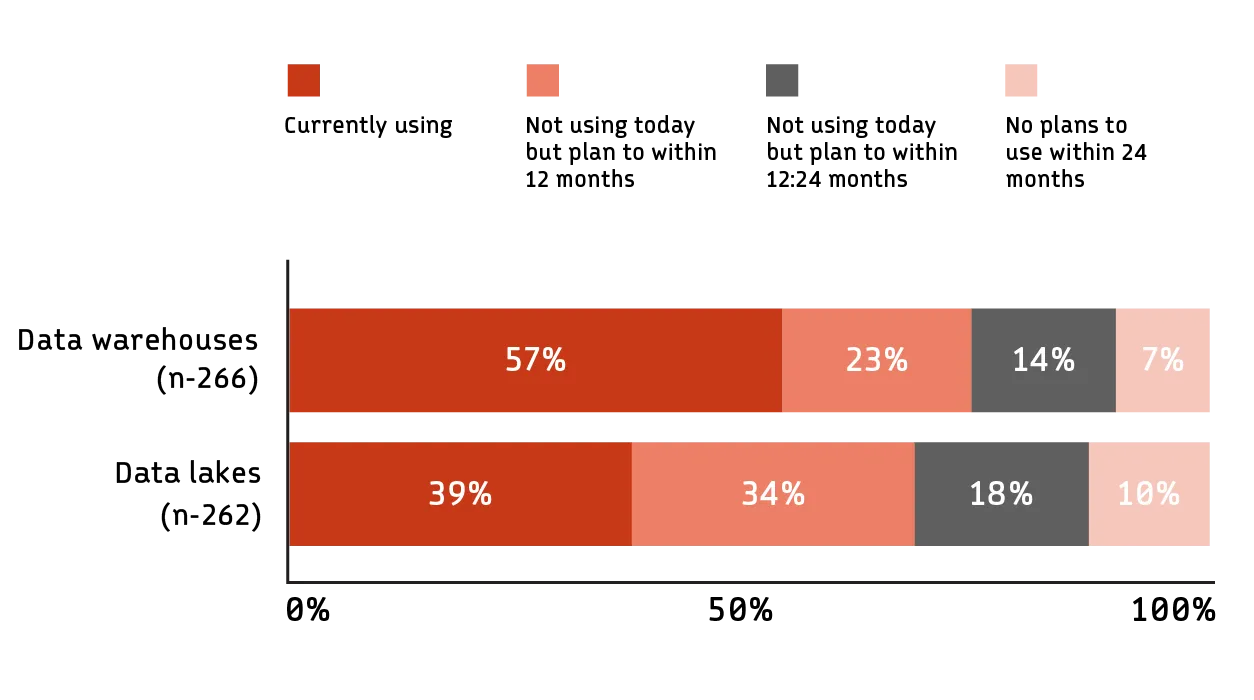
Data warehouse vs. data lake: a summary
The difference between the technologies can be described by data architecture, data management, data usage patterns, the data itself, and the advantages or disadvantages of each architecture. The following table contains a summary of the key distinctions in each area.
What is a data warehouse?
Data warehousing evolved from information and decision support systems (DSS) in the 1960s. Turning enterprise business data, or operational data, into actionable information, or derived data, usable for decision-making was the driving need behind data warehousing.
According to Bill Inmon in Building the Data Warehouse (2001), a data warehouse is “a collection of integrated, subject-oriented databases designed to support the DSS function, where each unit of data is relevant to some moment in time.” Data in a data warehouse is pulled from various sources throughout an organization.
One of the critical aspects of data warehouses is that they contain data that’s been transformed through an Extract, Transform, Load (ETL) process to transform raw data into processed, lightly summarized data that is ready for consumption by business users.
Amazon Redshift, Google BigQuery, Oracle, and IBM Netezza are a few popular enterprise data warehouse products. You can implement data warehouses in the cloud or on-premise.
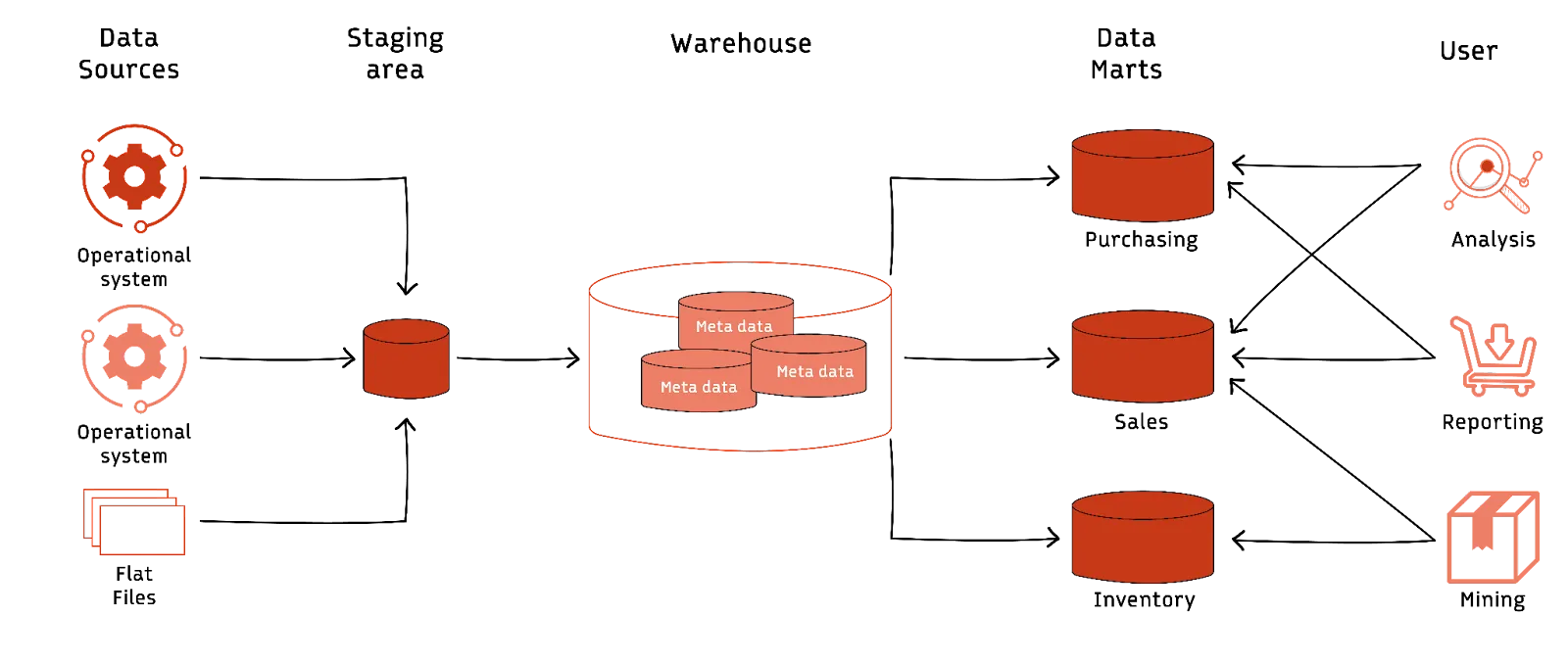
For example, a large retail company may have databases for customers, sales transactions, finance, human resources, and so on. These databases contain historical information but mainly serve the company's operational needs. The company consolidates all the data in a warehouse to preserve historical snapshots of operational details. Retail analysts can then use the data to answer questions related to multiple departments over time, such as:
- Average monthly sales within a department for the past 12 months.
- Top-selling products during a marketing campaign.
- Popular items that repeat customers buy.
Business Intelligence Analysts perform trend analyses and make predictions. They create dashboards or reports for business leaders that give more information about KPIs and metrics.
[CTA_MODULE]
What is a data lake?
Data lake architecture was developed in response to the exponential increase in data collected by businesses and the need to process data quickly in its raw form. Around 2010, the growing popularity of distributed computing environments, such as Hadoop, led to a shift in enterprise data storage.
Companies now had access to large data storage capabilities both on-premise and in the cloud. Distributed file systems and databases also enabled business users and data scientists to access raw, unprocessed data quickly.
Unlike data warehouses, data lakes serve as a data repository for raw and processed data. One of the critical aspects of data lakes is that they often follow an Extract Load Transform (ELT) process, where data is stored first and processed later.
Data in a data lake can be structured, semi-structured, or unstructured but is often raw data ingested directly from or very close to a generating source. Telecommunications data, streaming media, financial data, and Internet of Things (IoT) data are common types ingested directly into a data lake in real-time.
You can build data lakes in the cloud or on-premise. Some common cloud-based data lake architectures use AWS S3 blob storage and AWS Lake Formation, Google Cloud Storage, and Azure Data Lake Storage. Parquet files stored in a Hadoop File System is a popular on-premise solution.

For example, a manufacturing company collects real-time IoT data from machinery on a production line. The data is processed quickly during ingestion and fed nearly instantly to a real-time dashboard using a tool such as Grafana. In this situation, the ETL process that feeds data into a data warehouse would be too slow for the day-to-day needs of manufacturing. In contrast, a data lake can make mission-critical data available very quickly.
Data warehouse vs. data lake: architectural differences
While data warehouses store structured data, a data lake is a centralized repository that allows you to store any data at any scale.
Schema
The schema in a database describes the structure of the data. In a data warehouse, the schema is formalized, similar to a RDBMS. Data warehouses often utilize a star schema to organize fact and dimension tables that contain aggregations and metrics for many business units. They follow a schema-on-write design pattern.
In contrast, a data lake offers more flexibility. Data can be stored with a strict schema, or it can be raw or unstructured data. Various tables and datasets exist within a data lake, and ad-hoc data pipelines can be easily added. Data lakes follow a schema-on-read design pattern. A common critique of data lakes is that they can become data swamps—an unorganized accumulation of data sources.
Design process
The design process refers to the steps needed to build the architecture.
The design of a data warehouse can be a significant undertaking. It involves identifying operational data sources and meeting with several levels of stakeholders to identify KPIs and metrics that drive the business. These will be the foundation of the fact and dimension tables stored in the star schema. Business intelligence users are involved to ensure the information needed to build reports and conduct analytics is contained in the warehouse. This discovery and planning work is done in tandem with the infrastructure and technical work of establishing data pipelines.
On the other hand, data lakes require the technical work of establishing an infrastructure and data pipelines. However, data can be added in an ad hoc manner and does not necessarily require the same level of in-depth planning. Pipelines and schemas can be evaluated case-by-case and easily adjusted over time.
Data
Data format refers to the structure and type of the data. It can be structured, unstructured, or semi-structured. We often consider structured data as a tabular format and unstructured data as text, video, or image files. JSON data would be an example of semi-structured data. Data timeliness is the lag between when the data is generated and when it is available.
In a data warehouse, the data is structured. As we discussed, the data warehouse utilizes a schema on write and stores data in a traditional RDBMS, so the data must be structured. The ETL process for a data warehouse is done in batches, so the data's timeliness depends on the ETL process's schedule. Still, generally, data warehouses do not contain real-time data.
Conversely, data lakes can handle data in virtually any format, e.g., JSON, CSVs, image files, video files, or PDF files. Data lakes can also manage real-time data pipelines, a huge advantage for organizations that collect time-series data.
[CTA_MODULE]
Data warehouse vs. data lake: management differences
Data warehousing requires more management effort before storing data, while data lakes require more management effort after storage, but before using the data.
Data processing
Data processing usually follows one of two paradigms:
- Extract Transform Load (ETL) where the data is processed before storing it
- Extract Load Transform (ELT) where the data is stored in it’s raw format and processed later
Data warehouses commonly employ the ETL paradigm because they aim to curate data in facts and dimensions that are ready for consumption via reports and business analytics.
Data lakes typically store raw, unprocessed data following an ELT paradigm. Data in a data lake might be minimally processed during the data ingestion process, stored as a processed and cleaned dataset, or all of the above.
Lineage
Data lineage refers to tracking the provenance of data as it moves away from the generating source. It is crucial to data quality and reliability.
Data warehouses load data through batch processing. The pipelines and scripts used to transform data into fact and dimension tables help preserve the provenance of the data.
Data lakes can store data in various raw and processed states, and new data sets can be added quite easily. Data lakes require metadata management to keep your lake from turning into a swamp.
Updates
As a business evolves and use cases change, the data and metrics of an organization will change. There will eventually be a need to update the data storage system.
Data warehouses are harder to update for the same reason that they take longer to design and implement. It requires stakeholder involvement and the development or modification of batch processes, including testing.
Data lakes are easier to update since ad hoc data pipelines can be added easily. Also, in a data lake, data sets may not be interconnected as they are in data warehouses, so in some cases, there is less concern about affecting downstream processes during an update.
Data warehouse vs. data lake: usage differences
The usage patterns refer to which users are accessing the system, how often, and what type of workloads they perform.
In a data warehouse, the usage patterns tend to be predictable since the data often feeds established reports and dashboards. There are a wide variety of users of data warehouses, such as stakeholders accessing dashboards, business analysts developing reports, and data scientists utilizing processed data for analysis. The data is preprocessed and summarized, reducing the computational complexity of the queries.
An example of an SQL query in a data warehouse would look something like this:
//pull a list of the top 10 orders by order total
SELECT order_id, order_total
FROM orders
ORDER BY order_total DESC
LIMIT 10;In a data lake, the usage patterns can fluctuate as the raw data is used for developing machine learning models or new data products. Users are often data scientists and analysts. In a data lake, a query is likely to be performed with a distributed tool such as Spark SQL and might look something like this:
//rank orders by order total within each department
import org.apache.spark.sql.functions._
val df = simpleData.toDF("oder_id", "department", "order_total")
val windowSpec = Window.partitionBy("department").orderBy("order_total")
//rank
df.withColumn("rank",rank().over(windowSpec))
.show()Benefits
Data warehouses serve the important purpose of containing summarized and centralized data that helps businesses make data-driven decisions by monitoring KPIs and metrics. They are typically easy to access and use by end-users.
The benefits of data lakes are their flexibility to store virtually any type of data and to scale to handle high volume, velocity, and veracity data. You can sample raw data and organize it as needed for building new data products or machine learning models.
Combining data lakes and warehouses
The data lakehouse is an emerging concept in enterprise big data storage architectures. It is an evolution of the data warehouse and data lake architectures and is meant to combine the best aspects of each while solving some of the deficiencies mentioned above.
Around 2017, the term “data lakehouse” emerged as many organizations within the data industry were implementing new technology, such as high-performance distributed SQL engines, within their data warehouse and data lake architectures. Some major challenges of the two-tiered data warehouse/data lake paradigm and outlined the lakehouse concept as a unifying approach to overcoming those challenges.
According to Michael Ambrust, creator of Spark SQL and Distinguished Engineer at Databricks, “Lakehouse is a data management system based on low cost and directly accessible storage that also provides traditional analytical DBMS management and performance features such as ACID transactions, data versioning, auditing, indexing, caching, and query optimization. Lakehouses thus combine the key benefits of data lakes and data warehouses: low-cost storage in an open format accessible by various systems from the former and powerful management and optimization features from the latter.”

Here is a brief table to summarize the challenges, including reliability, data staleness, total cost of ownership, and limited use-case support, that are solved by the data lakehouse architecture:
Recommendations
Most large companies are gaining maturity in their data management approaches. Recall the Gartner survey from June 2020, where 70-80% of leaders from over 250 organizations used or had plans for a data warehouse or data lake. Data engineers today will likely be learning an organization's legacy systems and helping move the organization forward rather than building from scratch. The needs of an organization dictate the priorities of data engineers.
A data lakehouse is the most performant and cost-effective solution. However, engineers must still understand data warehousing concepts to design schemas and build ETL logic that meets the organization's needs.
If the organization requires a centralized data store, systematic KPI generation, and analytics-ready data accessible by business users, then focusing on the data warehousing functions within a lakehouse will be a top priority.
In contrast, if the organization has to store a large amount of data in various formats for machine learning and data science purposes, then optimizing raw data storage in a data lake becomes the highest priority.
[CTA_MODULE]
Conclusion
Data warehouses and data lakes are quite different when we examine how each is implemented. Data warehouses are highly structured and most useful for providing business users with a central view of metrics and KPI data.
Data lakes were born out of the emergence of big data and distributed computing technology. They provide a quick and easy way to store and access datasets, especially for developing machine learning models. As technology has matured, a new data architecture paradigm is emerging to combine and optimize both concepts into the data lakehouse.
[CTA_MODULE]