

ETL pipeline—Components, tips, and best practices











ETL pipeline
An ETL (Extract, Transform, and Load) pipeline is a set of processes used to extract data from various sources, transform it into a consistent format, and load it into a target system. Of late, one of the most significant trends has been the shift toward a real-time ETL pipeline that processes data as it arrives.
Real-time ETL or streaming ETLs are the future as they enable near-real-time data processing, helping organizations respond more quickly to changing conditions and opportunities. They also provide greater flexibility, allowing organizations to add new data sources or target systems without disrupting existing pipelines.
In this article, we will talk about the evolution of the ETL pipeline, streaming ETL, and its advantages over its traditional batch counterpart. Lastly, we’ll also talk about how to build a near real-time streaming ETL pipeline with Apache Kafka® and tips to avoid common mistakes.
Summary of key streaming ETL pipeline features
The table below highlights a few key features and advantages contributing to the popularity of the streaming ETL pipeline.
Evolution of the ETL pipeline
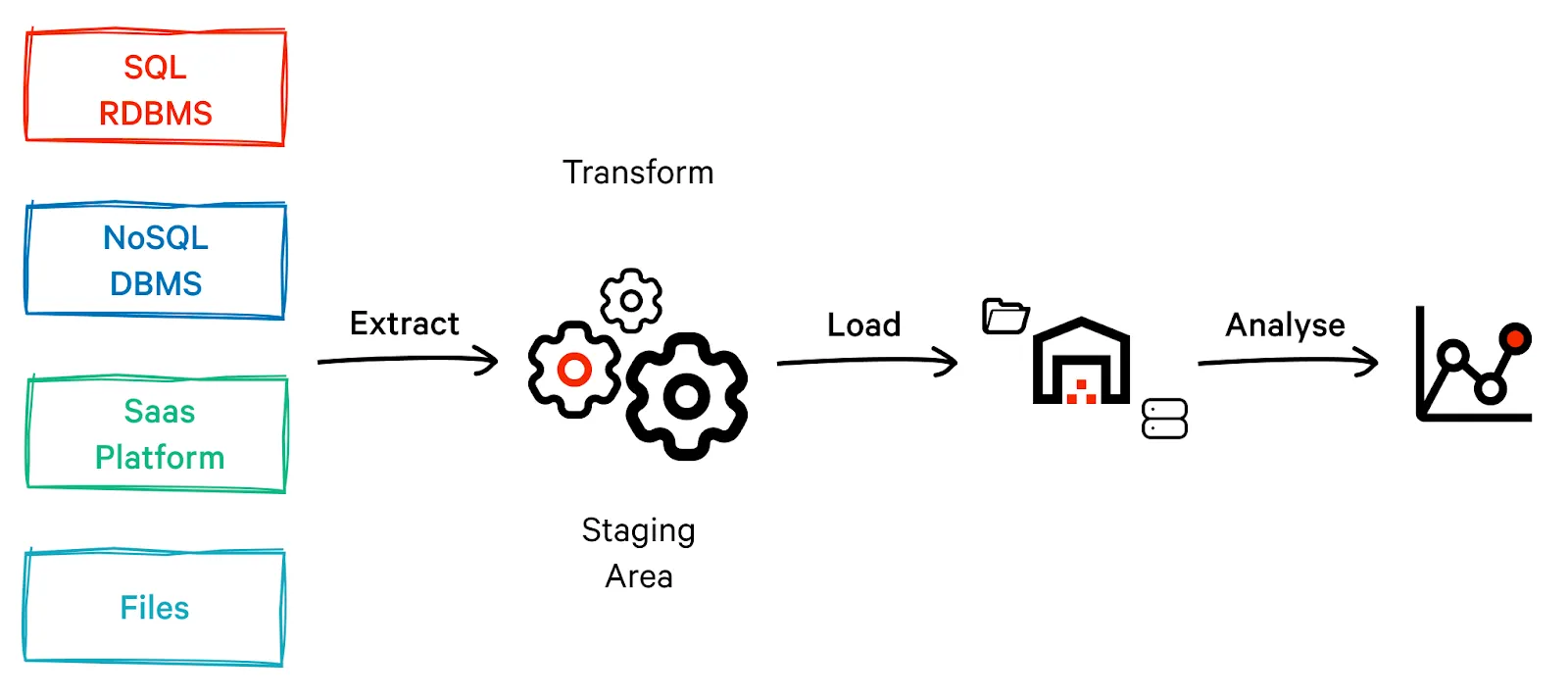
ETL has been synonymous with data engineering and fundamentals for several decades. As a concept, it has been present since the late 70s and early 80s and has been widely used in the data ecosystem. It is typically a three-step process:
- Extract: Raw data (in various formats like CSV, JSON, TXT, etc.) is collected from different sources such as a database, files, APIs, and message queues.
- Transform: The data is cleaned, enriched, and formatted to match the target schema. This step may also involve performing calculations, aggregations, or filtering to create new derived data sets that are more useful for analysis.
- Load: The transformed data is loaded into a target system, such as a data warehouse or a data lake, where it can be analyzed, queried, and visualized. The ETL pipeline also includes data validation and error handling to ensure the data is accurate, consistent, and complete.
Traditionally, these steps were done by periodically executed "batch ETL" processes on on-premise infrastructure.. With the rise in cloud technology and ever-increasing data volume, cloud-based ETL platforms started to gain attention. Over the years, there have been several other emerging trends in ETL pipeline technology, such as:
- Adoption of machine learning and AI to automate data transformation processes
- Integration of data quality and governance processes to ensure data accuracy and compliance.
However, the core principles of the 3-step process running in a “batch” or “scheduled” manner remained the same.
[CTA_MODULE]
Batch ETL
Batch ETL is typically used when moving data from siloed subsystems (data sources owned by different teams/departments) to a central data warehouse. A few hours or even a few days' delay is usually acceptable in these cases.
Batch ETL involves batching of data –, you either wait for large volumes of data to accumulate or run it based on business rules (like the end of a day/month/workflow) before executing the ETL pipeline. Batch ETL pipelines enable organizations to collect and analyze large volumes of data from disparate sources, providing valuable insights for decision-making and strategic planning.
Streaming ETL
However, analytics requirements have now gone beyond Batch ETL, demanding business insights to be timely and accessible. While Batch ETL still has some use cases, it is less flexible and cannot process real-time data. Streaming ETL, or real-time ETL, is an advanced ETL pipeline that continuously processes data as it arrives rather than processing data in batches.
Streaming ETL pipelines are gaining popularity because they enable organizations to process and analyze data as soon as it is generated, allowing for faster decision-making and more agile business processes. For example, you can use streaming ETL pipelines for use cases like real-time fraud detection, IoT data processing, social media sentiment analysis, clickstream analysis, and gaming analytics.
Streaming ETL pipeline: Key components
Streaming ETL involves a few key components:
Data source
Streaming data can come from various sources, such as sensors, web logs, social media, or IoT devices. The data is typically a continuous stream of events.
Stream processing engine
A stream processing engine is a software platform that continuously processes and analyzes data streams in real time. Popular stream processing engines include Apache Kafka Streams, Apache Flink, and Apache Spark Streaming.
Transformation logic
Transformation logic is used to transform and enrich the data as it flows through the pipeline. For example, you might filter, aggregate, or join data from multiple streams.
Sink
The final destination for the processed data. The sink can be a database, data warehouse, or another data store.
Building a streaming ETL pipeline with Kafka
Apache Kafka is a distributed streaming platform to build near real-time data pipelines and streaming ETL applications. With its high throughput, low latency, and scalable architecture, Kafka is well-suited for processing and transforming large volumes of data in near real time.
We’ll now look at the important steps in building a near real-time streaming ETL pipeline with Kafka. First, we install Kafka and Apache ZooKeeper™, then use Kafka Connect source connectors to stream data to Kafka and KSQL to make any transformations in near real-time. Finally, we use a Kafka Connect Sink Connector to load the result data into a target system.
Setting up Kafka and ZooKeeper
To start, you must install and configure Apache Kafka. You can download Kafka from the Apache Kafka website and follow the instructions for installation and configuration. There are some managed Kafka services available as well that offer all the features and handle the infrastructure for you. You also need to set up a ZooKeeper cluster, which is required for Kafka. ZooKeeper manages the metadata of the Kafka cluster, such as the configuration settings, broker information, and topic partitions.
# Install Java
sudo apt-get update
sudo apt-get install default-jre -y
# Download and extract Kafka
wget https://downloads.apache.org/kafka/3.0.0/kafka_2.13-3.4.0.tgz
tar -xzf kafka_2.13-3.4.0.tgz
# Start Zookeeper
bin/zookeeper-server-start.sh config/zookeeper.properties
# Start Kafka
bin/kafka-server-start.sh config/server.propertiesConfiguring data source/producer
The next step would be to push data into Kafka.
Using Kafka Producer
A Kafka producer is a client application that sends data to a Kafka topic. To stream data into Kafka, you first need to create a Kafka producer and for that, you need to set up the Kafka client libraries and configure them to connect to your Kafka cluster. Here's an example of how to configure a Kafka producer in Java.
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
public class KafkaProducerExample {
public static void main(String[] args) {
// Set the producer properties
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
// Create a Kafka producer instance
Producer<String, String> producer = new KafkaProducer<>(properties);
// Send a message to the "my_topic" topic
producer.send(new ProducerRecord<>("my_topic", "key", "value"));
// Close the producer
producer.close();
}
}
We set the BOOTSTRAP_SERVERS_CONFIG property to the address of the Kafka broker, and we set the KEY_SERIALIZER_CLASS_CONFIG and VALUE_SERIALIZER_CLASS_CONFIG properties to StringSerializer because we are sending simple string messages. We then create a KafkaProducer instance using these properties and use the send method to send a message to the my_topic topic. Finally, we close the producer using the close method.
Using Kafka Connect
Kafka Connect is an open-source framework for connecting Kafka with external systems such as databases, key-value stores, search indexes, and file systems. It uses ready-to-use components called connectors to help us import data from external systems into Kafka topics and export data from Kafka topics into external systems.
Here's an example of how to use Kafka Connect to send data from a MySQL database to a Kafka topic:
1. Start the Kafka server by running the following command from the Kafka directory:
bin/kafka-server-start.sh config/server.properties2. Configure Kafka Connect by creating a connect-distributed.properties file in the config directory. Here is an example configuration file:
bootstrap.servers=localhost:9092
group.id=connect-cluster
key.converter=org.apache.kafka.connect.json.JsonConverter
key.converter.schemas.enable=false
value.converter=org.apache.kafka.connect.json.JsonConverter
value.converter.schemas.enable=false
offset.storage.topic=connect-offsets
offset.storage.replication.factor=1
config.storage.topic=connect-configs
config.storage.replication.factor=1
status.storage.topic=connect-status
status.storage.replication.factor=1
plugin.path=/path/to/your/plugin/directory3. Start the Kafka Connect service by running the following command from the Kafka directory:
bin/connect-distributed.sh config/connect-distributed.properties4. Configure the MySQL connector by creating a mysql-connector.json file:
{
"name": "mysql-connector",
"config": {
"connector.class": "io.debezium.connector.mysql.MySqlConnector",
"tasks.max": "1",
"database.hostname": "localhost",
"database.port": "3306",
"database.user": "root",
"database.password": "root",
"database.server.id": "1",
"database.server.name": "my_database",
"database.whitelist": "my_database.my_table",
"table.whitelist": "my_database.my_table",
"database.history.kafka.bootstrap.servers": "localhost:9092",
"database.history.kafka.topic": "schema-changes.my_database"
}
}5. Start the MySQL connector using the Kafka Connect REST API:
curl -X POST -H "Content-Type: application/json" --data @mysql-connector.json http://localhost:8083/connectorsThis creates a Kafka topic with the same name as your MySQL table (my_database.my_table) and starts streaming data from the MySQL database to the Kafka topic.
Configuring transformations
Once the data is in Kafka, the next step is to process the input events and apply transformations to convert them into the desired format. A Kafka Streams application is a client application that processes data from Kafka topics in near real-time. You can write a Kafka Streams application using Kafka Streams DSL or KSQL.
Let us look at a quick example of how to use KSQL for transformations. Suppose you have a stream of customer orders data in a Kafka topic named customer_orders with the following schema:
CustomerOrders:
OrderId INT,
CustomerId INT,
OrderDate VARCHAR,
OrderAmount DOUBLEYou want to create a new stream that contains the total order amount for each customer, and where the OrderAmount is converted to the currency of your choice.
The KSQL query to achieve this can be:
CREATE STREAM customer_orders_summary AS
SELECT CustomerId,
SUM(OrderAmount) AS TotalOrderAmount,
CONCAT('$', ROUND(SUM(OrderAmount) * 0.85, 2)) AS TotalOrderAmountUSD
FROM customer_orders
GROUP BY CustomerId;This query creates a new stream named customer_orders_summary that selects the CustomerId and the total OrderAmount for each customer. The GROUP BY clause groups the orders by CustomerId, so we get each customer's total order amount.
Deployment and monitoring
You can deploy a Kafka streams application on a standalone machine, in a container, or on a cluster. You can monitor the pipeline using various tools such as Kafka Manager, Kafka Monitor, KafDrop, etc. These tools allow you to monitor the pipeline's health, throughput, and latency. Kafka also provides horizontal scalability by allowing you to add more brokers to the Kafka cluster to handle more data.
[CTA_MODULE]
Streaming ETL pipeline tips and best practices
Building and running streaming ETLs in production requires expertise and can sometimes get tricky. Here are some tips for setting up a streaming ETL pipeline.
Monitor system health
It is crucial to monitor the health of the streaming ETL system and ensure that it runs smoothly. This includes monitoring resource usage, such as CPU, memory, and disk space, as well as network traffic and latency. Set up alerts to notify you if these metrics exceed a certain threshold.
Implement error handling
Streaming ETL systems are complex and can fail unexpectedly. Handling errors by logging error messages and taking appropriate corrective action is important. Ensure you have a robust error-handling mechanism that can recover from failures.
Another critical component is dead-letter topic (DLT) events. If a message fails while processing, it can be put into the DLT and recovered later, without losing the original message. This adds to the robustness of the system.
Tune Kafka performance
Streaming ETL systems can be resource-intensive, and performance tuning is critical to ensure that the system handles the load. This includes optimizing data serialization, compression, partitioning, and tuning batch and buffer sizes to balance throughput and latency.
Implement data security
Streaming ETL systems can handle sensitive data, and it is essential to secure your data at rest and in transit. This includes encrypting data, using secure connections, and implementing access controls to ensure only authorized users can access the data.
Plan for scalability
A streaming ETL pipeline can grow rapidly, and it is important to plan for scalability from the outset. This includes designing for horizontal scaling, implementing load balancing, and using distributed computing frameworks that scale out as the workload increases.
[CTA_MODULE]
Conclusion
The streaming ETL pipeline has revolutionized how data is processed and analyzed in real time. Its ability to handle large volumes of data while providing near-instantaneous insights has made it a crucial technology in today's data-driven world.
With the help of advanced tools and platforms, organizations can quickly and efficiently process, transform, and load data from various sources into their data warehouses or lakes in real time. As more and more businesses rely on real-time data for decision-making, the demand for streaming ETL solutions continues to grow.