

Implementing event-driven architectures with Apache Kafka











Event-driven architectures with Apache Kafka®
Event-driven architecture (EDA) is a powerful software architecture pattern where systems respond to and process events in real time. EDA boasts several benefits compared to traditional request-response architectures, including improved scalability, real-time responsiveness, and enhanced resilience and flexibility. Events are the core of any EDA application, and to make the architecture work, you need an event broker. Apache Kafka is one such platform that can power an EDA application by enabling reliable event streaming across distributed systems.
In this guide, you’ll learn about Kafka’s role in EDA, including real-world use cases, key components and patterns, and sample implementations. Although not a step-by-step tutorial, this guide will equip you to understand the principles and implementation of EDA with Apache Kafka.
Overview of event-driven architectures with Kafka
Event-driven architecture refers to a type of system where components respond to events asynchronously, unlike traditional request-response systems where clients send a request and wait synchronously for a response.
An EDA application typically includes several key components:
- Events: Messages each representing an action or state change that has taken place in the system.
- Producers: Software generating events, typically in response to business logic or user actions.
- Consumers: Software subscribing to, receiving, and processing relevant events.
- Event brokers: Software acting as an intermediary between producers and consumers, handling the flow and distribution of events. Kafka fulfills this role in systems where it’s used.
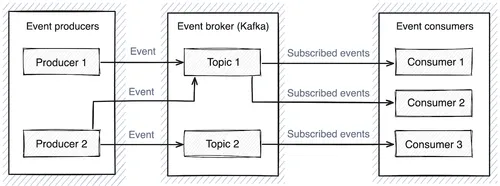
In this architecture, producers can write events to one or more “topics,” which act as ordered collections. Subsequently, one or more consumers can read the events on any topic they are subscribed to. This “pub-sub” mechanism allows multiple subscribers to receive the same message, which enables powerful workflows where many different system components can respond to the same event. This means your consumers can be decoupled from the broader system and focus on handling specific scenarios, creating new consumer services as needed.
By decoupling producers and consumers, each service can operate independently of the other services. This allows events to be processed without relying on synchronous requests or waiting for responses. Thanks to this approach, event-driven architecture offers several key advantages over traditional request-response systems:
- Scalability: Because components are decoupled, EDA systems can handle higher volumes of throughput by scaling specific components without needing to scale the entire system.
- Real-time processing: Consumers act in response to events in real time rather than batching events up to be processed later.
- Resilience: Reduced dependency between services results in increased resilience for the entire system. If one service goes down, it won’t necessarily bring down the rest of the system.
- Decoupled: Because the services are decoupled from each other, it’s possible for them to evolve individually as needed, without impacting other services, so long as changes are reverse compatible.
As mentioned, the event broker handles the flow and distribution of events in an EDA system. While many tools can fulfill this role, Kafka is a proven and powerful option. Pub-sub systems like Kafka store messages centrally and deliver them to consumers that subscribe to relevant topics. This allows multiple consumers to receive the same message, enabling parallel workflows. In addition to this, Kafka has other features that make it well-suited for distributed EDA:
- Partitioning: Kafka divides topics into partitions, which allows data to be distributed across multiple brokers in a cluster.
- Durability: Events are written to disk and replicated across brokers in a cluster, ensuring data resilience if a broker should fail.
- High throughput: Kafka’s efficient handling of I/O operations allows it to handle millions of messages per second with low latency.
- Fault tolerance: Kafka’s distributed architecture replicates partitions across brokers, providing redundancy and fault tolerance. If a broker goes offline, the system handles electing a new leader if necessary.
These features make Kafka a powerful, scalable solution for building event-driven systems that need to handle large volumes of real-time data.
Building an event-driven system with Apache Kafka
There are several things you need to be aware of when building an EDA system with Kafka. In the following sections, we’ll cover:
- Key components of an EDA system, including producers, consumers, and Kafka topics.
- How to define and manage event types to ensure structured and consistent data processing.
- How Schema Registry ensures consistency in event-driven systems by enforcing defined schemas for producers and consumers.
- Strategies for managing event delivery, including retries, acknowledgments, and delivery guarantees.
- Best practices for data retention to manage growing event logs.
Key components
The fundamental building blocks of an EDA system are the producers and consumers. Producers are responsible for sending events to Kafka topics, while consumers read those events and can act on them. A single application can act as a producer, a consumer, or both. In cases where the same application is both a producer and a consumer, it will most likely be reading and writing from different topics.
Kafka topics act as ordered logs where events are stored. These are the connective tissues that allow different components of your system to communicate in a decoupled fashion. Topics can be partitioned across multiple brokers to allow for improved scalability and parallel processing of events.
Kafka also offers a powerful stream processing API that allows you to filter, transform, and aggregate event streams from a given topic. This processed data can then be written to a different topic to be picked up by other consumers.
Event types
While Kafka is flexible about event content, it’s crucial that you define and use strict event types for specific purposes. Consider each event’s purpose and required data carefully. The producers and consumers should agree on and respect a consistent format. This format acts as a well-known schema that other producers and consumers can use, knowing that other system components will be able to process messages that conform to the schema. When schema modifications are necessary, implement schema evolution to ensure that the changes you make will be handled gracefully by the components of your system.
Schema Registry
Defined schemas are only valuable if they’re enforced. You can use Schema Registry to enforce your schemas for producers and consumers and to assist in the serialization and deserialization of events. Kafka Schema Registry allows you to validate your events so that only compliant events are produced. This helps maintain consistency across your components.
You can use standards like AsyncAPI to help standardize your events and their schemas. AsyncAPI provides a structured way to document and design event-driven APIs. Think of it like OpenAPI Spec for event-driven systems.
Managing event delivery
With your schema and event interfaces defined, the next thing is to ensure that events are delivered as expected. It’s a fact that distributed systems will eventually encounter communication faults like network errors, outages, or lost packets. The question is whether the system will be able to handle the fault and recover gracefully.
There are various levers you can use to control event delivery for both the producers and consumers. On producers, you can configure things like:
- Acknowledgment level: This determines whether the producer will wait for any acknowledgment from the broker when sending an event. No acknowledgment is quicker but can be risky if a broker crashes.
- Retries: This determines how many attempts a producer should make before giving up if a message fails to send.
- Idempotence: Enabling this can help prevent duplicate messages if a producer retries a message delivery.
On the consumer side, there are also a few things to be aware of when it comes to event delivery:
- Consumer groups: Kafka ensures that each message from a given topic partition is consumed only once by a consumer in a given consumer group.
- Offset management: Kafka keeps track of where a consumer is up to in a topic using offsets. Consumer offsets can either be managed automatically or manually, depending on your requirements.
- Delivery guarantees: Depending on the types of events you’re processing, there are different delivery guarantees you can choose from, such as at-most-once, at-least-once, and exactly-once.
Data retention
If your system generates a lot of events, your topics might eventually grow bigger than you’d like. You can mitigate this by configuring data retention to determine how long events will remain in the topic’s log file.
Implementing an event-driven architecture with Kafka
To help solidify your understanding of EDA with Kafka, this section will walk you through a simple EDA application.
Naturally, the first piece of the puzzle is Kafka itself. In a production environment, you’d probably use a highly available Kafka cluster. However, for demonstration purposes and local development, you can run a single-node cluster in a Docker container on your development machine.
With a fresh cluster, there isn’t much to see until you create some topics. You can see your current topics using one of the included scripts:
ubuntu@kafka-server:~$ docker exec -it kafka /opt/kafka/bin/kafka-topics.sh --list --bootstrap-server localhost:9092
__consumer_offsets
To populate some data into the cluster, you need event producers. This demo application is a simple financial transaction application that records transactions against an account number and tracks the balance. To implement this, you first need a producer that can emit transaction events.
The producer
One of the advantages of EDA applications is that, thanks to the loose coupling between components, you can write them in the language of your choice (with a few caveats; more on that shortly). For Python, there are packages like kafka-python that make writing producers and consumers fairly straightforward. Using such libraries, you can create a simple CLI application that takes an account number and amount and dispatches an event to a transactions topic.
You can invoke this producer by running it from the command line like so:
$ python3 producer.py ACC1234 150 #Deposit 150 into ACC1234You can see the code for this producer on GitHub.
Still, a producer without a consumer is only a partial system, so next, you need another application to read this data.
The consumer
You can create consumers using the same Python library. In this case, the consumer will subscribe to the transactions topic and parse events as they come in before updating the relevant account’s balance in an in-memory dictionary and displaying the balance in the terminal. When run, the consumer processes both existing and new events from the topic:
$ python3 consumer.py
Consumer started, waiting for transactions...
Account ID: ACC1234 - New Balance: 150.0
Account ID: ACC1234 - New Balance: 275.0You can see the code for this consumer on GitHub.
Just like that, you have two separate software components communicating via events sent over Kafka. This is an EDA application in its simplest form.
Event streaming
As mentioned, you can use Kafka with pretty much any language, as there is excellent library support for most popular languages. One thing to keep in mind, however, is that the Streams API discussed previously is a feature of the Kafka Java library. This API allows you to build scalable, fault-tolerant applications that excel at reading and writing data at high volumes. Consider this example application taken from the official documentation, annotated with comments:
import org.apache.kafka.common.serialization.Serdes;
import org.apache.kafka.common.utils.Bytes;
import org.apache.kafka.streams.KafkaStreams;
import org.apache.kafka.streams.StreamsBuilder;
import org.apache.kafka.streams.StreamsConfig;
import org.apache.kafka.streams.kstream.KStream;
import org.apache.kafka.streams.kstream.KTable;
import org.apache.kafka.streams.kstream.Materialized;
import org.apache.kafka.streams.kstream.Produced;
import org.apache.kafka.streams.state.KeyValueStore;
import java.util.Arrays;
import java.util.Properties;
public class WordCountApplication {
public static void main(final String[] args) throws Exception {
Properties props = new Properties();
props.put(StreamsConfig.APPLICATION_ID_CONFIG, "wordcount-application");
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "kafka-broker1:9092");
props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());
StreamsBuilder builder = new StreamsBuilder();
// Create a stream from the Kafka topic "TextLinesTopic"
KStream<String, String> textLines = builder.stream("TextLinesTopic");
// Process the stream:
// 1. Split each line of text into words
// 2. Group by word
// 3. Count occurrences of each word
KTable<String, Long> wordCounts = textLines
.flatMapValues(textLine -> Arrays.asList(textLine.toLowerCase().split("\\W+")))
// Break each line into words (splitting by nonword characters and converting to lowercase)
.groupBy((key, word) -> word)
// Group words together; the key for grouping is the word itself
.count(Materialized.<String, Long, KeyValueStore<Bytes, byte[]>>as("counts-store"));
// Count the number of occurrences of each word, storing results in a state store named "counts-store"
// Write the word counts to the Kafka topic "WordsWithCountsTopic"
wordCounts.toStream().to("WordsWithCountsTopic", Produced.with(Serdes.String(), Serdes.Long()));
// Convert the KTable back to a stream and produce key-value pairs to the output topic
// Create and start the Kafka Streams application
KafkaStreams streams = new KafkaStreams(builder.build(), props);
streams.start();
}
}
This application reads data from one topic, creates a state store, transforms it, and writes it to a new topic in a streaming fashion. State stores in Kafka streams are a mechanism that allows you to track and query state locally within a streaming application. This facilitates operations like aggregations and joins that you might want to perform, which would otherwise be difficult if you were dealing with events ephemerally.
This is a flexible pattern that can be powerful in real-time applications, although the official library is only supported in JVM languages.
Despite this, there are community packages that implement similar behavior for other languages, such as:
- Faust for Python
- kafka-streams for Node.js
- KStream for Golang
Event sourcing and CQRS
Event sourcing is another pattern that works well with EDA and Kafka. With event sourcing, your system’s state is built by replaying the events in your event log. For applications like the financial demo example, this approach makes a lot of sense, as the account balance is naturally the result of applying all the transactions in sequence. Instead of updating a database record with the current balance each time a transaction happens, the current balance is derived from the source of truth—the events. This is a highly reliable, resilient, and auditable approach. An event sourcing application will still typically need a database to store the events as they come in. This allows the state to be reconstructed as needed without needing to replay everything from Kafka. Modifying the consumer demo to implement event sourcing, backed by an SQLite database, results in the following:
$ python3 consumer-event-sourcing.py
Rebuilding state from persisted events...
State rebuilt: {'AC1234': [{'account_id': 'AC1234', 'amount': 200.0}, {'account_id': 'AC1234', 'amount': 400.0}, {'account_id': 'AC1234', 'amount': 100.0}], 'AC345': [{'account_id': 'AC345', 'amount': 4000.0}, {'account_id': 'AC345', 'amount': 40.0}, {'account_id': 'AC345', 'amount': 50.0}]}
Consumer started with persistent storage, waiting for transactions...
Account ID: AC1234 - Amount from event: 100.0, New balance: 800.0
Account ID: AC345 - Amount from event: 40.0, New balance: 4130.0
Account ID: AC345 - Amount from event: -500.0, New balance: 3630.0In this demo, the consumer constructs its initial state from the stored events in the database and then proceeds to apply new events over the top as they come in. This results in a more reliable consumer than one that only holds events in memory. The code for this demo can be seen on GitHub.
If you implement event sourcing, it’s worth considering command query responsibility segregation (CQRS) as well. This is a pattern that stipulates that writes (commands) from reads (queries), allowing the system to scale independently. Extending this financial demo application to leverage event sourcing and CQRS might look something like this:

In the sequence depicted above:
- The user initiates a transaction (such as debit or credit).
- The producer (transaction service) produces an event (such as Debit or Credit) and sends it to Kafka.
- The event is stored in the Kafka topic acting as the event log.
- The consumer (event processor) consumes the event and applies it to update the balance.
- The balance service maintains the current state by applying the event.
- The user queries the balance, and the service returns the updated amount.
Monitoring your cluster
Since your event broker (Kafka in this case) is a critical part of your application, it’s important to establish a proper observability practice in place to ensure its uninterrupted functionality.One popular way of doing this is with Grafana and Prometheus. Using a Kafka Prometheus exporter, you can channel stats about your cluster into Grafana for monitoring and reporting. Depending on your requirements, you can create high-level dashboards that give you an overview of the cluster’s health:

You can also create more specific dashboards that allow you to keep an eye on things like broker throughput, request latency, disk I/O, and under-replicated partitions to determine whether your system is operating as efficiently as possible:
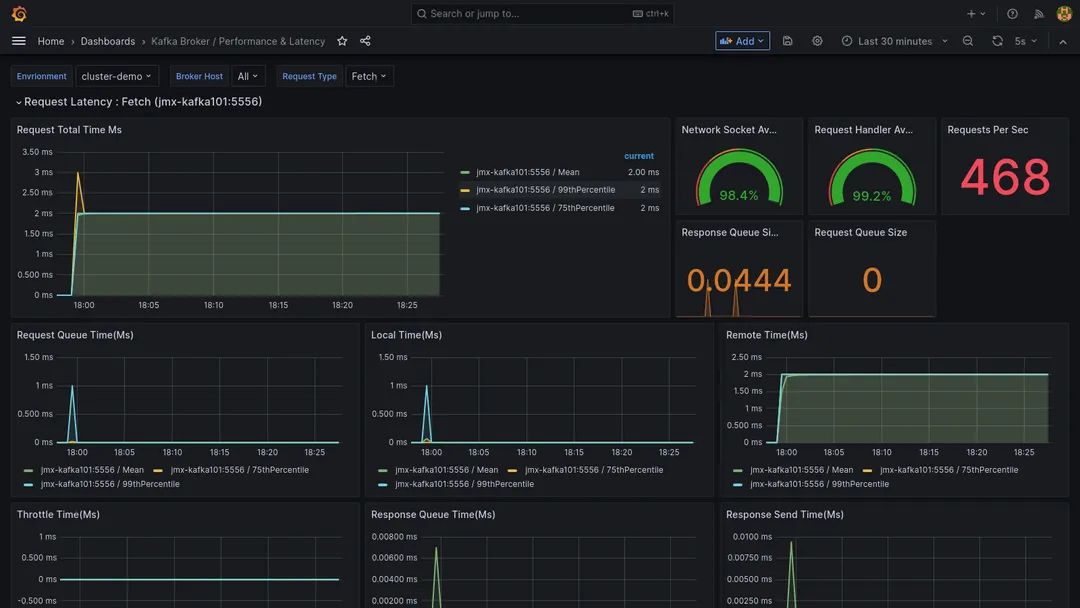
The configurations for the dashboards shown above come from this project on GitHub.
By having data from your cluster exported to Grafana, you might discover potential optimizations you can make, such as:
- For your producers:
- Adjusting batch size to allow more messages to be sent per event
- Employing parallelism to increase producer throughput when demand is high
- Tuning compression to strike a balance between network usage and CPU overhead
- For your consumers:
- Improving parallelism by adding more consumers to a given consumer group
- Tweaking polling settings to optimize for message fetching
- Optimizing message processing logic to minimize the time spent per message
EDA systems can be highly complex, so it’s essential that you monitor the system adequately to ensure things are working as expected.
Real-world use cases for an event-driven architecture with Kafka
Many scenarios requiring real-time data processing can benefit from EDA with Kafka, such as:
Personalized recommendations
User activity, like clicks and searches, can be captured as events and streamed in real time to recommendation engines, enabling tailored suggestions for e-commerce and streaming platforms.
Fraud detection
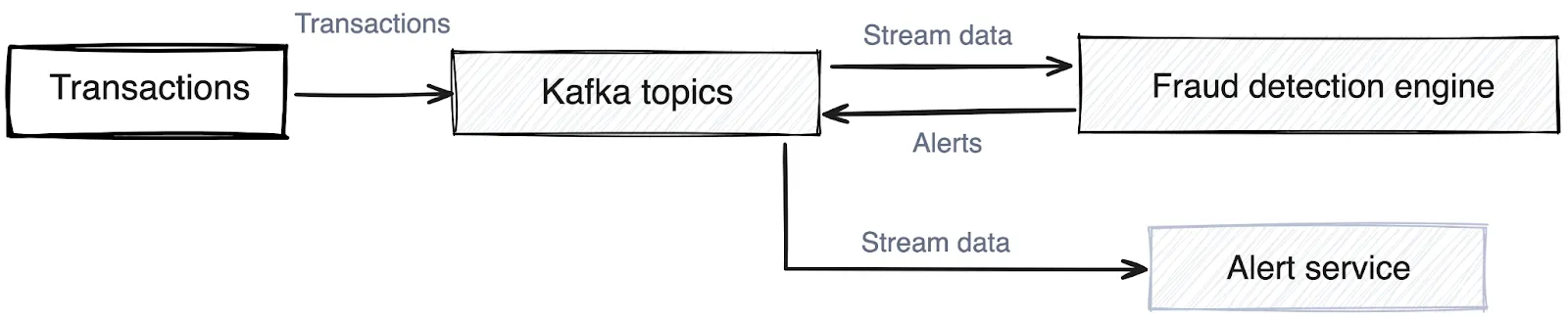
Kafka can stream transaction events in real time to a fraud detection engine that monitors for suspicious patterns and can trigger alerts when anomalous behavior is detected.
Order fulfillment
In e-commerce, Kafka enables an event-driven workflow where each phase of an order’s lifecycle—from inventory management to payment and shipping—generates events delivered to relevant system components.
Network monitoring
Kafka collects traffic and performance events from networked computer systems, streaming this data to services for analysis to detect anomalies and help optimize system performance.
IoT device management
Kafka can ingest data from IoT devices like sensor readings and status updates while also allowing devices to subscribe to topics and receive instructions.

Inventory management
Using event sourcing, Kafka can store all events causing stock level changes, allowing current inventory levels to be derived by replaying these events in sequence.

Real-time analytics
Kafka streams logs, transactions, and interactions to analytics platforms, creating real-time dashboards and insights that support immediate, data-driven decision-making.
A summary of event-driven architecture with Apache Kafka
Event-driven architecture is a powerful pattern for applications that need real-time, high-throughput, and highly scalable data processing. Still, an EDA application is only as good as the event broker that holds everything together. Kafka is a popular choice for many large-scale, data-intensive use cases where real-time data movement is important; it offers stability, scalability, and proven performance for some of the most demanding EDA systems.
However, setting up and maintaining a Kafka cluster can introduce significant complexity. This includes extensive configuration, ongoing maintenance, and resource overhead, which can become a barrier for teams adopting EDA. Redpanda addresses these challenges with a simpler deployment model, offering Kafka API compatibility in a single-binary solution. It eliminates the need for external dependencies, reduces operational costs, and streamlines cluster management.
By combining effortless deployment with higher throughput and lower latency, Redpanda provides an efficient, cost-effective alternative for organizations looking to embrace event-driven systems without the operational burden of traditional Kafka clusters. It allows businesses to focus on building applications rather than managing infrastructure, making EDA more accessible and practical for a broader range of use cases.
To explore Redpanda and how it can streamline your architecture, check the documentation and browse the Redpanda blog for use cases and tutorials. If you have questions or want to chat with the team, join the Redpanda Community on Slack.