

Flink vs. Kafka and their role in the streaming data pipeline











Flink vs. Kafka
Apache Kafka® and Apache Flink® are two data infrastructure components that are often discussed together while designing high-performance data processing pipelines.
Kafka is a distributed event streaming platform that you can use to implement high throughput, low latency real-time data processing. It traces its origin to LinkedIn and was open sourced in 2011.
Flink is a data processing platform that handles real-time and batch data processing through a unified data flow processing API. Flink became a top-level Apache project in 2014 and has been gaining popularity ever since.
This article discusses Kafka with Flink and elaborates on how these two components can work independently or complement each other in high-performance data pipelines.
Summary of key Flink vs. Kafka concepts
Understanding Flink and Kafka
Even though Kafka and Flink may appear as comparable platforms for a casual observer, they are very different regarding features and use cases. They both occupy different places in the streaming data pipeline.
In computing, a data stream is a sequence of data elements made available over time. It's like a conveyor belt of information pieces flowing from a source to a destination. This flow can happen in real-time or near-real-time, and the data elements can be anything from simple numbers to complex objects. Consider your data flowing from a data source to a target business intelligence platform.
Kafka operates at the data ingestion layer, capturing the data from various physical and digital sources for further processing. Flink operates at the next stage—the data processing layer—and performs different cleaning and transformations on the data.
Kafka was originally designed for data ingestion, but a client library called Kafka Streams was later introduced to facilitate data transformation directly within it.
On a high level, Kafka Streams and Flink are comparable as they both process data. Kafka and Flink, however, are complementary technologies. Kafka is a distributed event store or a buffer, while Flink is a stream processing framework that can act on a buffer or any data source. On that note, Kafka can be an upstream or downstream application to Kafka in architectures where both are present. When Kafka is upstream, Flink processes data present in Kafka. When Kafka acts as a downstream, Flink processes data and writes the result to Kafka to be consumed by another application.
How Kafka works
Kafka is a distributed event store and a streaming platform that enables building highly decentralized data processing applications.
The Kafka working model comprises producers, consumers, and brokers. Producers are client applications that generate data and direct them as messages to the brokers. A group of messages belonging to a logical business purpose is called a topic. Topics are divided into partitions distributed across nodes to prevent topics from growing beyond a single node's size. Kafka thus achieves decentralization through the use of partitions.

The broker provides reliable, decentralized storage for messages. Kafka consumers are applications that execute business logic on the messages stored by the broker. They listen to the events and process the messages they are interested in. Kafka uses the concept of consumer groups to scale data consumption. Consumer groups listening to a topic have access to all its partitions, and Kafka ensures a single message is never delivered to more than one consumer.
You can use custom logic to write consumers and process data or use one of the many data processing frameworks that support Kafka as the data source. Flink is an example of one such framework.
How Flink works
Flink is a distributed data processing platform that operates on data streams. Each stream can originate from data sources like message queues, file systems, and databases.
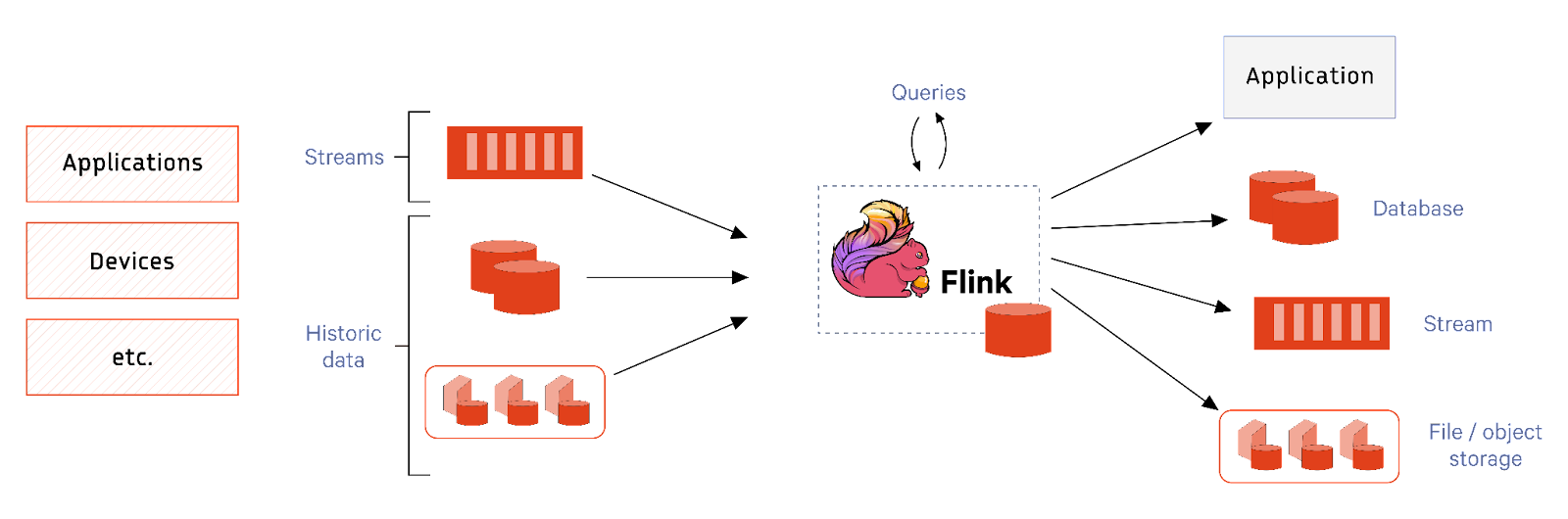
Flink is typically operated as a cluster with individual applications bundled into JAR files and deployed as jobs within the cluster. A Flink cluster consists of a Job Manager and several Task Managers. The Job Manager is responsible for submitting jobs, keeping track of them, and general resource management. Task Managers act as workers and execute the actual tasks.
A Flink job consists of workflows representing an operation sequence with transformation operators responsible for the actual business logic, where each operator can have multiple instances that act on subsets of data bringing up parallelism.
The process function is the most basic and low-level programming interface in Flink. It provides fine-grained control over the core building blocks of stream processing: events (data elements) and state management. The process function enables developers to handle each event that flows through the stream, including event time and timers for event-time actions. They can also manage state by keeping track of information across multiple events (e.g., counting events, aggregating values).
The DataStream and DataSet APIs abstract over the process functions and provide various building blocks for application programmers. The Table DSL and SQL API further abstract over the Data Stream/DataSet APIs, providing a relational database model and querying features.
[CTA_MODULE]
Flink vs. Kafka - key differences
Data streams can be categorized as either bounded or unbounded. A bounded stream has a finite start and end. It's a dataset with a fixed size, and once all the elements in the stream have been processed, the stream is considered complete.
In contrast, an unbounded stream doesn't have a defined end. It's potentially infinite and continuously generates data. The stream keeps open as long as data keeps coming.
Kafka is focused on being a distributed event store and streaming platform with unbounded stream processing ability built into it through Kafka Streams. Its primary use case is to act as an event broker and provide fault-tolerant event storage.
On the other hand, Flink is focused on being a data processing platform that can process both bounded and unbounded streams. The only comparable aspect of Kafka and Flink is their unbounded stream processing ability.
Push vs. pull for data processing
Kafka works based on a combination of push and pull operations. The producer applications gather data and push them to the broker. The consumer applications pull data from the broker and execute their logic.
Flink works based on pull mode operation. The Flink applications pull data from their sources and execute their logic. In other words, Flink does not have a buffer to store the events waiting for processing. In the case of real-time streaming use cases, Flink is always integrated with a buffer like Kafka, Kinesis, etc., for fault-tolerant event storage.
Processing model
Kafka Streams and Flink differ in their handling exactly-once semantics during unbounded stream processing. Flink handles out-of-order records through the use of watermarks. Watermarks are heuristics that Flink uses to define when to stop waiting for out-of-order records. Kafka handles it by allowing windows to be partially aggregated and updating the results when an event arrives out of order.
Use cases
Kafka’s primary use case is that of a durable event broker with some stream processing abilities. Its stream processing abilities focus more on use cases like integrating microservices and building event-driven systems.
On the other hand, Flink is well suited for analytical use cases involving high-speed complex transformations. Flink also works great in cases where one has to pull in data from various sources, including real-time streams, databases, and filesystems. In such cases, Flink is often used alongside Kafka, where Kafka acts as the event buffer and Flink is the processing solution.
[CTA_MODULE]
Streaming pipelines using both Kafka and Flink
Let’s explore defining a data processing pipeline with the help of an IoT example.
Imagine you need to build a system that processes real-time messages from an IoT device deployed in moving trucks. The events from the trucks are aggregated, and alerts are generated based on different scenarios. Consider the example where an alert is raised whenever the truck's speed goes beyond a threshold value. Such a use case can be handled using the below architecture.
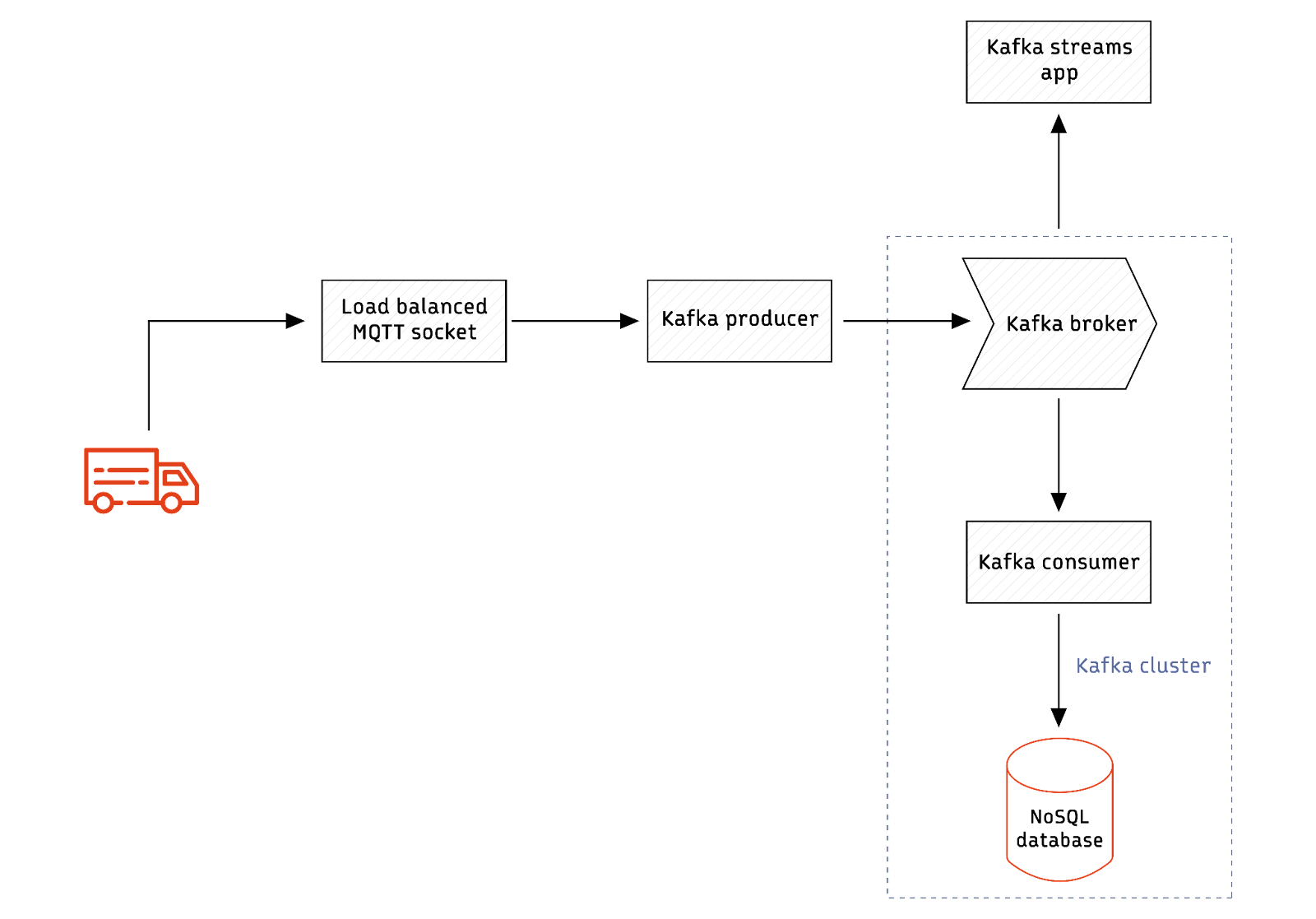
The architecture works as follows.
- The devices in trucks continuously send data to an MQTT socket.
- The socket listener pushes data to Kafka using Kafka producer APIs.
- A Kafka consumer writes data to a NoSQL database like DynamoDB.
- Another Kafka consumer application listens to real-time data, generates an alert, and calls a REST API to trigger an email.
The architecture thus uses Kafka as an event buffer and a Kafka Stream application to generate alerts based on specific scenarios.
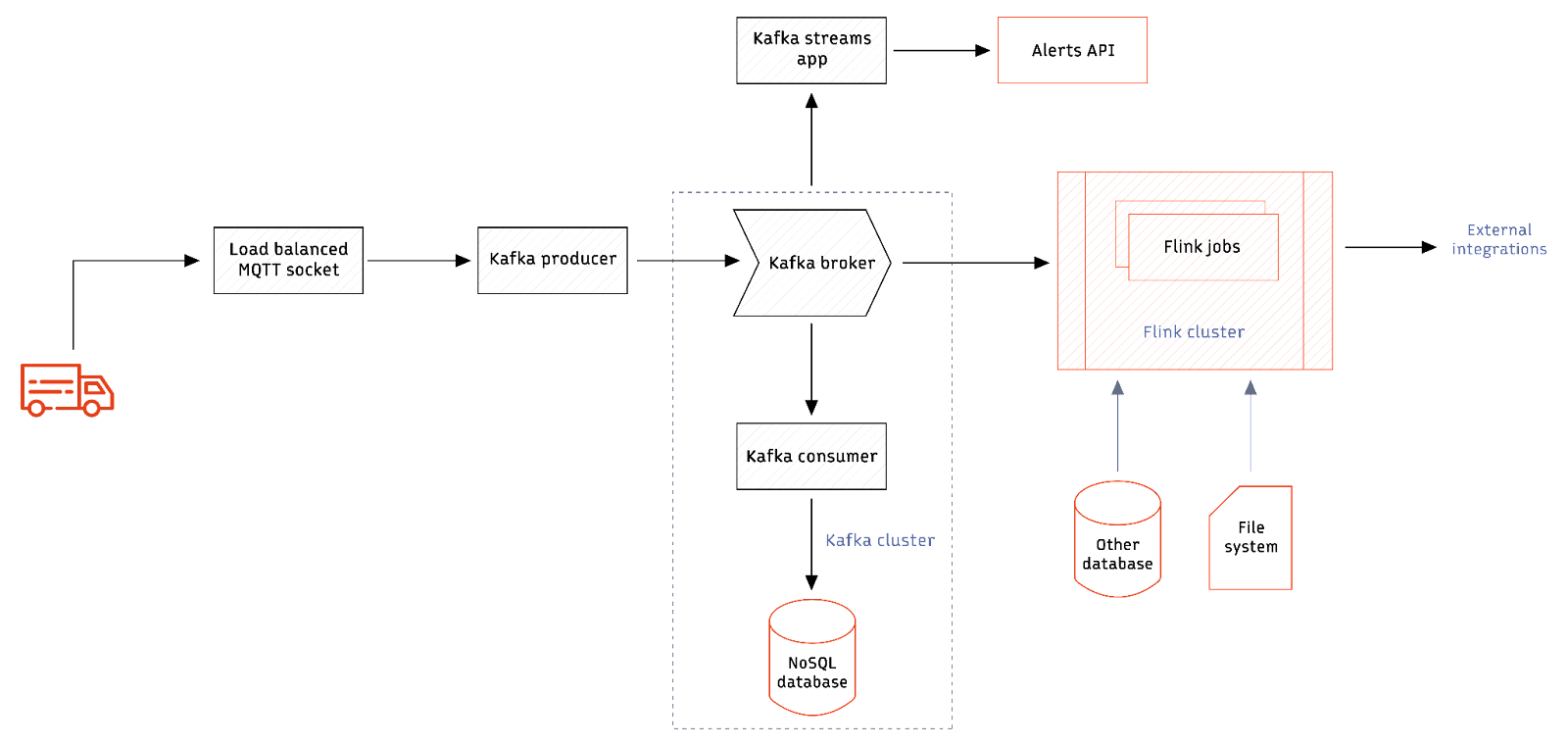
Now imagine the engineers here getting new requirements that involve more complex event analysis. For example, an alert is raised only when five or more speeds go above the threshold value within 10 minutes. This calls for more complex logic for processing events. Kafka Streams API will still be able to do it with some custom logic, but considering the complexity of the alerts is only going to go up, it makes sense to invest in a data processing platform with better windowing functions and analytical query support. This is where Flink can make a difference. But then, using Flink requires the organization to invest in a new cluster. Deciding whether to move processing to a Flink-based system depends on the requirements. Let’s say the organization wants to combine historical driver performance metrics present in a relational database or file system with real-time messages from trucks to derive deeper metrics. Flink can be a great add-on since it can pull in data from various sources and run queries on top of them. The complete architecture looks as follows.
Recommendations: when to use Flink vs. Kafka
Kafka is a message broker with a stream processing engine in the form of Kafka Streams. So, it works best when there is a real-time event processing use case. Kafka brokers can route messages using topics to various destinations, and Kafka Streams can be used for any querying or transformation. If your use case is an event-driven system with various microservice integrations and simple transformation, Kafka will be a good fit.
If your use case involves processing only streams from databases, file systems, etc, you may not need Kafka. You can build a Flink-based data platform that pulls data from various existing sources. Similarly, if your organization already has a message queue or a broker other than Kafka, Flink could be a better fit since it has better integration with message brokers like ActiveMQ, RabbitMQ, etc.
A production-grade data pipeline requires a high degree of scalability, durability, and high availability. This is where combining Kafka and Flink becomes tempting. In the scenario where both exist, the architecture can even tolerate the highly unlikely scenario of Flink going down because Kafka will buffer the messages until Flink comes back online.
An architecture that consists of a distributed fault-tolerant buffer and a stream processor that can handle complex event processing is very powerful and can handle almost all data processing use cases under the sun.
It is important to note that Kafka is not the only streaming platform that works with Flink. Redpanda is a source available (BSL), Kafka-compatible streaming data platform designed from the ground up to be lighter, more powerful, and simpler to operate. It employs a single binary architecture, free from Apache ZooKeeper™ and JVMs, with a built-in Schema Registry and HTTP Proxy. You can replace Kafka with Redpanda for all use cases, especially when combined with Flink.
[CTA_MODULE]
Conclusion
Kafka and Flink are purpose-built data technologies for specific use cases. Kafka is a distributed event streaming platform with a stream processing engine called Kafka Streams. It is excellent for facilitating real-time processing on unbounded event streams.
On the other hand, Flink is a dedicated data processing engine that can work in batch and real-time stream mode. It can process data from various sources, including message queues, databases, and file systems. Flink is more focused on analytical use cases when compared with Kafka Streams.
Choosing one as a replacement for the other is not an option in most cases. In reality, both complement each other. An architecture combining a Flink and Kafka replacement, like Redpanda, can lead to a powerful system that handles almost all use cases.
[CTA_MODULE]