

Kafka Streams vs. Flink—How to choose











Kafka Streams vs. Flink
In the streaming data ecosystem, Apache Kafka® is a distributed data store optimized for ingesting real-time data. Kafka Streams is a client library provided by Kafka for additional stream processing and transformation functions on top of Kafka.
On the other hand, Apache Flink® is a data processing framework that can act on both data streams and batches. It has advanced processing capabilities but requires a data ingestion tool like Kafka or Redpanda for complete efficiency.
In this article, we compare Kafka Streams and Flink in detail. We discuss technical nuances, performance characteristics, and practical applications—providing insights into their strengths, limitations, and best use cases.
Summary of key concepts: Kafka streams vs. Flink
Overview of Kafka Streams
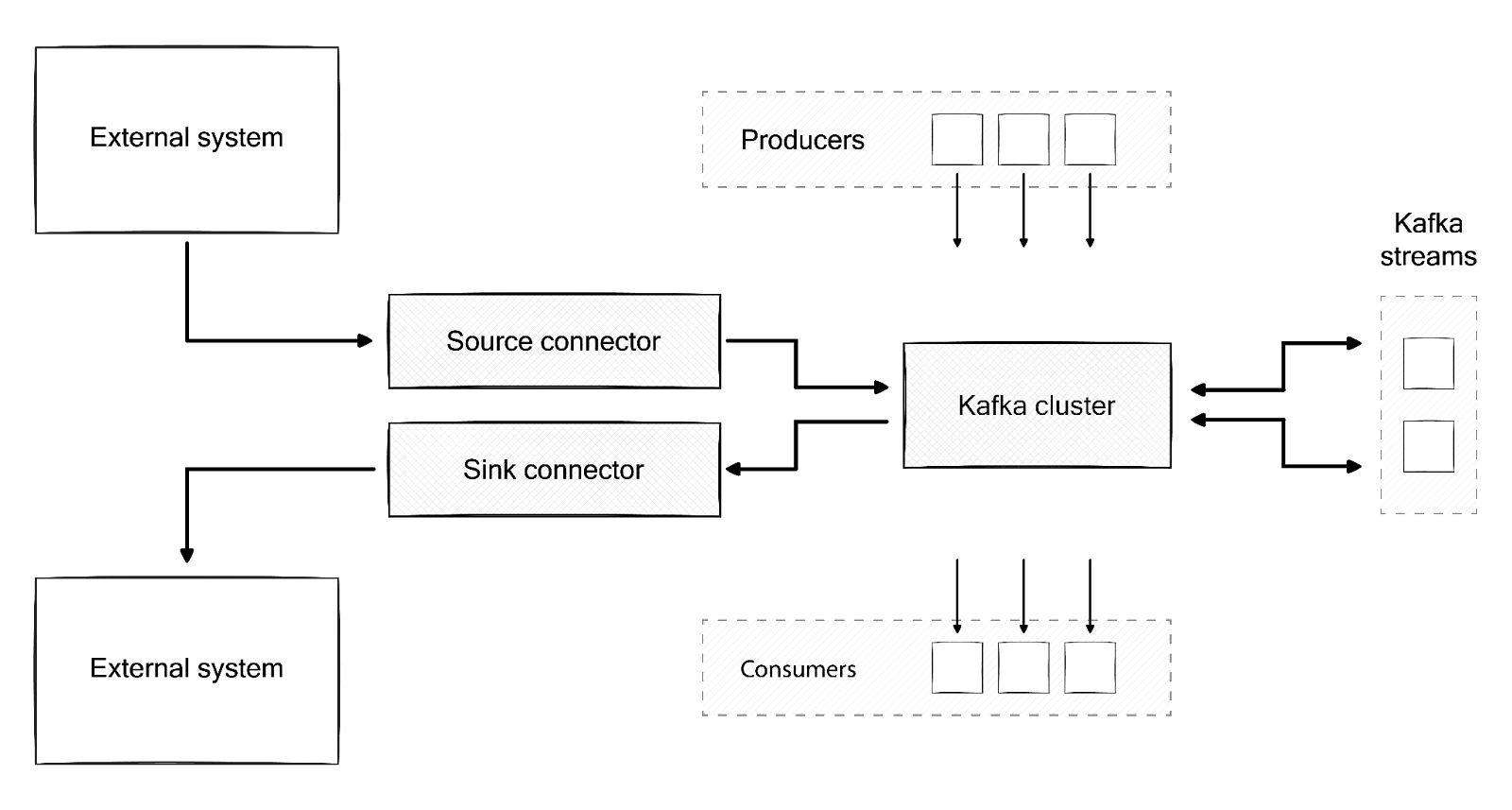
Kafka Streams is a client library for building applications and microservices that transform or react to stream data. The input and output data are stored in Kafka topics. It combines the simplicity of writing and deploying standard Java and Scala applications on the client side with the benefits of Kafka's server-side cluster technology for fault-tolerant, stateful stream processing.
Key features
- Stateful processing allows applications to maintain their state, vital for many real-world use cases like aggregations or windowed computations.
- Queriable state allows applications to query the state stored in Kafka directly, making data more accessible.
- Exactly-once semantics ensure that each record is processed exactly once, thereby preventing data duplication and ensuring data integrity, even in a failure.
- Join operations provide the capability to join streams and tables in various ways, enabling complex stream processing use cases.
- Custom partitioning offers control over how data is partitioned and processed, allowing for more optimized and efficient stream processing.
[CTA_MODULE]
Strengths and limitations
Kafka Streams is inherently designed to work with Kafka, leading to straightforward setups and configurations for those already using Kafka. It offers a simple path for building streaming applications without needing a separate cluster or infrastructure besides Kafka. Leveraging Kafka’s robustness, it naturally scales with Kafka clusters and maintains high reliability.
Kafka Streams also don't need a "cluster" to be deployed, unlike Flink. They can be deployed as microservices, simplifying the deployment for less data-intensive workloads, like event-driven microservices.
At the same time, its tight coupling with Kafka can be a limitation for systems that don't extensively use Kafka. Compared to more comprehensive streaming solutions like Flink, Kafka Streams may lack some advanced features, particularly for complex event processing and handling large-scale data streams. It also offers limited support for non-JVM programming languages.
Overview of Flink
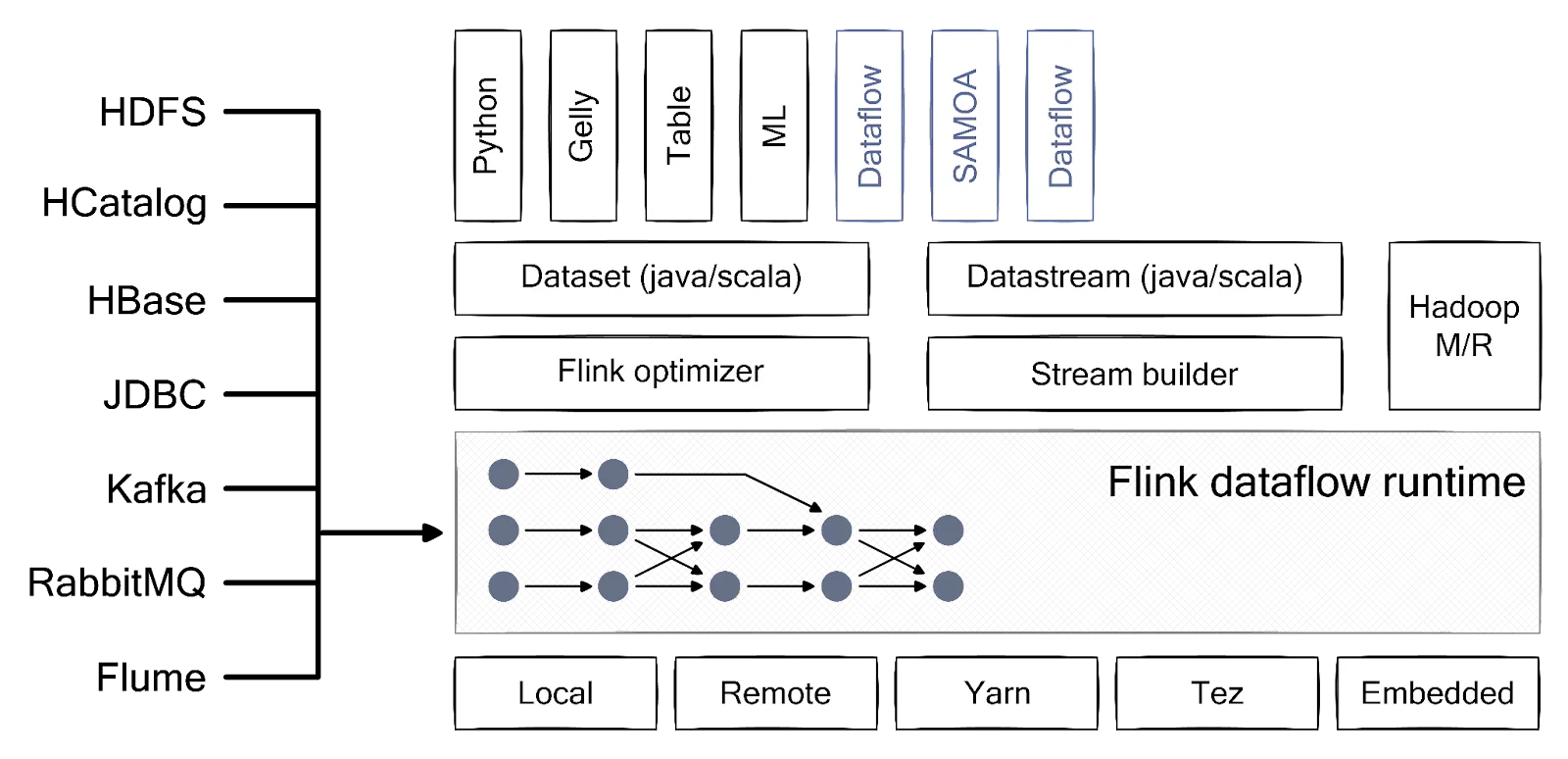
Flink is a distributed stream processing framework known for easily handling complex and high-volume data processing tasks. It is designed to run in all common cluster environments and perform computations at in-memory speed.
Flink's core is a streaming dataflow engine that provides data distribution, communication, and fault tolerance for distributed computations over multiple streams. It supports batch and stream processing, making it a versatile choice for various real-time analytics applications.
Key features
- Complex event processing: Flink excels in CEP, allowing for pattern detection and sequence identification in data streams, which is useful for scenarios like fraud detection.
- Machine learning library: Flink has a machine learning library, making it possible to run ML algorithms on data streams directly within Flink.
- Temporal table joins: Flink supports joining a dynamic table (a stream) with a static table, enabling temporal queries and simplifying stream processing logic.
- Dynamic scaling: Flink can scale applications up or down based on the workload, enhancing resource management and efficiency.
- Savepoints and state migration allow for creating savepoints, facilitating updates and migrations without data loss, and ensuring business continuity.
Strengths and limitations
Flink is built to scale out to thousands of nodes, allowing it to efficiently handle large-scale, stateful computations. It supports many use cases, from simple data transformations to complex event-driven applications and analytics. It also integrates with many storage systems and has rich connectors for various data sources and sinks.
However, managing and operating a Flink cluster can be complex, requiring a good understanding of the system’s internals. Flink can be overkill for smaller workloads, as it's designed for heavy-duty, continuous processing tasks.
[CTA_MODULE]
Programming model: Kafka Streams vs. Flink
Kafka Streams is tightly integrated with the Java ecosystem, and while it does offer a straightforward approach for those familiar with Java, it limits developers to this language.
Flink is designed with flexibility in mind, supporting multiple programming languages such as Java, Scala, and Python (through PyFlink). Additionally, Flink provides a variety of API abstractions, including the DataStream API for stream processing, DataSet API for batch processing, and the Table API and SQL for declarative programming. This range of options caters to a broader spectrum of developers and use cases, allowing for a choice that best fits the problem.
Kafka Streams DSL vs. Flink DataStream API
Kafka Streams offers a Domain-Specific Language (DSL) that simplifies building Java stream-processing applications. The DSL provides high-level abstractions like KStream and KTable, which represent data streams and table change logs, respectively.
// Code Snippet Example - Kafka Streams DSL
StreamsBuilder builder = new StreamsBuilder();
KStream<String, String> textLines = builder.stream("input-topic");
KTable<String, Long> wordCounts = textLines
.flatMapValues(textLine -> Arrays.asList(textLine.toLowerCase().split("\\W+")))
.groupBy((key, word) -> word)
.count();
wordCounts.toStream().to("output-topic", Produced.with(Serdes.String(), Serdes.Long()));
KafkaStreams streams = new KafkaStreams(builder.build(), properties);
streams.start();In the above example, the DSL is used to implement a simple word count application, demonstrating the straightforward and declarative style of Kafka Streams.
While Kafka Streams' DSL is tailored for Kafka-centric applications and offers an easy way to process data within the Kafka ecosystem, it is limited to Java and closely tied to Kafka's architecture. In comparison, Flink's DataStream API provides a more flexible programming model, supporting Java, Scala, and Python. It offers a rich set of operators for stateful computations, windowing, and complex event processing that extend beyond the Kafka ecosystem.
// Code Snippet Example - Flink DataStream API
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<String> text = env.fromElements(/* input data */);
DataStream<Tuple2<String, Integer>> counts = text
.flatMap(new Tokenizer())
.keyBy(0)
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.sum(1);
counts.print();
env.execute();This snippet shows a similar word count application in Flink, highlighting the expressive and versatile nature of the DataStream API.
Integration and ecosystem
In terms of integration and ecosystem support, Kafka Streams naturally integrates seamlessly with Kafka and benefits from the Kafka ecosystem. This makes it a convenient choice for organizations already invested in Kafka. The Kafka Connect API facilitates integration with various databases, message queues, and file formats. For instance, the JDBC Connector allows Kafka Streams to interact directly with relational databases.
// Example - Kafka Streams with Kafka Connect
StreamsBuilder builder = new StreamsBuilder();
KStream<String, String> sourceStream = builder.stream("source-topic");
sourceStream.to("destination-topic");
// ... Kafka Streams application logic ...
KafkaStreams streams = new KafkaStreams(builder.build(), properties);
streams.start();Similarly, Flink offers extensive integration capabilities with various external systems. It has a vibrant community that contributes to a wide range of connectors and integrations. This makes Flink adaptable to more diverse environments and use cases. For example:
- Flink Connectors for Kafka, AWS Kinesis, Elasticsearch, JDBC, RabbitMQ, and Apache Cassandra.
- Flink Table and SQL API: Allows easy integration with external systems for streaming and batch processing.
// Code snippet example - Flink with Kafka Connector
StreamsBuilder builder = new StreamsBuilder();
KStream<String, String> sourceStream = builder.stream("source-topic");
sourceStream.to("destination-topic");
// ... Kafka Streams application logic ...
KafkaStreams streams = new KafkaStreams(builder.build(), properties);
streams.start();Handling late-arriving events
Kafka Streams and Flink offer mechanisms to manage late-arriving data, which is crucial for ensuring accurate results in stream processing. Kafka Streams handles these events with a concept called "windowing." This feature allows events to be processed within a defined time frame or window, with a grace period for late events.
However, compared to Flink, its capabilities are somewhat limited when dealing with delayed data or out-of-order events.
// Code snippet example - Windowing in Kafka Streams
StreamsBuilder builder = new StreamsBuilder();
KStream<String, String> stream = builder.stream("input-topic");
KGroupedStream<String, String> groupedStream = stream.groupByKey();
TimeWindowedKStream<String, String> windowedStream = groupedStream
.windowedBy(TimeWindows.of(Duration.ofMinutes(5)).grace(Duration.ofMinutes(1)));
windowedStream
.aggregate(/* aggregation logic */)
.toStream()
.to("output-topic");
KafkaStreams streams = new KafkaStreams(builder.build(), properties);
streams.start();This example demonstrates a 5-minute window with a 1-minute grace period for late-arriving events. Kafka Streams can effectively manage late data within this grace period but may struggle with data arriving significantly later.
On the other hand, Flink provides more robust support for late-arriving events through its watermarking feature. It tracks the progress of event time and allows for flexible handling of out-of-order events. Flink is particularly strong in scenarios where late data is expected and accuracy over time is critical.
// Code snippet example - Watermarking in Flink
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<MyEvent> stream = env.addSource(/* source */)
.assignTimestampsAndWatermarks(WatermarkStrategy
.<MyEvent>forBoundedOutOfOrderness(Duration.ofSeconds(30))
.withTimestampAssigner((event, timestamp) -> event.getTimestamp()));
stream
.keyBy(MyEvent::getKey)
.window(TumblingEventTimeWindows.of(Time.minutes(5)))
.aggregate(/* aggregation logic */);
env.execute();In this snippet, watermarks are set with a maximum out-of-orderness of 30 seconds, indicating how late an event can be relative to the observed watermark. Flink's watermarking allows for advanced handling of late-arriving and out-of-order data, making it highly suitable for complex event time processing.
[CTA_MODULE]
Performance: Kafka Streams vs. Flink
Kafka Streams is optimized for Kafka-centric environments, offering efficient processing for moderate workloads and real-time analytics within Kafka. On the other hand, Flink is designed for high throughput and low latency, making it ideal for large-scale, complex streaming applications. Its performance shines in demanding environments where data must be processed quickly and reliably at scale.
Kafka Streams scalability is closely tied to Kafka's scalability. Flink, however, is designed to handle high throughput and can scale out to thousands of nodes, making it a more suitable option for exceptionally large-scale streaming tasks.
Kafka Streams does offer a lower learning curve, especially for those already familiar with Kafka. Its tight integration with the Kafka ecosystem translates to a more straightforward setup and operational simplicity.
However, the effort required to learn Flink is worthwhile for its flexibility and ability to handle more complex streaming needs. It offers rich features and extensive documentation for various performance requirements.
When to use Kafka Streams vs. Flink
The suitability of Kafka Streams vs. Flink often depends on the specific use case.
Choosing Kafka Streams
Kafka Streams is the optimal choice in scenarios with a heavy reliance on the Kafka ecosystem. It is suitable in environments where the primary goal is to enhance or extend the capabilities of existing Kafka applications with streamlined, real-time data processing. Use cases include real-time monitoring, anomaly detection in data streams, and simple event-driven applications.
Kafka Streams is also suitable for projects where the operational complexity needs to be minimal, and the development team is familiar with Kafka's architecture. It is also a great fit for applications that require quick, lightweight stream processing capabilities without the overhead of deploying and managing a separate processing cluster.
Choosing Flink
Flink stands out for its exceptional handling of complex, large-scale tasks. It is best suited for use cases that require event-time processing and advanced windowing capabilities.
Event-time processing refers to handling events based on the time they occurred. It is important in environments with out-of-order or delayed events that still require accurate analytics related to event timing and order, such as financial transactions or sensor data analysis.
Window operations allow computations over a sliding time window or a set number of elements. Flink's advanced windowing includes
- Tumbling windows for processing data in fixed-size, non-overlapping chunks based on time or a count of events.
- Sliding windows for overlapping windows, useful for smoothing out bursts in data streams.
- Session windows for cases where activity sessions need to be grouped, like user activity on a website.
You can perform complex analytics by combining windowing capabilities with Flink’s stateful processing.
Real-world examples
LinkedIn, the original developer of Kafka, uses Kafka Streams for real-time analytics and monitoring applications. One significant application is their metrics monitoring and anomaly detection system.
Leveraging Kafka Streams allows LinkedIn to process vast amounts of real-time data within its Kafka ecosystem. This system plays a crucial role in monitoring the health and performance of various services. It enables quick detection and response to potential issues for maintaining a reliable user experience on the platform.
Alibaba, one of the world's largest e-commerce and retail platforms, effectively uses Flink for several large-scale applications, including real-time analytics and machine learning. Their real-time analytics platform provides Alibaba with timely insights into customer behavior and sales performance and helps optimize operational efficiency. Flink's ability to handle high-throughput and low-latency processing is critical for this.
[CTA_MODULE]
Conclusion
Kafka Streams offers a straightforward approach to stream processing for Kafka-centric environments. It is well-suited for moderate-scale, real-time analytics. On the other hand, Flink excels in large-scale, complex stream processing tasks.
When choosing between Kafka Streams and Flink, consider the following guidelines:
- Assess the scale and complexity of the data streams your application will handle. Flink is more suited for large-scale, complex processing.
- Evaluate existing infrastructure. If your environment is heavily invested in Kafka, Kafka Streams offers a smoother integration and simpler operation.
- Consider development resources. Kafka Streams can be more accessible for teams already familiar with Kafka.
- Analyze functional requirements. Flink offers a broader range of advanced features in stateful processing, windowing, and complex event processing
- Look at fault-tolerance needs. Flink’s advanced checkpointing strategy might be more beneficial.
Redpanda (a drop-in Kafka replacement) for data ingestion and Flink for data processing is currently the best combination for stream processing at scale. With Redpanda in the mix, you can add more mileage to your journey regarding performance, reliability, and cost-efficiency.
Plus, since Redpanda is designed with developers in mind, you can count on a vastly more simplified experience regarding operations and maintenance. Try Redpanda Serverless to see for yourself. Spin up in seconds, no infrastructure to manage, scale as you grow.