

Streaming data pipeline: Practical approaches and examples











Streaming data pipeline
According to International Data Corporation, the world's data volume is set to grow by 61% to 175 zettabytes by 2025. The majority of this data is real-time data that originates from sources like log files generated by applications, social media news feeds, and sensor data from the millions of smart devices that make up the new Internet of Things. It needs to be analyzed and consumed as it is generated and its usefulness decreases rapidly with time.
Traditional batch processing systems were designed for post-dated, high-volume analysis. They take a longer time to deliver insights and fall short for real-time data scenarios where data freshness is paramount. Real-time data requires high volume, high-velocity, continuous processing that does not compromise data integrity. This is where streaming data pipelines come into the picture.
A streaming data pipeline allows data to flow through a source to a target- in near real-time just like a stream. This data flow goes through the process of “extraction, transformation, and loading” for enhanced accuracy and analysis. Building high-throughput streaming data pipelines requires proper planning and execution. An effective pipeline must have a scalable design, robust error handling, and maintain integrity.
This article explores streaming data pipeline fundamentals, architectural approaches, and key considerations around making them more scalable, reliable, and secure.
Summary of key streaming data pipeline concepts
Streaming data pipeline fundamentals
Streaming data pipelines are a more “advanced” form of data pipelines designed for managing and processing large volumes of high-speed data. Data goes through the Extract, Transform, Load (ETL) process as it enters the pipeline—reducing overall latency to insights.
The modern streaming data architecture can be thought of as a stack of five logical layers. Each layer consists of specialized components designed to meet specific needs.
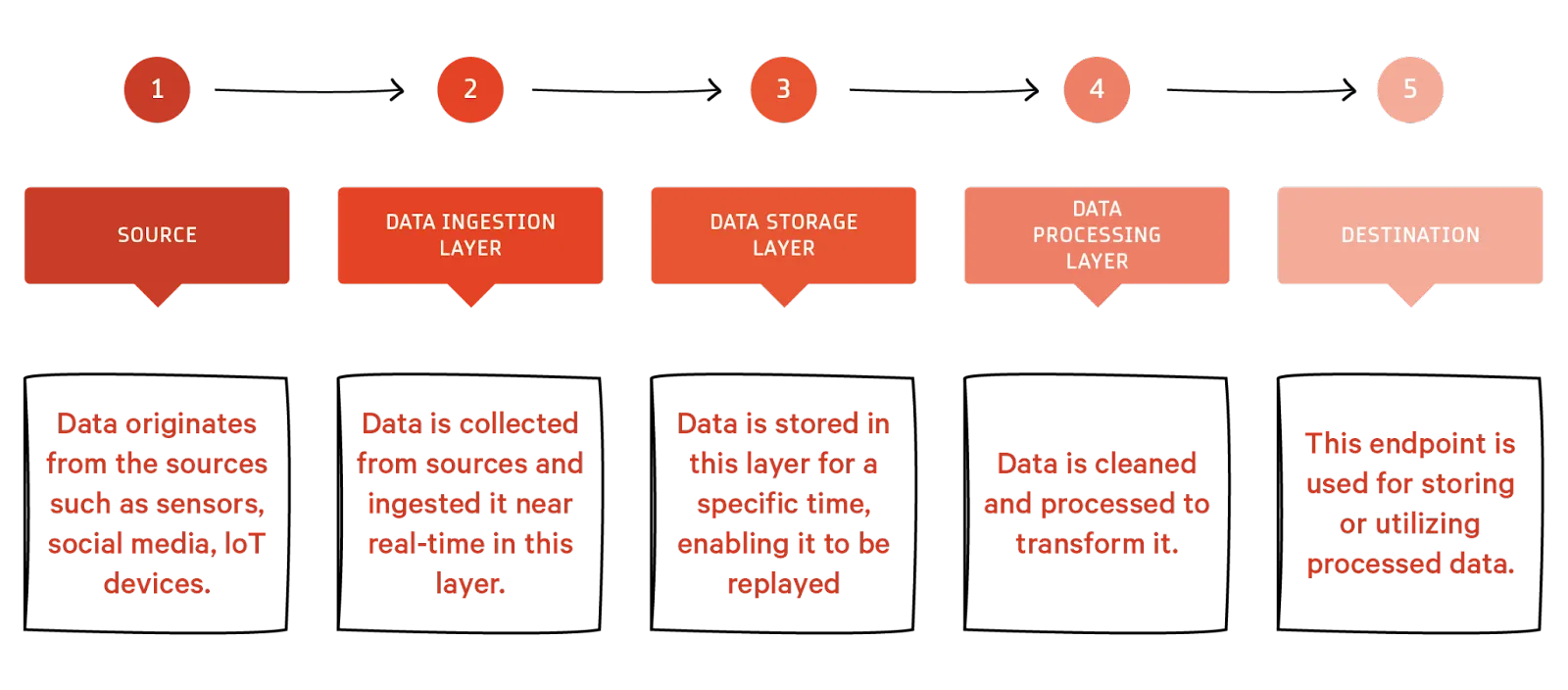
The infographic gives an overview of the five layers. The tools and offerings that facilitate the implementation of these layers are below.
- Source: Streaming data sources encompass a wide range of inputs, including application logs, clickstream data, mobile apps, sensors, feeds, transactional databases, IoT sensors, and social media platforms.
- Data ingestion layer: For ingesting data into streaming pipelines, you can use AWS services like AWS IoT, Kinesis Data Streams, or Apache Kafka® and Redpanda.
- Data storage layer: Stores streaming data temporarily between ingestion and processing—can be a cloud-based data storage or database.
- Data processing layer: Stream processing can be achieved through services like AWS Lambda, Apache Flink®, and Spark Streaming.
- Serving/ Destination: Processed data can be directed to various destinations, including databases, data warehouses (e.g., Google BigQuery), purpose-built systems (like OpenSearch services), data lakes (e.g., HDFS), and event-driven applications (e.g., Kafka), and third-party integrations (like Elasticsearch, Splunk, Tableau, or Datadog).
Complementing these essential layers and components are the key characteristics of streaming data pipelines, characterized by high throughput and modularity. High throughput means the pipeline handles massive amounts of data coming in quickly. Modularity means they are made of separate, interchangeable components. Modularity makes adding new data sources easier and allows for flexibility and scalability.
A streaming data pipeline finds practical significance in real-world applications, as exemplified by its crucial role in the financial markets where fortunes are made and lost in the blink of an eye. Stock exchanges and online trading platforms rely on these pipelines to render real-time stock prices and market data owing to their higher throughput. This way, the traders can make informed decisions almost instantaneously.
Now, we will discuss each stage of streaming pipeline architecture separately and how it works.
Streaming data pipeline architecture

Data production
In the world of streaming data pipelines, data production is like the starting point. It's all about gathering information from various sources, such as devices, apps, and sensors. The goal is to grab this data quickly and send it along for further processing. Data production sets the pace for the whole process, making sure your data flows smoothly from source to destination.
Data ingestion
The next step in crafting a streaming data pipeline is the data ingestion layer. In this phase, the Change Data Capture (CDC) tool plays a crucial role. It captures real-time changes from source databases and transmits them to a stream processing tool. This stream processing tool (Kafka, Redpanda) is responsible for ingesting the data into the target data storage system, ensuring real-time updates and synchronization.
We will now discuss three commonly used data ingestion strategies.
[CTA_MODULE]
Pull architecture
Pull-based ingestion, as the name suggests, allows the data pipelines to actively look for data sources and extract data as needed. You should use this kind of data ingestion when dealing with multiple data sources, as it gives more control over the data ingestion process. To implement a pull-based data pipeline:
- Connect to the data sources so that the streaming pipeline pulls data.
- Schedule the frequency of data extraction at which the pipeline queries data sources and extracts new data.
Push architecture
In this type of data ingestion, the data source itself pushes the data into the streaming data pipeline. To implement a push-based data pipeline, you configure the data source to connect with your pipeline and then ‘push” the data into the pipeline.
The code snippet below demonstrates push-based data ingestion.
from kafka import KafkaProducer
# Kafka producer configuration
producer = KafkaProducer(
bootstrap_servers='110.93.246.74:9092',
value_serializer=lambda v: str(v).encode('utf-8') # Serializer for message value
)
# Function to push user activity event to Kafka
def push_user_activity(user_id, activity_type):
event = {
"user_id": user_id,
"activity_type": activity_type,
"timestamp": int(time.time())
}
# Push the event to the Kafka topic
producer.send('user_activity_events', value=event)
print(f"Pushed event to Kafka: {event}")
# Push a user activity event
push_user_activity(user_id='user123', activity_type='song_played')
In this code, a user activity event, containing user-related data, is pushed into a Kafka topic called 'user_activity_events' for further processing and distribution within a streaming data pipeline.
Hybrid approach
Another kind of data ingestion is called pull-push-based ingestion or hybrid architecture which offers flexibility to manage multiple data sources and different sorts of data within the same pipeline.
Let’s introduce hybrid-based data ingestion in the Python script from push architecture.
from flask import Flask, request
from kafka import KafkaProducer
import time
import threading
app = Flask(__name)
# Configure the Kafka producer
producer = KafkaProducer(bootstrap_servers='110.93.246.74:9092')
# Endpoint for receiving user activity data via POST request
@app.route('/user_activity', methods=['POST'])
def user_activity():
activity = request.json
producer.send('user_activities', activity) # Push user activity data to Kafka
return {"status": "Activity received"}
# Function to periodically pull song play data from the Last.fm API
def pull_song_plays():
while True:
# Simulate pulling song play data from an external source
song_play = {
"user_id": "musicenthusiast",
"song_name": "Example Song",
"timestamp": int(time.time())
}
producer.send('song_plays', song_play) # Push song play data to Kafka
time.sleep(60) # Wait for 60 seconds before pulling data again
# Start a separate thread to execute the pull_song_plays function
pull_thread = threading.Thread(target=pull_song_plays)
pull_thread.start()
# Start the Flask application on port 5000
if __name__ == '__main__':
app.run(port=5000)In the context of a hybrid data ingestion approach, this code example demonstrates a combination of two methods for gathering data:
- Push method: The code sets up a Flask web application with an endpoint '/user_activity' to receive user activity data actively pushed into the system via POST requests. Data is sent to the system as soon as it's generated, similar to how user interactions in applications are instantly recorded.
- Pull method: The script periodically fetches songplay data from an external source, simulating passive data collection. In this case, data is pulled at intervals from an external API (Last.fm) rather than being actively pushed, resembling the way some systems gather data periodically or on-demand.
Once the data is successfully ingested, the next crucial step is to efficiently process it.
Data processing
Data processing includes data cleaning, filtering, transforming, and aggregating. Processing is carried out through the whole of the data flow- from the first step i.e. data ingestion to the last step of delivering it.
For our streaming platform, every user needs to get their password masked to ensure user privacy. So let’s jump right into the code!
from kafka import KafkaConsumer, KafkaProducer
# Instantiate Kafka producer
producer = KafkaProducer(bootstrap_servers='110.93.246.74:9092')
# Send sensitive data with passwords
for i in range(10):
sensitive_data = f'User: john, Password: secret{i}'
producer.send('sensitive_data', sensitive_data.encode())
# Ensure all messages are sent
producer.flush()
# Instantiate Kafka consumer
consumer = KafkaConsumer('sensitive_data', bootstrap_servers='110.93.246.74:9092', group_id='my-consumer-group')
# Redact or mask passwords in received messages
for msg in consumer:
message = msg.value.decode()
redacted_message = message.replace('Password: ', 'Password: ****')
print(redacted_message)We're sending messages with sensitive data, like usernames and passwords, through Kafka. When those messages come in, our code quickly replaces the real passwords with asterisks (****). This streamlined process encapsulates the essence of data processing in a nutshell.
Serving
Serving is the last stage of the streaming data pipeline. It refers to the output of the processing stage where the processed data is written into a read-optimized data store for consumption.
In our data processing stage, we demonstrated real-time data security by redacting sensitive information, specifically passwords, to shield them from unauthorized access. Now, let's take the next step and serve this data to a data store.
import requests
from kafka import KafkaConsumer, KafkaProducer
# Define the Kafka server and topics
bootstrap_servers = '110.93.246.74:9092'
processing_topic_name = 'sensitive_data'
read_optimized_store = 'https://<historianservername>/historian-rest-api/v1/datastores?dataStoreMask='
# Instantiate Kafka consumer for processed data
consumer = KafkaConsumer(processing_topic_name, bootstrap_servers=bootstrap_servers, group_id='my-consumer-group')
# Serve the processed data to the read-optimized data store
for msg in consumer:
processed_data = msg.value.decode()
# Send the processed data to the read-optimized data store
response = requests.post(read_optimized_store, data=processed_data)
print(f"Processed data served to the read-optimized data store: {response.status_code}")
# Close Kafka connection
consumer.close()Once your data reaches the data store, it can be used for analytics, reporting, machine learning, real-time applications, and data integration, depending on the specific needs of the organization or project.
[CTA_MODULE]
Important considerations in streaming data pipeline design
Now that you have a firm grasp of streaming data pipeline architecture, you can look at ways to optimize it for efficiency and performance at scale.
Throughput and latency optimization
The most important considerations for streaming data pipelines are throughput (data processing volume) and latency (data processing speed). To improve these aspects, we leverage parallelism and optimization techniques together.
Parallelism enhances throughput by allowing simultaneous task execution. It includes data parallelism and task parallelism. Data parallelism divides data into smaller parts and processes each part independently, distributing the workload across multiple computing units or nodes. This approach, as seen in Apache Kafka®, significantly boosts processing capacity. In task parallelism, different processing stages, such as data ingestion and transformation operate concurrently, maximizing resource utilization and minimizing bottlenecks.
Optimization reduces latency for real-time responsiveness. We have techniques like data partitioning where data streams are broken down into smaller segments based on criteria like event type or source. It streamlines processes and allows time reduction for analysis. Another technique is resource allocation optimization which efficiently allocates resources such as CPU, memory, and storage based on application requirements ensuring the system can handle workloads without latency spikes.
This balanced approach to parallelism and optimization is essential for achieving high throughput and low latency, making streaming data pipelines responsive and efficient for real-time applications.
Scalability
A data pipeline should have the ability to scale with increasing data volumes. It should also be flexible to accommodate changes in the data sources and processing needs. Streaming data pipelines allow two kinds of scaling:
Horizontal scaling which is also referred to as “scaling out” can be achieved by adding more distributed nodes for data processing. Streaming processing frameworks, such as Kafka or Flink, employ various partitioning strategies to distribute data across nodes and optimize processing.
Vertical scaling also referred to as scaling up involves enhancing the capacity of a single node by enhancing computational resources such as CPU, storage, or RAM. You can use both of these techniques in tandem to optimize throughput depending on the pipeline.
Storage at scale
Different streaming technologies provide temporary and permanent data storage options to meet your requirements. For example, Kafka can be used to ingest real-time streaming data and store it in a distributed environment. You can also use Hadoop's HDFS for long-term storage.
Cloud data warehouses (e.g., Redshift, Snowflake) have gained popularity for their scalability, performance, and ease of use. They can ingest data from various sources, including Kafka, to support real-time analytics alongside historical data analysis to derive helpful insights for both streaming and batch data.
However, the above-mentioned tools, including Kafka, face performance issues due to retention policies and management of log segments. Over time, accumulated data can lead to high disk usage, slowing down the data pipeline and adding to running costs.
Redpanda is a Kafka-compatible streaming data platform designed from the ground up to be lighter, more performant, and simpler to operate. Redpanda’s Tiered Storage addresses data challenges by intelligently distributing and cataloging information. It optimizes data placement based on usage and life spans. Regularly accessed data stays in a high-speed tier for fast access, less used data moves to a slower, cheaper tier. This improves overall performance, reduces complexities, and optimizes costs - giving a more effective data storage solution for stream processing.
Reliability
To preserve data integrity and continuous operation, one must ensure reliability and resilience in streaming data pipelines. For example, Apache Flink®, a stream processing engine, provides a built-in mechanism to improve the robustness of data pipelines. It achieves this by state persistence. It stores the intermediate state of computations and recovers them in case of failure.
A process called “checkpointing” is used for the state’s fault tolerance that periodically saves the state of stream processing application into durable storage. Flink also uses a process called “watermarking” that handles time skew and ensures out-of-order events do not have any effect on the results’ accuracy. Both of these features together ensure reliability and resilience across high data volumes.
Error handling
You must ensure your data flows efficiently from the source to the destination. This includes contemplating error handling, backpressure, and retries.
Error handling is extremely crucial for data reliability. To minimize errors, streaming processing frameworks, tools like Data Flow Monitoring Interfaces, and platforms like Apache NiFi offer built-in management mechanisms that automatically identify, report, and handle errors that may arise during data processing.
Other fundamental strategies aid in error handling. For example, backpressure management allows the data pipeline to handle incoming data at a rate that matches its processing capacity. This helps in avoiding overloading of the data that can result in potential data loss or temporarily slow down the system.
Retrying or automatically reattempting to process failed data also increases the chance of successful data delivery without any manual intervention. It increases the data pipelines’ efficiency but may impact throughput.
An impactful strategy in error handling involves implementing a canonical data model to ensure efficient and consistent data management across various pipeline stages. This pattern provides a standardized structure for the data so it's easier to transform and manipulate. It also improves data consistency and reduces complexity ultimately reducing errors.
Security
Security and compliance is the key to building effective streaming data pipelines. These are a few important considerations:
- Always encrypt your data during transmission and storage for optimal security.
- Ensure your entire stream processing pipeline architecture is built according to compliance standards like GDPR and HIPPA or other regulatory requirements of your industry.
- Role-based access control also known as RBAC should be used for handling sensitive data.
Monitoring and tuning
Ensuring the health of the data is a crucial step- monitoring and logging help you identify any issues with the data and quickly resolve them. Monitoring not only helps you improve your optimal performance but also gives you ways to determine whether you need horizontal or vertical scalability.
Determining the optimal timing for scaling your pipeline hinges on the effectiveness of your monitoring strategies. Here are some tuning strategies that you can employ:
- Logic simplification to reduce computations
- State management to effectively manage state to track data flow efficiently.
- Resource allocation and tuning configuration parameters for handling data volume.
- Data partitioning for concurrent processing
We have elaborated on these strategies in detail in the context of Kafka streaming in our article on Kafka optimization.
[CTA_MODULE]
Wrapping up
In the ever-evolving world of streaming data pipeline technologies, various key trends have been emerging. It has been observed that machine learning is being integrated to improve the accuracy of the systems and to keep them optimized.
There had been an increase in focus on scalability and fault tolerance. DataOps and MLOps together are reshaping the data management fostering efficiency across all the operations.
Preservation of data lineage and data quality assurance are also gaining importance to ensure transparency of data. Another new trend is “declarative data pipelines” which allows users to focus on what the system should do and not how to do it making pipelines more user-friendly. These emerging trends are paving the way for more effective and efficient data handling.
[CTA_MODULE]