

Apache Kafka messaging system











Introduction to the Apache Kafka® messaging system
Author: Manish Hatwalne
Like a digital video recorder (DVR) that records shows broadcast by TV channels (producers) into categories, Apache Kafka® organizes data streams into topics. Just as multiple viewers (consumers) can watch recorded shows independently, different applications can process Kafka’s stored messages at their own pace. And, similar to how a DVR deletes old recordings after a set time, Kafka automatically removes messages after a configurable retention period.
Kafka provides reliable, real-time communication across services and is particularly well-suited for handling high-volume data streams asynchronously.
In this tutorial, you’ll learn about Kafka’s core concepts and architecture, and you’ll explore how producers and consumers work together for seamless data exchange.
Apache Kafka as a messaging system
Apache Kafka is a high-performance, distributed messaging platform that enables real-time data exchange at scale. It acts as a central hub where applications can send (produce) and receive (consume) large volumes of data, facilitating seamless communication across distributed systems.
Kafka is built for scalability and fault tolerance. It divides data into partitions for parallel processing, which enables efficient scaling as workloads grow. For reliability, messages are persisted to disk and replicated across brokers (servers), ensuring data remains available even during broker failures or heavy loads. This robust design makes Kafka ideal for event streaming, log aggregation, and real-time analytics, where reliable, high-throughput processing is essential.
Did you know? Kafka began as an internal project at LinkedIn around 2010 and was later open sourced and donated to the Apache Foundation. Today, it’s widely used as a messaging and data streaming system. Netflix leverages Kafka for instant TV show recommendations, while Uber relies on it for dynamic fare calculations based on real-time data like demand, traffic, and cab availability.
Key components of Apache Kafka messaging
The Apache Kafka overview below shows that multiple producers can send messages to a cluster of brokers (servers), and multiple consumers can retrieve those messages. The cluster consists of multiple brokers (each containing partitions) and is managed by ZooKeeper.
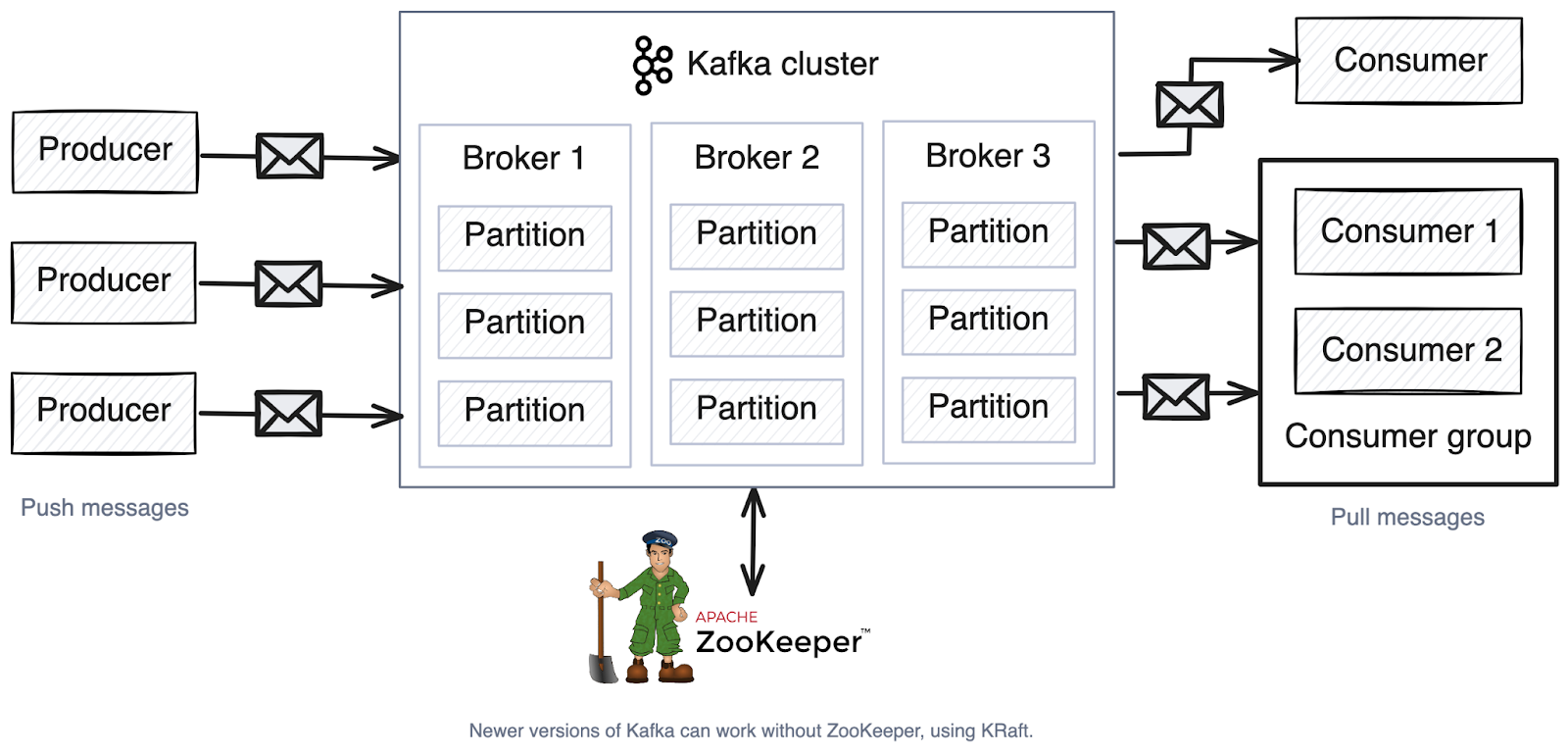
Producers
Producers are applications that send messages to Kafka. They publish messages to specific topics and can include metadata (such as timestamps or keys) to help organize and process the data. Producers may include orders in e-commerce applications, sensors in IoT devices, logs, and so on.
You can write Kafka producers using languages like Python or Java or simply use Kafka’s built-in shell client, as shown below:
kafka-console-producer.sh \
--topic test-topic \
--bootstrap-server localhost:9092After starting the producer, you can type messages directly into the console:
> This is a test message sent to the topic: test-topic.Each message is sent to the specified Kafka topic when you press Enter.
Topics and partitions
A topic is a category or channel where messages are stored and organized. Think of it like a named folder for related messages. For example, you might have topics like user-signups or orders.
So, a topic called orders with three partitions might look like this:
Topic: orders
├── Partition 0: [message0] → [message3] → [message6]
├── Partition 1: [message1] → [message4] → [message7]
└── Partition 2: [message2] → [message5] → [message8]A partition splits a topic into multiple parts for better performance and scalability. Each partition is an ordered, immutable (non-modifiable) sequence of messages that represents a portion of the topic. Partitions are numbered (starting from 0) and can be distributed across multiple brokers, allowing for parallel processing.
The following configurations determine how topics and partitions are used:
- Number of partitions: This specifies how many partitions there are for a topic. More partitions allow for higher throughput since data can be processed in parallel.
- Replication factor: This sets the number of copies for each partition. If set to three, each partition is copied to three different brokers. This helps prevent data loss; if one broker fails, others have backup copies.
- Retention types: Kafka stores messages based on configurable retention policies, which can be time-based (eg 7 days), size-based (eg 1 GB per topic), or a combination of both. These policies ensure messages remain available for consumers while preventing unlimited storage growth.
For instance, the following Kafka command creates a topic named my-topic with ten partitions and a replication factor of three:
kafka-topics.sh \
--create \
--bootstrap-server localhost:9092 \
--replication-factor 3 \
--partitions 10 \
--topic my-topicConsumers and consumer groups
Consumers are applications that read messages from Kafka topics. Consumer groups are collections of consumers that divide up the reading work: Each partition is read by exactly one consumer in a group. If a consumer fails, Kafka automatically assigns its partitions to other consumers in the group.
You can write Kafka consumers using languages like Python or Java or simply use Kafka’s built-in shell client, as shown below:
kafka-console-consumer.sh \
--bootstrap-server localhost:9092 \
--topic test-topic \
--from-beginningThis consumer will read messages from the specified Kafka topic and print it in the console.
Brokers
A Kafka broker is a server that stores and manages topics and their partitions. Multiple brokers work together in a cluster, with each broker acting as the “leader” for a selection of partitions while also storing backup copies of partitions managed by other brokers. One broker also acts as the cluster controller, handling how partitions are spread across brokers and monitoring if all brokers are healthy.
ZooKeeper
ZooKeeper is a coordination tool used by Kafka for managing metadata and ensuring high availability. It’s like a supervisor for Kafka brokers—it keeps track of which brokers are alive, the cluster leaders, and what topics and partitions exist. It stores all this information and helps brokers coordinate with each other. When a broker fails, ZooKeeper reorganizes the work among remaining brokers.
Note: Newer versions of Kafka (3.3+) are moving towards replacing ZooKeeper with an internal system, KRaft, for better scalability and simplicity.
Apache Kafka architecture
Kafka’s architecture is designed for scalability, fault tolerance, and reliability, making it ideal for use cases like event streaming, analytics, and fault-tolerant microservices communication. The following are the key features that enable this.
Distributed nature
Kafka’s distributed nature allows it to operate as a cluster of brokers, where data is spread across multiple servers. This setup ensures fault tolerance through replication; if one broker fails, another takes over. It can also easily add more brokers to handle growing data loads without downtime, which contributes to scalability and ensures the system remains reliable under heavy use.
Decoupled producers and consumers
Kafka uses a “pub/sub” model to decouple producers (data senders) from consumers (data receivers). Producers send messages to Kafka topics without waiting for consumers to process them, enabling asynchronous communication. Consumers, in turn, can read data independently, with different groups processing the same data for various purposes. This flexibility makes Kafka ideal for event-driven architecture.
Log-based storage system
Kafka stores messages in logs, which are append-only files on disk where new messages are continuously added to the end. These logs can be configured to retain messages based on either time duration or storage size limits. This means you can keep messages for a specific period (such as 7 days) or until they reach a certain storage threshold (like 1 GB). This retention policy gives consumers the flexibility to replay messages from any point by resetting their offset position—essentially their bookmark in the log. This capability is crucial for scenarios like debugging production issues, reprocessing data after fixing bugs, or conducting data audits. Since messages are written to disk rather than kept in memory, they survive broker restarts or crashes, ensuring data durability.
Here are examples of configuring retention policies using Kafka commands:
Time-based retention (7 days = 604800000 ms):
kafka-configs.sh \
--bootstrap-server localhost:9092 \
--entity-type topics \
--entity-name my-topic \
--alter \
--add-config retention.ms=604800000Size-based retention (1 GB = 1073741824 bytes):
kafka-configs.sh \
--bootstrap-server localhost:9092 \
--entity-type topics \
--entity-name my-topic \
--alter \
--add-config retention.bytes=1073741824High availability via replication and partitioning
Kafka achieves high availability through replication and partitioning. Each topic is divided into partitions distributed across brokers for parallel processing. Replication ensures that each partition has multiple copies, so data remains accessible even during failures. This combination of replication and partitioning enables Kafka to process large data volumes efficiently.
Implementing messaging with Apache Kafka
For implementing a messaging demo with Kafka, you can set up Kafka locally with Docker. You can refer to this tutorial for detailed instructions.
Creating and configuring topics
Once your Kafka setup is running, you can create a topic (for example, orders) using the following command in a terminal:
docker exec -it kafka \
kafka-topics \
--create \
--bootstrap-server localhost:9092 \
--replication-factor 1 \
--partitions 1 \
--topic ordersThis command creates a topic named orders with one partition and a replication factor of 1.
Created topic orders.To view all existing topics in your Kafka instance, use this command:
docker exec -it kafka \
kafka-topics \
--list \
--bootstrap-server localhost:9092Implementing a Kafka producer in Python
As mentioned earlier, you can create Kafka producers using various programming languages, including Python and Java. Below is an example of a Python-based Kafka producer using the kafka-python library:
from kafka import KafkaProducer
# Kafka configuration
bootstrap_servers = ["localhost:9092"]
topic = "orders"
# Initialize the Kafka producer
producer = KafkaProducer(bootstrap_servers=bootstrap_servers)
# Send 10 messages to the topic
for i in range(10):
ack = producer.send(topic, f'Order #{i+1}'.encode())
metadata = ack.get() # Get metadata for confirmation
# Optionally, you can access metadata.topic and metadata.partition here
print("Produced 10 orders.")This Python code sets up a Kafka producer that sends ten messages, each representing an “order,” to the orders topic. KafkaProducer is initialized with the Kafka server’s address, and the send() method sends each message, encoded as bytes, to the topic. After each message is sent, the ack.get() method retrieves metadata confirming the message was successfully delivered, such as the topic and partition. Finally, the program prints that it has produced ten orders.
Implementing a Kafka consumer in Python
Similarly, in order to create a Python-based Kafka consumer that reads messages from the orders topic, you can use the following code snippet:
from kafka import KafkaConsumer
import sys
# Kafka configuration
bootstrap_servers = ["localhost:9092"]
topic = "orders"
# Initialize the Kafka consumer
consumer = KafkaConsumer(
topic,
group_id="group1",
bootstrap_servers=bootstrap_servers,
auto_offset_reset="earliest" # Start reading from the earliest available message
)
try:
print("Consumer reading messages...")
for message in consumer:
print(f"\t{message.topic}: {message.partition}:{message.offset}: key={message.key} value={message.value}")
except KeyboardInterrupt:
print("Consumer exit.")
sys.exit()This Kafka consumer connects to the orders topic and continuously reads messages. KafkaConsumer is initialized with parameters like the topic name, a group ID (group1 for consumer grouping), and auto_offset_reset set to "earliest" to start reading from the beginning of the topic. In the for loop, the consumer iterates over incoming messages, printing details such as the topic, partition, offset, key, and message value. The program gracefully exits with an “exit” message when interrupted (via Ctrl+C). This setup enables processing Kafka messages in real time.
Advanced messaging patterns
Kafka supports two messaging patterns for communication between distributed applications: the pub/sub pattern and the request-reply pattern.
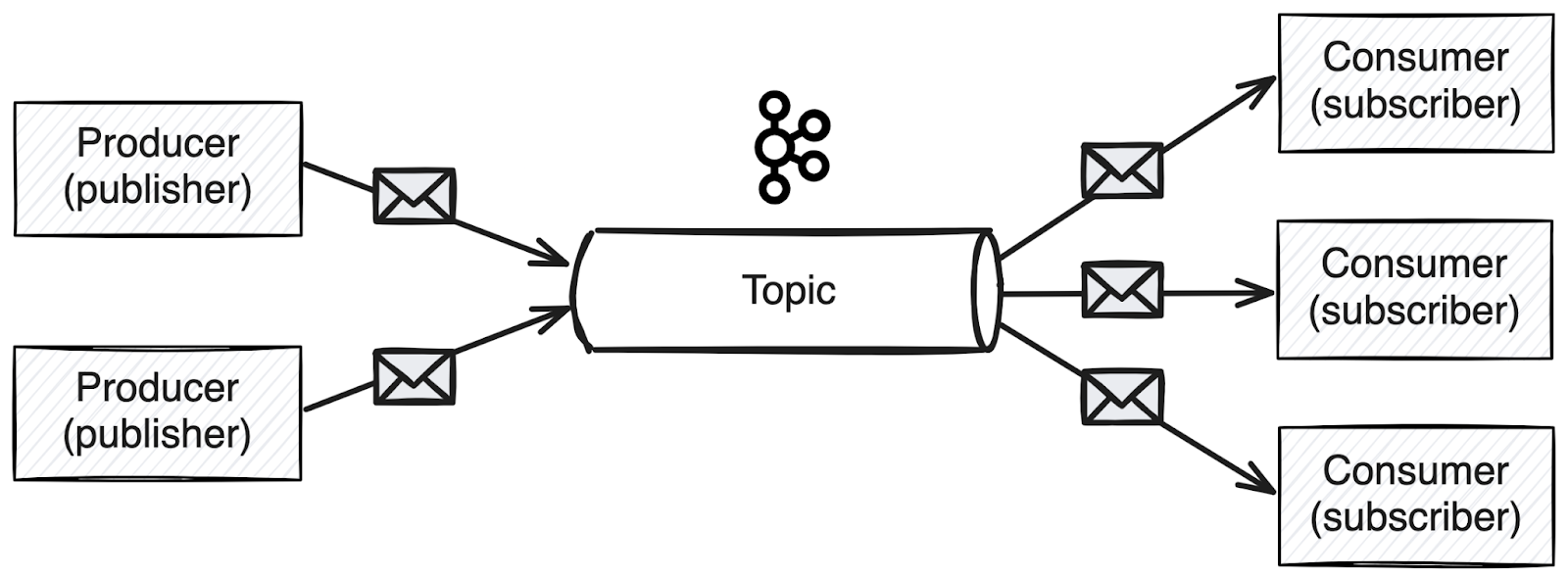
Pub/sub pattern
The pub/sub pattern allows multiple consumers to subscribe to a topic and independently consume messages from it. A producer publishes messages to a topic, and any number of consumers can read those messages without affecting one another. This pattern is ideal for broadcasting events or updates, such as notifying multiple services about a new order. Kafka’s log retention policy supports this by keeping messages available for all subscribers within the configured retention period. This pattern is suitable for event-driven architectures and real-time notifications.
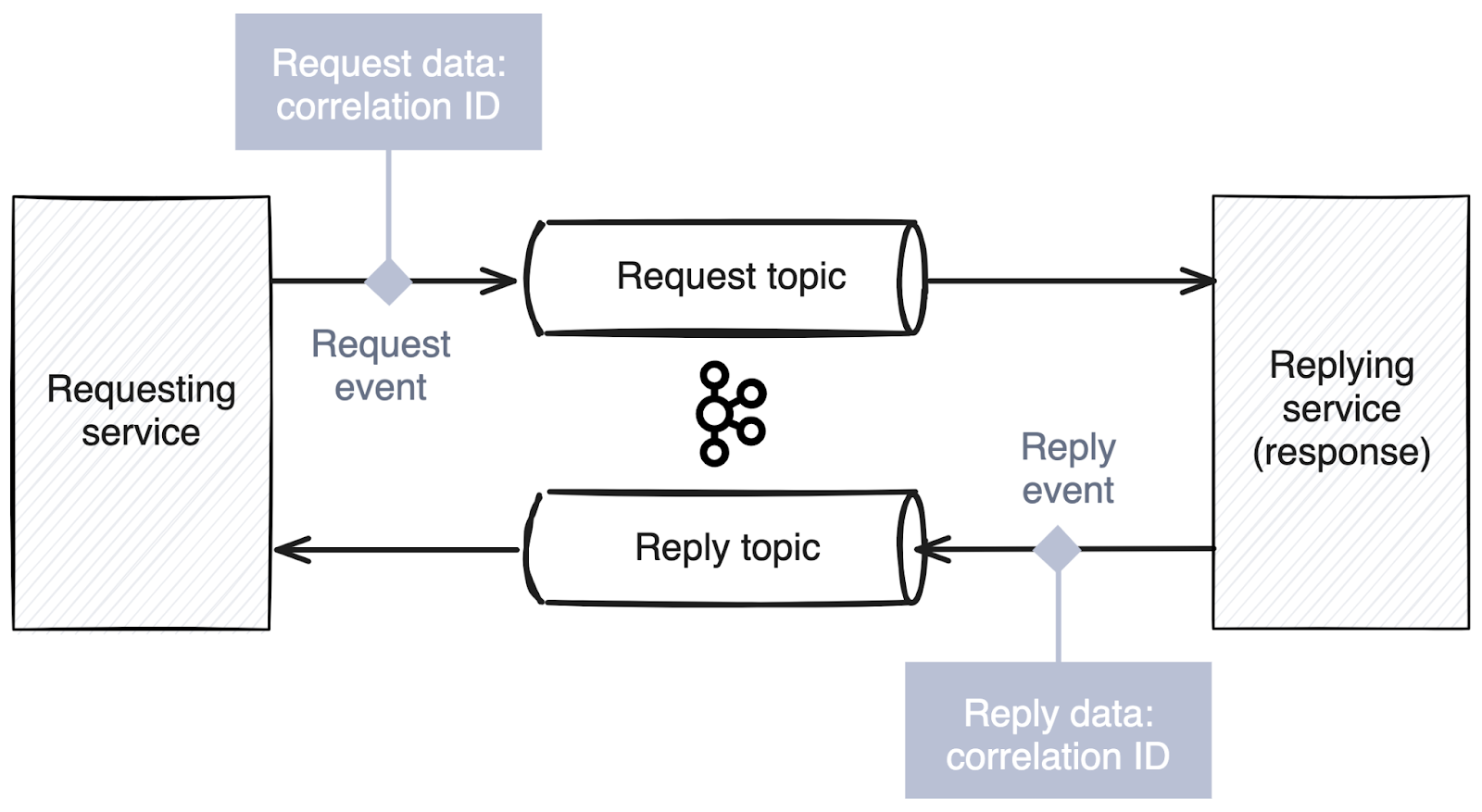
Request-reply pattern
The request-reply pattern enables synchronous communication between services while using Kafka’s asynchronous model. A service sends a request message to a dedicated request topic and includes a correlation ID and reply-to topic. The receiving service processes the request, then sends the response to the specified reply-to topic with the matching correlation ID. The original sender listens on the reply-to topic for messages with its correlation ID, effectively creating a two-way conversation while preserving Kafka’s decoupled architecture. This pattern is used for service queries and commands requiring responses where tracking request-response pairs is crucial.
Monitoring key Kafka metrics
Kafka can provide seamless communication between distributed systems, acting as a high-throughput, fault-tolerant messaging platform. However, to maintain the high performance and reliability of its clusters, there are a few key metrics you need to monitor. These metrics include:
- Throughput: This measures the rate of messages produced and consumed, highlighting bottlenecks in the system.
- Latency: This tracks the time messages take to traverse the system, critical for maintaining real-time processing.
- Error rates: These monitor issues like failed deliveries or consumer errors, signaling potential communication or processing problems.
- Message backlogs: These identify unprocessed messages in queues, ensuring consumers can keep pace with producers.
Tools like Prometheus (for metrics collection) and Grafana (for visualization) help track these metrics and provide real-time insights through dashboards so you can proactively identify and resolve issues.
Securing Kafka
Securing Kafka should be a priority because it processes sensitive data across distributed systems in real time, making it vulnerable to unauthorized access and misuse. The following are some key security measures that help protect Kafka from threats:
- Encrypting communication: Use SSL/TLS to secure communication between clients and brokers, protecting data in transit and preventing man-in-the-middle attacks.
- Authenticating connections: Set up SASL to authenticate users or applications. Common mechanisms include SCRAM and Kerberos.
- Controlling access: Use Kafka’s built-in ACLs (Access Control Lists) to enforce topic-level permissions, ensuring only authorized entities can produce, consume, or manage specific topics.
Adopting these security measures helps protect data, ensure only authorized users can access it, and maintain system reliability.
Alternatives to the Apache Kafka messaging system
Kafka is more than a simple messaging system; it’s a powerful platform designed for high-throughput, real-time data streaming in large-scale distributed systems. However, not all applications need this level of complexity. Simpler alternatives like RabbitMQ and ActiveMQ may be better suited for lower-latency, traditional message queuing with easier setup and management.
RabbitMQ
RabbitMQ is a message queuing broker that pushes messages directly to consumers, which is ideal for real-time transactions needing guaranteed delivery. It offers flexible routing patterns, making it well-suited for complex workflows and low-latency service communication.
In contrast, Kafka is a pull-based system designed for high-throughput event streaming, data pipelines, and event-driven architectures.
ActiveMQ
ActiveMQ is an open source message broker with a queue-based architecture designed for reliability and compatibility with messaging standards, particularly Java Message Service (JMS). It supports persistent queues and multiple messaging protocols, making it ideal for legacy system integration.
With its simple setup and lower resource needs, ActiveMQ suits smaller-scale, low-volume messaging systems where Kafka’s high throughput and durability aren’t required.
Conclusion
This article introduced the fundamentals of Apache Kafka, including its role as a distributed messaging system and its key components, like producers, consumers, and topics. Through Python-based producer and consumer examples, you explored how Kafka enables efficient data exchange. You also examined Kafka’s security practices as well as important monitoring metrics for Kafka clusters. Lastly, you looked at alternatives like RabbitMQ and ActiveMQ to understand when they might be better suited than Kafka.
Redpanda is a high-performance, Kafka-compatible streaming platform designed to simplify real-time data processing by removing the need for external dependencies. Its optimized architecture improves performance, reduces latency, and scales efficiently, enabling organizations to integrate seamlessly with Kafka tools while reducing complexity.