

Event streaming platform—an introduction











Event streaming platform
In an era of microservice-based architecture and complex SaaS applications, many companies rely on a host of interconnected software to run effectively. Data that was previously composed of orders, shopping carts, and checkouts is being enriched by page views, clicks, reactions, and comments. The average user now expects highly interactive applications rather than static web pages, making it increasingly vital for companies to handle real-time data.
Event streaming became a hot topic in the early 2010s after LinkedIn open-sourced Apache Kafka®. However, having the leading event streaming platform so heavily intertwined with the JVM ecosystem brought a fair amount of overhead into the field and made it difficult for new developers to get up and running.
Since 2019, Redpanda has offered a Kafka-compatible solution as a single binary with no dependencies on Java or other external libraries and services.
This article introduces the main components of event streaming platforms, how they work together, and how Redpanda implements event-driven architecture.
Summary of key event streaming platform concepts
What is an event streaming platform?
Before diving into the complexities of event streaming platforms, it is worth brushing up on the fundamentals of event streaming in general.
Consider a social media application. When a user reacts to a post, that information must be relayed to multiple destinations in real time. These could be a news feed or a machine-learning model for curating suggested posts. Both use cases require a constant input flow of user interactions and data updates.
While this could be handled with high-frequency batch jobs, it is much more desirable to feed the model with a continuous stream of user interactions and update a user’s newsfeed with suggested posts in real time. Every action, the time it occurs, and its associated metadata is called an event. The continuous flow of these events and their associated timestamps is called an event stream. Everything that makes it possible to create, store, and read an event stream is called an event streaming platform.
[CTA_MODULE]
How do event streaming platforms work?
Event streaming platforms follow the principles of event-driven architecture. It allows developers to build systems that react to one event in multiple ways or even replay past events in sequence.
Let's look at how event streaming platforms work by taking Redpanda as an example.
- Producers (or data sources) emit events as they occur.
- A cluster of software brokers in Redpanda acknowledges and stores the events in order, organized by topics.
- A topic could be anything from “user newsfeed interactions” to “shopping cart items.”
- The code that reads the event and processes or reacts to it is called a consumer.
- Once an event is inside a cluster, any consumer can subscribe to its specific topic and asynchronously consume it.
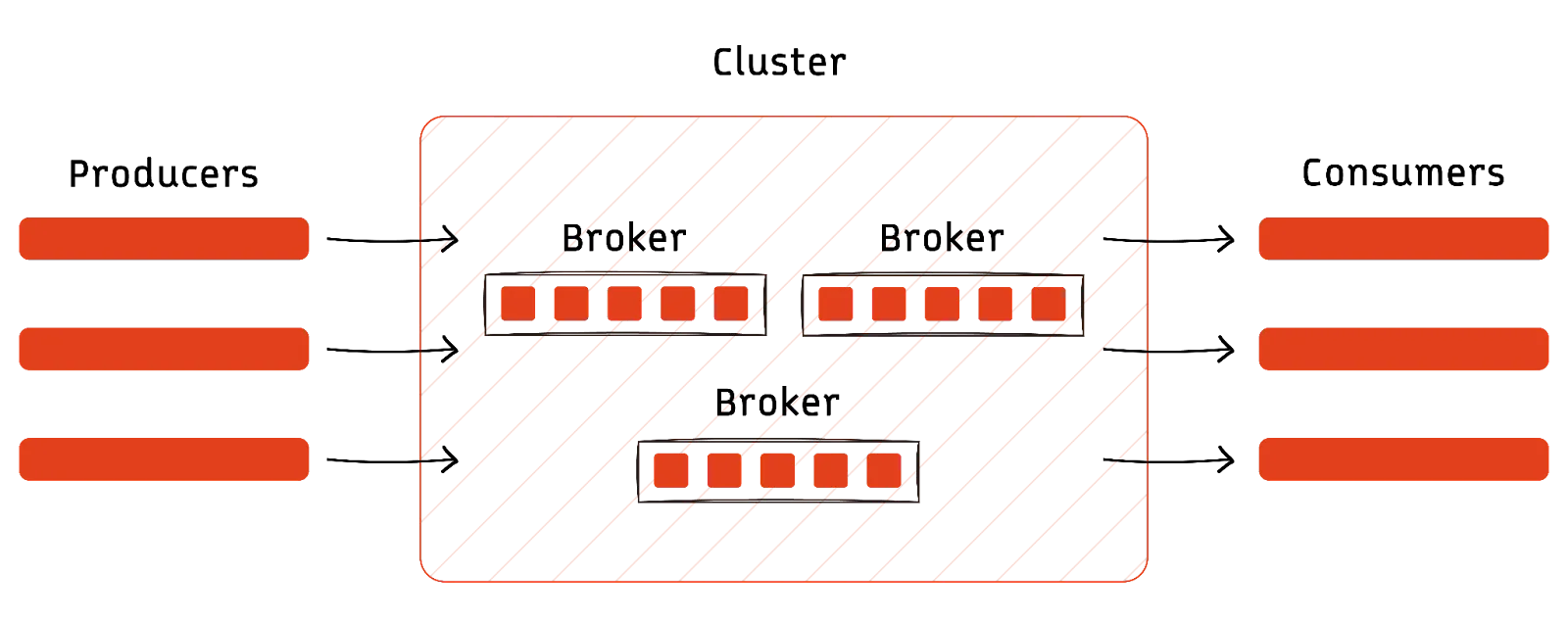
Since Redpanda acts as an intermediary, producers do not have to wait for consumers to acknowledge receipt of each event. The best way to think about this would be to imagine Redpanda as a buffer between data producers and consumers. Events are stored as they arrive and can be replayed or consumed right away by any system that uses the Kafka API. Unlike traditional message-driven architecture, multiple services can easily consume a single event and perform real-time and historical data transformations.
Scalability and fault tolerance in event streaming platforms
While enterprise messaging solutions like RabbitMQ or Google Pub/Sub are useful for facilitating communication between decoupled services, they fall short when data processing is involved. They don't natively support complex data transformations, aggregations, or analytics.
Also, they are inherently stateless, while data processing often involves stateful computations, where the outcome depends on both the current and previous data. Implementing such logic within the confines of a messaging system can be challenging. Moreover, message-driven architecture is harder to scale as your data needs grow in complexity and volume.
In contrast, event streaming platforms are designed to scale and process large amounts of data. They use partitioning and distributed processing to perform effectively with low latency regardless of the data volume. Built-in fault tolerance mechanisms, such as replication, ensure accuracy at scale.
For example, in Redpanda, each node in the cluster provides identical data to consumers at a reasonable latency, even if one or more nodes fail. When events are written to a topic, Redpanda replicates data in the node’s log files to prevent data loss should anything unexpected happen.
One of the key components for reliability and consistency at scale in a Redpanda cluster is the Raft consensus algorithm. It ensures accurate and reliable data replication between cluster nodes as follows
- Topics form a Raft group consisting of one leader and zero or more followers specified by the particular topic’s replication factor.
- Data from a topic is written to the elected leader node and replicated in each follower node.
- The amount of failures a Raft group can handle is determined by two times the amount of nodes plus one. For instance, a cluster with five nodes can remain operational even if two nodes fail. Likewise, three nodes can fail in a cluster of seven, and the cluster will still be able to recover.
Without diving into the complexities of the Raft algorithm and how leader nodes are elected, we can say that it ensures fault tolerance and data consistency throughout the cluster.
[CTA_MODULE]
Stream processing with event streaming platforms
A key advantage of event-driven architecture is that it facilitates efficient and low-latency data processing without needing a central database. In the use case we discussed earlier, users' post reactions are continuously fed into a service that looks for patterns and returns suggested content. This means we would have to look at a stream of reaction events as a consistent pattern rather than a single action that triggers a result. This is where stream processing comes into play.
Stream processing is the processing of a data stream as it is received rather than in batches. It is extremely useful in situations like fraud detection or suggestion algorithms where you want to react to events immediately.
Since each component of your application can handle events at its own rate, a single stream of events can be processed at multiple destinations. Redpanda’s Kafka API compatibility means it works seamlessly with third party stream processing frameworks like Apache Flink, Kafka Streams, Faust, or ksqlDB.
Building and debugging stream processing pipelines can be a challenging task. The newly released Data Transforms feature in Redpanda is a great way to experiment with simple transformations within the broker itself. Common data tasks like scrubbing, and filtering can be carried out on each event and written to an output topic without the overhead of a dedicated stream processing engine. This feature is currently in beta and provides a great way to transform your data in development without relying on other services.
Redpanda event streaming platform—overview for developers
Let’s take a brief overview of how to get started with Redpanda for developers.
Administration
The Redpanda event streaming platform includes two different UIs that simplify interactions with your clusters. Redpanda Keeper, rpk, a standalone command-line tool, can be used for node configuration, topic creation, and tuning.
Additionally, the Redpanda Console simplifies system administration with a secure, developer-friendly web UI that includes built-in visual partition management and data observability. Not having to worry about picking the correct third-party UI reduces the time and effort developers have to spend on deployment, administration, and monitoring.
Deployment
Traditional event streaming platforms like Kafka require several external services to work effectively. A common roadblock in deploying Kafka is the leap in difficulty between setting up a quick proof of concept and setting up a production-grade cluster.
The Redpanda platform demystifies the deployment process with a single binary that includes a built-in schema registry, HTTP proxy, and message broker. You can also use the binary to run one or more nodes, which can be added or removed as needed as your workload scales. It can run on a set of Linux machines or Kubernetes with minimal configuration.
Installation
All you need for a standard self-hosted Linux deployment is to install the Redpanda binary from a package manager and run a setup script, as seen in the Ubuntu / Debian code snippet below. This process should be done on each worker machine or “node” that will be part of your cluster.
curl -1sLf 'https://dl.redpanda.com/nzc4ZYQK3WRGd9sy/redpanda/cfg/setup/bash.deb.sh' | \
sudo -E bash && sudo apt install redpanda -yOnce installed, Redpanda will be in development mode. Simply running the following command on each node will switch to production mode and enable hardware optimization:
sudo rpk redpanda mode productionNext, use Redpanda Keeper to optimize each node to ensure the best performance. This is called “tuning”.
sudo rpk redpanda mode productionNow that that’s out of the way, you can run your cluster with the following set of commands.
sudo rpk redpanda config bootstrap --self <ip-address-of-your-node> --ips <seed-server-ips> && \
sudo rpk redpanda config set redpanda.empty_seed_starts_cluster false && \
sudo systemctl start redpanda-tuner redpandaThe <ip-address-of-your-node> placeholder can be replaced with the particular node’s private IP address, while the <seed-server-ips> can be replaced with the IPs of the other nodes in the cluster. This allows the nodes to communicate between themselves and work together.
Naturally, these commands can be automated with Ansible in conjunction with Terraform managing infrastructure. The Redpanda docs have a great guide on how to do just that.
[CTA_MODULE]
Conclusion
With an integrated UI, easy deployment, and lower operating costs than Kafka, the Redpanda platform is an excellent option for engineering teams working with real-time data. Furthermore, Redpanda’s compatibility with the Kafka API allows engineers to migrate existing projects from Kafka with minimal effort.
To get started with Redpanda and see how simple it is for yourself, grab a free trial! Spin up in seconds and start streaming data within minutes.
[CTA_MODULE]