




Bridge Queries in Redpanda SQL
Have your real-time cake and eat your analytics too
The simplest implementation with no external dependencies, nothing extra to manage, and no code to write









In Pub/Sub messaging systems, last value caching (LVC) is a common technique that allows new subscribers to quickly catch up to the latest state of the world.
Imagine a stock ticker app that shows the current price for one or more symbols. When a new instance of the app starts up, it will need the current price, and it will want to get immediately notified of any subsequent changes to the price so it can update what the user sees in real time. The app doesn’t care about the entire history of price changes and would prefer to avoid reading all that data so it can start up quickly.
The Apache Kafka protocol supports this use case through the use of compacted topics. For the unfamiliar, here’s a brief overview:
In our stock ticker example, the key might be the ticker symbol (AAPL, GOOG, GME, etc.) and the value would be a data structure that contains a timestamp and the current price. Compaction helps keep the topic to a manageable size, allowing clients to read through the topic faster and more efficiently.
The trade-off is that compaction by definition results in loss of information. As the old saying goes, you can’t compact your data and consume it too. Use cases such as back-testing or market replay cannot use compacted topics as they need historical market data in full detail.
So now you need two topics for the same data set: a regular topic that holds full historical data, and a compacted topic that serves as a last value cache. In this post, we’ll walk you through the two ways you can have the same data available in two topics within the Kafka protocol:
Then, we’ll introduce Redpanda’s third way — the good way — that has no external dependencies, no additional systems to manage, and no code to write.
As an application developer, you can code your producers to write each message to both topics. Write to the historical topic, then write to the compacted topic. While this may seem obvious and easily doable, it’s a common anti-pattern, affectionately referred to as dual writes.
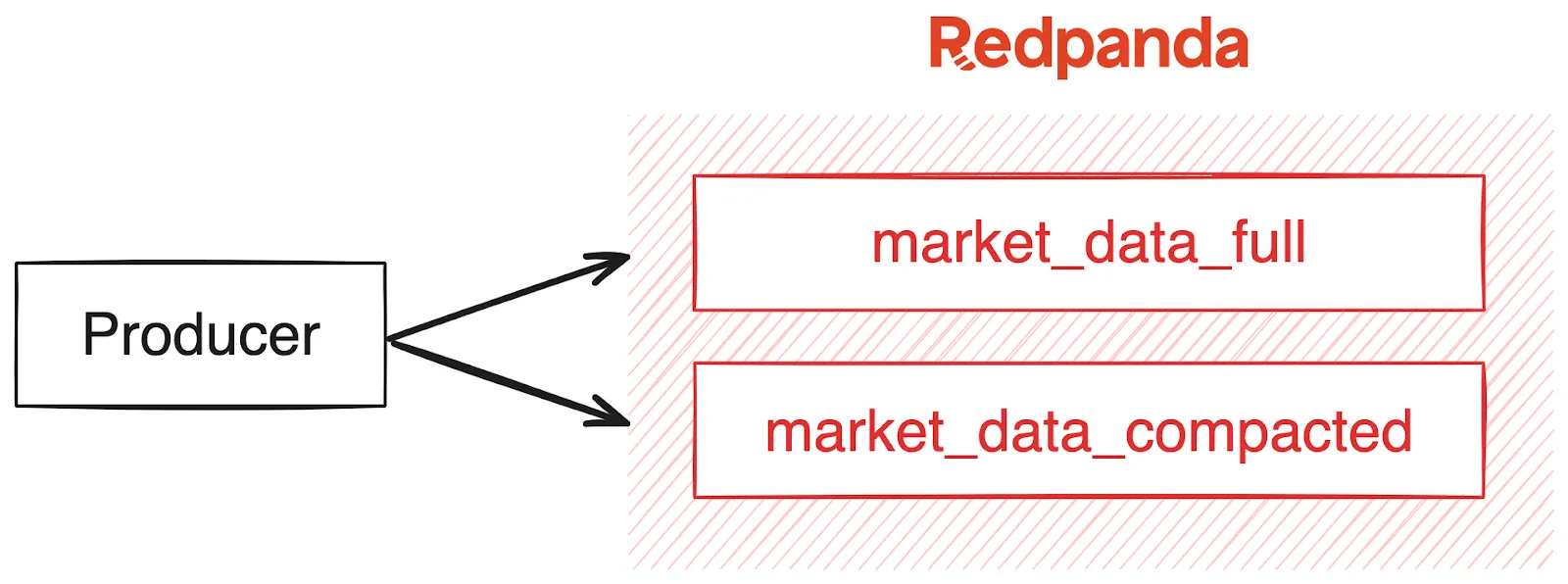
The problem with dual writes is that consistency between the two topics cannot be easily guaranteed. One of the writes could fail, and it’s up to the application to ensure that both sides eventually get the same data.
Kafka clients have a built-in capability to retry, but they don’t coordinate retries against two separate topics or partitions. You could wrap the dual writes using Kafka transactions to help ensure consistency, but it also puts a huge drag on throughput and latency.
As the old saying goes… friends don’t let friends do dual writes.
Alternatively, the not-bad but potentially ugly way is to pipe data from one topic to the other.
Producers write only to the full historical topic and then an external processor reads from that topic and publishes each message to the compacted topic. If, for some reason, the processor fails to write to the compacted topic, it can simply retry using the mechanisms built into the Kafka protocol. If the compacted topic is unavailable for an extended period, the stream processor can just stop and resume at any point later once the issue has been resolved.
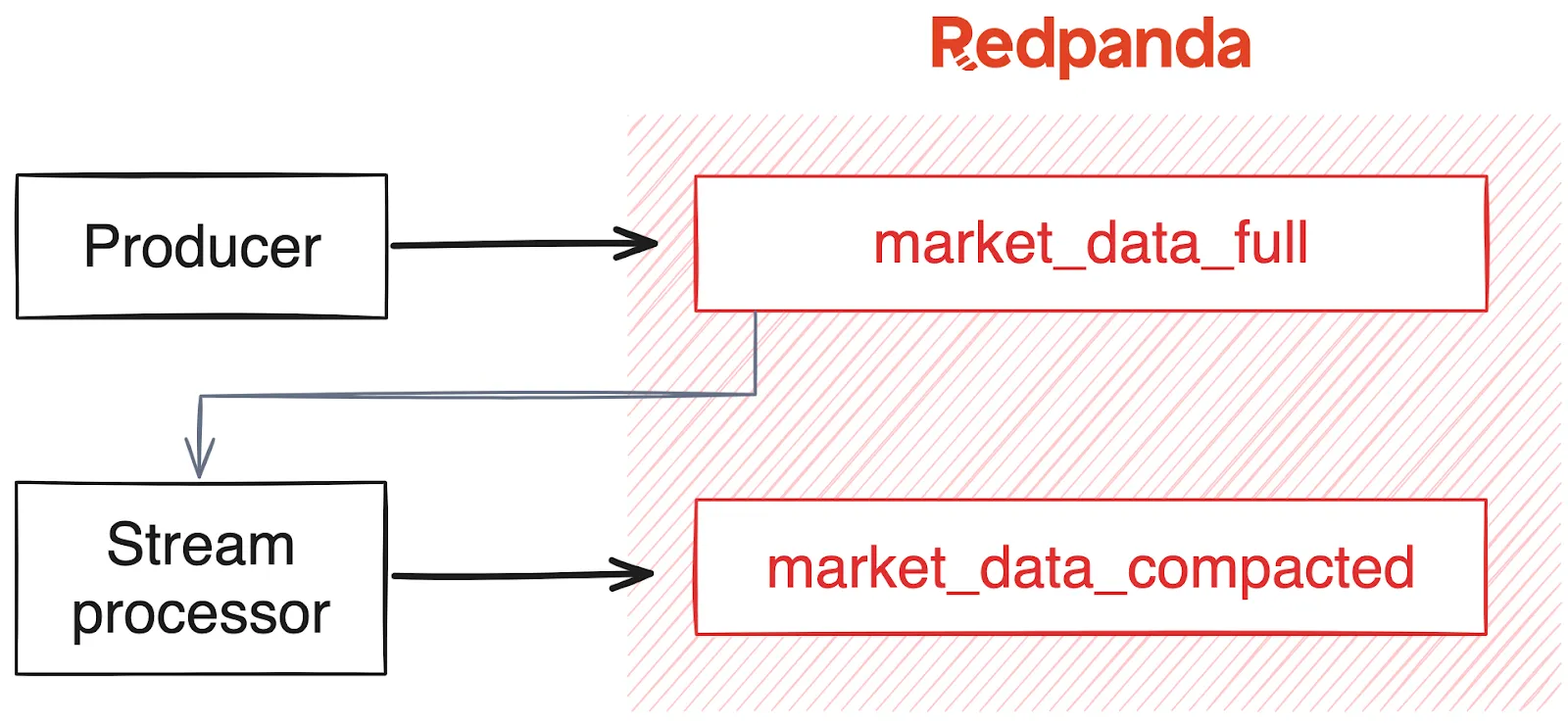
This design takes advantage of at-least-once delivery semantics. In the event of retries or extended failures, there’s a good chance that the processor will re-send some duplicate data from the full topic to the compacted topic. Since we only care about the latest value for the compacted topic, resending duplicate data does not affect data consistency.
However, this solution has some drawbacks. First, it adds network overhead when the stream processor reads from the full topic and then writes to the compacted topic. The bigger concern is you now have to build and manage the external processor.
To that end, you could write a small client that would consume from the full topic and then produce to the compacted topic. This seems simple enough and could be written in just a few dozen lines of code. However, things get complicated once you consider production requirements around fault tolerance, scalability, automation, and observability.
Alternatively, several stream processing frameworks such as Flink, Spark, and KStreams can get the job done. Most of these systems are already designed for fault tolerance and scalability and often come with tooling for management and observability. They often provide a streaming SQL interface which helps developer productivity.
That said, these are complex distributed systems that require infrastructure, upkeep, and expertise. If you have broader streaming needs, the additional overhead for using these systems make them worthwhile. But for our specific use case, introducing a complex distributed system when all we need is to reliably copy messages from one topic to another seems like overkill.
It turns out that there’s a fault-tolerant, scalable, consistent, efficient, and simple way to implement this all in Redpanda. It requires no dependencies on external processes, no additional systems to manage, and no code to write.
Redpanda Data Transforms is a feature powered by Wasm (WebAssembly) that’s built into the Redpanda broker and enables user-defined single message transforms. Essentially, it’s a streaming map operation. Developers define a transform function by writing code against a predefined API. The code is written in Go or Rust–with support for other languages forthcoming–then compiled to Wasm and executed on the broker.
Redpanda brokers run a loop for each partition leader that reads from the partition, applies the Wasm transformation, and then optionally writes zero or more messages to another topic. The loop is essentially a consumer-producer that has its own offset tracking facility. This gives Redpanda transforms at-least-once semantics.
The idea is to use Redpanda Data Transforms without doing any actual data transforms. This gets us a consistent copy of all messages from the full topic to the compacted topic. Note that this is asynchronous and there’s potential for duplicate messages on the target topic due to retries. But given how compaction works, this is acceptable and will produce correct results.
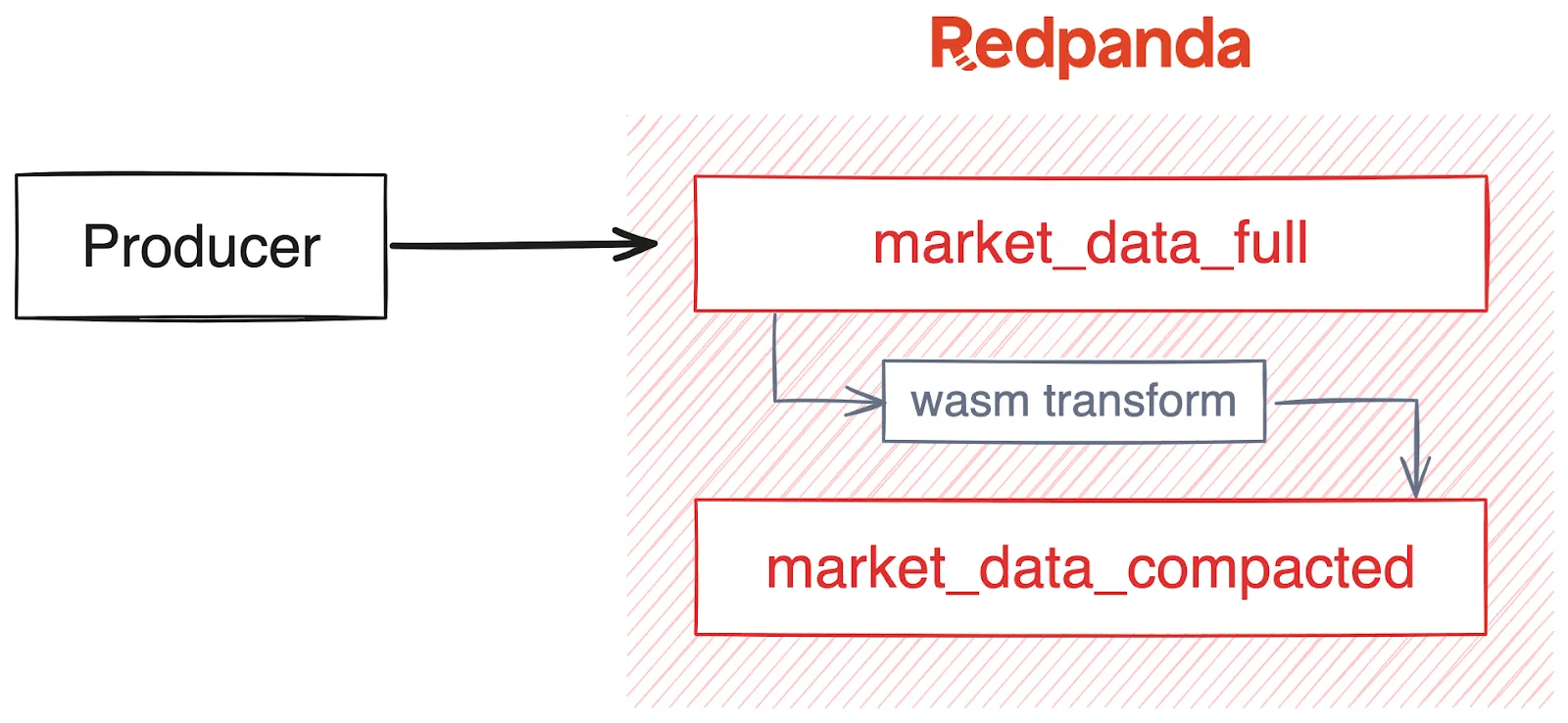
As promised, this solution is simple and requires no coding. Let’s go through the steps.
For this exercise, we’ll use a containerized instance of Redpanda. You’ll need the following prerequisites on your local environment.
rpk container start
By default, Redpanda Data Transforms are disabled. We want to enable it via configuration, which requires a Redpanda restart to take effect.
rpk cluster config set data_transforms_enabled=true
rpk container stop
rpk container startCreate your two topics, one regular and the other compacted. In Redpanda, compaction is applied only to closed segments, so we also want to set segment.ms to a low value of 5 seconds so we can observe compaction.
Note: this is for demonstration purposes only. In a production setting, you normally would not set segment.ms this low.rpk topic create market_data_full
rpk topic create market_data_compacted -c cleanup.policy=compact -c segment.ms=5000Redpanda also has a global configuration clamp that enforces a minimum value on segment.ms. The default is 10 minutes, so we need to set it lower for our 5-second segment.ms setting to take effect. Again, in a production setting, you wouldn’t set the value this low.
rpk cluster config set log_segment_ms_min 5000
Using rpk, Redpanda Data Transforms provides a template project to get you started quickly. Let’s create a directory and initialize a new project. We’ll name our project lvc and use Go as our language.
mkdir lvc
cd lvc
rpk transform init --language=tinygo --name lvc --install-deps trueYou should now see the following files in your current directory:
.
├── README.md
├── go.mod
├── go.sum
├── transform.go
└── transform.yamlThe transformation code lives in the transform.go file. Typically, you’d modify this file to author your own transforms. By default, the template uses an identity transform. This is exactly what we want for our use case, so we don’t need to change a single line of code.
package main
import (
"github.com/redpanda-data/redpanda/src/transform-sdk/go/transform"
)
func main() {
// Register your transform function.
// This is a good place to perform other setup too.
transform.OnRecordWritten(doTransform)
}
// doTransform is where you read the record that was written, and then you can
// output new records that will be written to the destination topic
func doTransform(e transform.WriteEvent, w transform.RecordWriter) error {
return w.Write(e.Record())
}This compiles your Go code into a Wasm binary. After running this command, you’ll notice a .wasm file in the current directory.
rpk transform build
This registers the transform with the Redpanda cluster. You’ll need to provide the input and output topics.
rpk transform deploy --input-topic=market_data_full --output-topic=market_data_compacted
cat << EOF | rpk topic produce -f "%k,%v\n" market_data_full
AAPL,100
GOOG,220
AAPL,103
AAPL,105
GOOG,210
GOOG,212
AAPL,101
EOFrpk topic -f "%k: %v\n" consume -o :end market_data_full
You should see all the events that were published by the previous command.
AAPL: 100
GOOG: 220
AAPL: 103
AAPL: 105
GOOG: 210
GOOG: 212
AAPL: 101rpk topic -f "%k: %v\n" consume -o :end market_data_compacted
You should only see the latest values by key.
GOOG: 212
AAPL: 101There you have it! A no-code last value cache solution demonstrated in 10 simple steps.
If this blog post were a Western, dual writes would be the cowboy coder’s solution. It is bad. It forces you to account for data consistency on your own — imposing a huge performance penalty.
The pipeline pattern is considered best practice. You can think of it as a very basic CDC or streaming ETL setup where a changelog of events is replicated and materialized into a view optimized for the consumer. As basic as it may seem, it can be non-trivial and costly to implement.
Redpanda Data Transforms allow for an implementation that has all the benefits of the streaming pipeline pattern with none of the drawbacks. It addresses several key requirements for any mission-critical application that requires a last value cache and full history. Specifically, it exhibits the following ideal characteristics:
The original use case for Redpanda Data Transforms was to facilitate stateless single message transformations such as redaction, filtering, projection, and format conversion. Here, we see it used as a log replication mechanism to enable a simple streaming pipeline. Credit goes to Ali Karaki, an expert in trading systems, who initially came up with the idea of using Redpanda Data Transforms to implement a last value cache.
Redpanda Data Transforms is generally available with Redpanda 24.1 for Community and Enterprise users (with upcoming availability for Redpanda Cloud). With 24.1, Redpanda Data Transforms gains an additional feature that allows writing to multiple output topics. This gives users the option, for example, to validate messages in a topic and put invalid messages in a dead letter queue.
As with last value caching, we look forward to the Redpanda Community coming up with new and unexpected use cases. If you have questions or want to share your ideas with us, introduce yourself in the Redpanda Community on Slack.
Subscribe to our VIP (very important panda) mailing list to pounce on the latest blogs, surprise announcements, and community events!
Opt out anytime.

