





Deploy agents you can trust with centralized AI governance
You can't scale what you can't trust. A governance layer fixes that.

Learn the proven architectural guidelines powering today’s successful FinTech operational systems








In an asynchronous architecture, services communicate by raising asynchronous events. These events are handled by an event broker, an integration middleware, or an event streaming platform. For example, when a client orders the purchase of a stock, the Order Service publishes the OrderReceived event to the event broker. The Account Service, subscribed to this event, responds by publishing either an OrderValidated or OrderRejected event.
This blog suggests separating your write path (Commands) from your read path (Queries) as a best practice. This approach, known as Command Query Responsibility Segregation (CQRS), is beneficial for event-based architectures. It helps to address the drawback of event sourcing where you always have to replay events from the beginning to understand the current state of your systems.
This blog suggests five best practices for building FinTech operational systems: decomposing business logic as microservices, opting for asynchronous, event-driven communications, securing a single source of truth with event sourcing, implementing queries with CQRS and materialized views, and deploying microservices as containerized or serverless workloads.
Event sourcing works like a natural audit log for all events in the system, providing rich contextual information like the doer, action, time, and more. If you choose an event broker with lifetime retaining of events, you secure a complete history of your system. You can always go back to a particular point in time, replay events from there, and derive the system’s current state.
Decomposing business logic into microservices allows them to be developed, managed, and owned by independent teams. This approach can speed up the delivery of business needs to the market and have a positive effect on operational costs since microservices can be deployed independently and scaled based on demand.
Welcome to part two of our series on operational systems for the FinTech sector. In our first post, we looked at the challenges and benefits of FinTech, as well as how to simplify streaming data for FinTech systems.
To briefly recap, FinTech operational systems need to be fast, scalable, accurate, and reliable. This alone forces us to rethink our usual software design and development practices. But there’s a particular need to consider FinTech business logic as well. This second installment digs into the challenges and architectures behind successful FinTech operational systems, and covers the following five best practices when building them:
We’ll present each guideline with a handy example, and explain how they might benefit your own use case. Let’s dig in.
In our first blog, we covered the technical aspects of what makes FinTech operational systems challenging to design, develop, and operate. Now, to fully appreciate the following guidelines, we also need to talk about business logic.
FinTech covers an exciting range of new technologies that improve and automate finance. Sometimes, these new developments also represent unchartered territory for regulators. So while the traditional finance sector faces strict regulations, FinTech companies sometimes set new standards for compliance requirements by coming up with novel ways of solving finance issues.
These regulations are one of the reasons why it’s a best practice for FinTech operational systems to be built on microservices and asynchronous communication. To spare you from operational expenses and headaches down the road, we’ll break down this approach into five best practices.
Transactional systems often undergo new business requirements. Especially in the FinTech domain, regulations and compliance requirements are inevitable, frequently demanding new changes to be accommodated to the application architecture.
We used to develop applications with a monolithic approach, but an application built on one huge code base is hard to understand, test, scale, and reuse—no matter the sector. So, it’s a good idea to decompose business logic into independent business contexts represented by specific microservices.
Microservices are a popular choice for application development. For FinTech, in particular, they are crucial. Breaking up applications into microservices that can run independently of one another allows them to be developed, managed, and owned by independent teams. These teams can be in one organization or across several organizations, and responsibilities can be distributed across these smaller teams with clear ownership boundaries.
When each team can build, release, and manage its own services, business needs can be shipped to market much faster. There’s also a positive effect on operational costs since microservices can be deployed independently and scaled based on demand.
A transactional system built with microservices rarely operates in isolation. It needs to communicate with others to implement most business use cases. We used to run inter-service communications synchronously. Each service would invoke the API of another service over RPC-style protocols like REST, GraphQL, and gRPC. But when downstream services don’t behave as expected, this approach comes up short.
Since we’re talking FinTech, let’s consider how this would look in a stock trading example.
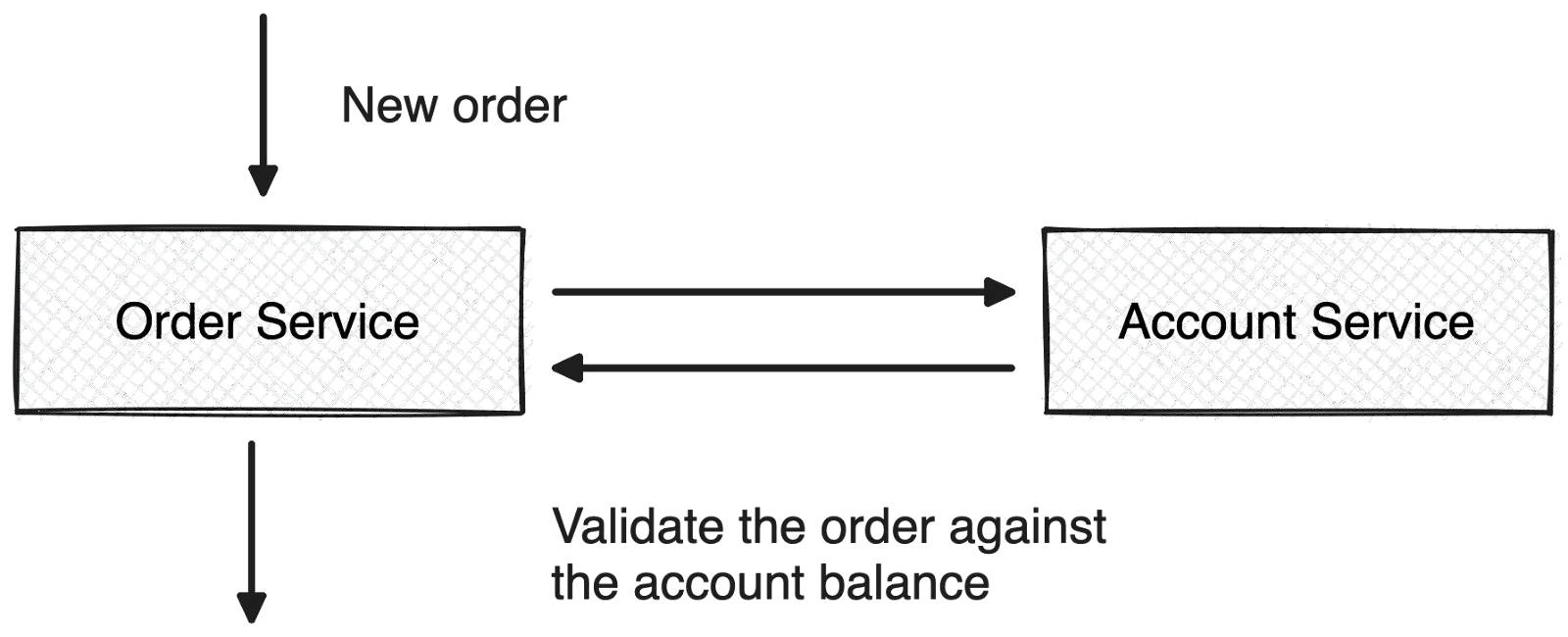
In this example, a client wants to place an order for a stock. The Order Service queries the Account Service to verify there’s enough money in the account to place the order for the stock. If the Account Service isn’t available, the Order Service has to deal with retrying, backoff strategies, and request timeouts. These additional responsibilities make it complex and less scalable to execute orders in the system. So, we want to free the Order Service from these responsibilities with an event broker. Here’s an illustration of the asynchronous and event-driven interaction.

In the asynchronous architecture, both services communicate by raising asynchronous events. This provides reliable and scalable event exchanges between them. The events are handled by a message broker, an integration middleware, or an event streaming platform. Let’s refer to this middleman as the event broker.
Now, when a client orders the purchase of a stock, the Order Service publishes the OrderReceived event to the event broker. The Account Service is subscribed to this event from the event broker and responds by publishing either an OrderValidated or OrderRejected event. The Order Service is subscribed to these events and either proceeds with the order or rejects it.
This interaction style leads up to an “event-driven microservices” architecture, where event brokers lift the burden of events by receiving and holding them until consumers can receive them. As we expand the architecture to make a complete solution, these microservices can act as both event consumers and event producers triggering other microservices.
However, while event-driven microservices are truly helpful for FinTech use cases, they aren’t great for keeping a historic record of your events. Keep this in mind when picking your event broker.
You might already be familiar with the concept of blockchain technology. Event sourcing has some of the same benefits to developers—but without the complexity.
Operational systems in the FinTech domain can benefit significantly from event sourcing because it works like a natural audit log for all events in the system. You also get rich contextual information like the doer, action, time, and more.
When microservices use events to communicate state changes, the event broker becomes the single source of truth for all events. If you choose an event broker with lifetime retaining of events, you secure a complete history of your system. You can always go back to a particular point in time, replay events from there, and derive the system’s current state.
Consider the following example where a microservice records each account transaction as state change events.

In this example, you could replay each transaction from the beginning to derive the current account balance. Though we might personally forget how $50 disappeared from our account, the DEPOSIT and WITHDRAWAL events clearly show what happened to bring our final balance to $60.
Another benefit of event sourcing is you can use event history to onboard a new system, allowing it to catch up to the latest status by replaying events from the beginning. When we need to troubleshoot a production system, we can take it offline and replay the event log to find the root cause of our problems.
One drawback of event sourcing is that we always have to replay events from the beginning to understand the current state of our systems. It takes time, is not scalable as more events add up, and event brokers aren’t designed to perform these operations. This is why event-based architecture benefits from Command Query Responsibility Segregation (CQRS).
Not only is it a good idea to run your FinTech operational system with independent microservices. It’s also a best practice to separate your write path (Commands) from your read path (Queries). CQRS is an architectural pattern that lets you do precisely that.
Microservices can route state-changing write operations to the event broker to be persisted as events. Other microservices can subscribe to them to update their local, read-optimized materialized views that answer incoming queries.
With this segregation of reads and writes, each service can use read-optimized data stores like NoSQL and full-text search engines for queries. At the same time, they can use the event broker to persist state change events. Using our previous transactions service example, we can add a materialized view at the Order Service to update with a subscription to DEPOSIT and WITHDRAWAL events from the event broker.
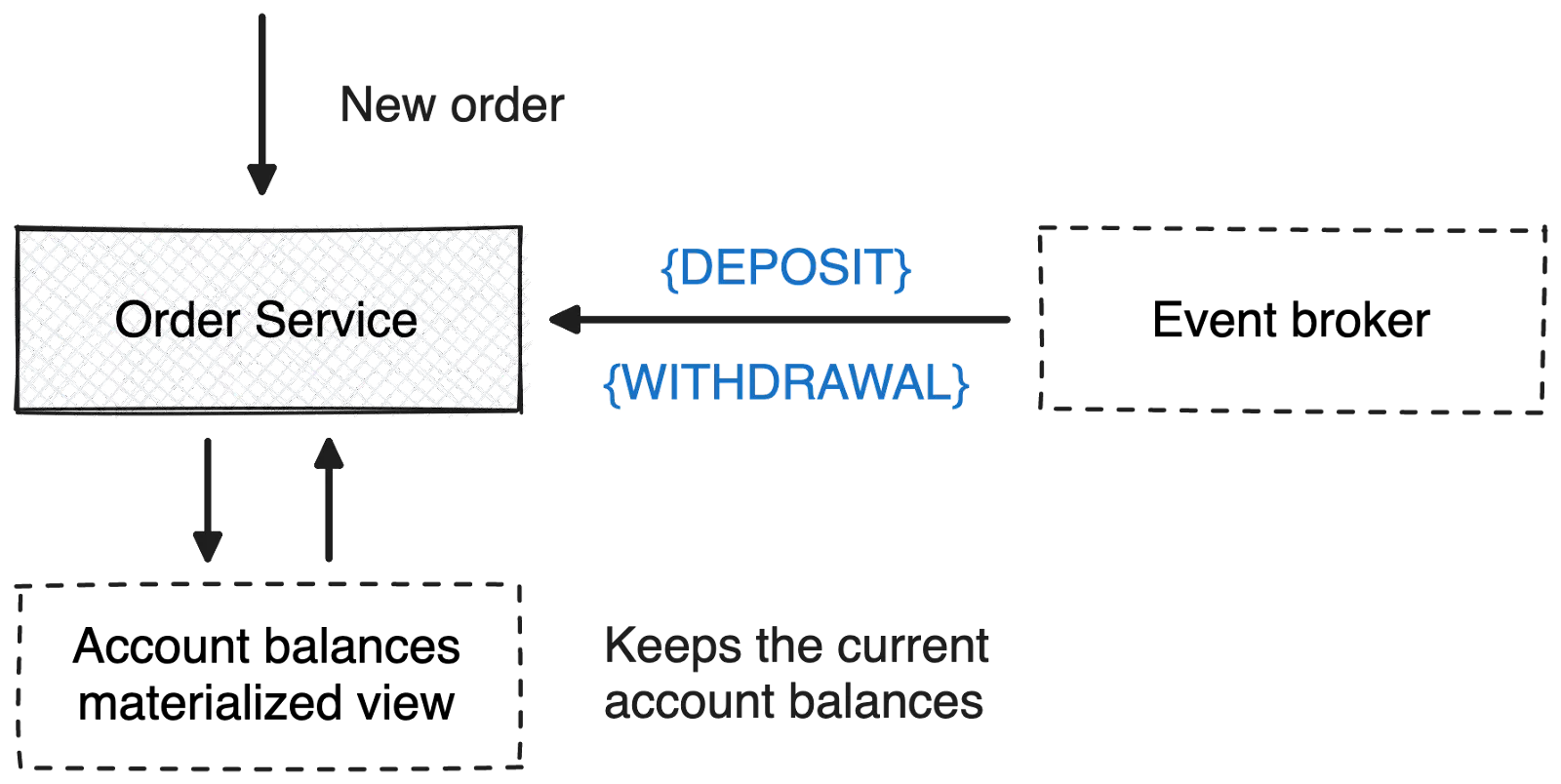
The materialized view keeps the current balances updated for all accounts, so the Order Service can access them efficiently. Now, the CQRS pattern gives you faster responses to queries and lets you evolve the read-side data store independently of the write-side. This is a superb benefit for systems with more complicated read models than write models.
FinTech operational systems need to be highly scalable without tons of complexity. This is why you’ll want to package and deploy event-driven microservices as containers or serverless functions. Their event-driven execution style lets you execute on demand and instantly scale from millions to zero. So it’s an ideal deployment candidate for Kubernetes, Knative, and other serverless platforms including AWS Lambda and Google Cloud Functions.
Transactional systems benefit from reduced operational complexity by deploying managed infrastructure provisioned on demand. With infrastructure provisioning and monitoring, management, scaling, and security handed over to a managed service, developers can focus on building applications instead of spending time playing whack-a-mole with issues in their infrastructure.
Furthermore, containerized and serverless workloads can be readily automated with expressive continuous integration/continuous deployment (CI/CD) pipelines. New features can then be added to the architecture frequently and released with confidence—making application delivery painless.
With these five guidelines, you now understand the advantages of breaking a FinTech operational system up into microservices with one event broker centerpiece. In short, when you build your system on asynchronous and event-driven microservices, you reduce complexity while adding speed, scalability, accuracy, and reliability.
Redpanda is an ideal candidate for the event broker in this modern architectural approach. Among many proven benefits, Redpanda is:
In our next blog, we’ll get even more granular by covering a practical FinTech use case with Redpanda. In the meantime, you can download the full report on building operational systems with Redpanda to get ahead of the curve. For support or advice on using Redpanda to simplify your own FinTech system’s architecture, join the Redpanda Community on Slack and chat directly with our team.
While you wait for the third post in this series, check out these blogs featuring Redpanda in popular financial scenarios:
You can't scale what you can't trust. A governance layer fixes that.

Your lakehouse mirrors the database, instantly.

What is it, why enterprises need it, and how to evaluate one
Subscribe to our VIP (very important panda) mailing list to pounce on the latest blogs, surprise announcements, and community events!
Opt out anytime.