




AI agent governance at scale: the four pillars every enterprise needs
Enterprise agents need governance infrastructure, not just better models
Pros, cons, and considerations when choosing the right ML framework









Both TensorFlow and PyTorch have features built to handle large volumes of data. TensorFlow, despite introducing dynamic computations in version 2.0, still offers the possibility to define static computation graphs, which allows for multiple optimizations leading to faster processing times and better utilization of hardware resources for large data sets. PyTorch, on the other hand, offers only dynamic computation graphs that are less efficient than TensorFlow's static graphs when scaling to large data sets.
PyTorch's user experience is characterized by flexibility and easy implementation of machine learning models, thanks to its approach to dynamic computation. TensorFlow, on the other hand, has improved its user experience by introducing eager execution in version 2.0, which allows code to be executed immediately. However, some users might still find the TensorFlow API more cumbersome and less intuitive than PyTorch, especially when dealing with legacy code.
API verbosity refers to the amount of code required to perform the same or equivalent tasks in different programming interfaces. PyTorch is known for its straightforward Pythonic API that allows for quick prototyping and dynamic code adjustments. On the other hand, TensorFlow's API was historically more verbose, requiring more lines of code for the same task. However, with the introduction of eager execution in TensorFlow 2.0, its API has become more similar to PyTorch.
TensorFlow supports multiple programming languages, including Python, C++, Java, JavaScript, and Swift. This allows for the integration of machine learning models into different environments. PyTorch primarily supports Python and also provides the LibTorch library, a C++ frontend for PyTorch. However, PyTorch does not support any other programming languages.
Due to TensorFlow's broad language support, it's a better choice for developers who might need to integrate machine learning models into various environments and applications. TensorFlow supports Python, C++, Java, JavaScript, and Swift, allowing for integration into high-performance applications, enterprise systems, web development, and Apple's ecosystem.
Machine learning (ML) has transformed problem-solving in software development. At its core, ML involves training algorithms to perform specific tasks by learning from data rather than being explicitly programmed to do so.
Various frameworks offer prebuilt methods, functions, and structures that simplify the complex tasks of designing, training, and deploying ML applications. PyTorch and TensorFlow are two of the most popular frameworks in the ML community because of their flexibility, extensive libraries, and active support.
This post explores both frameworks and compares them based on the following:
We also dig into how each framework supports building streaming data applications, including their compatibility with Apache Kafka® and integration with Redpanda to handle real-time data streams easily. Let’s get started.
API verbosity refers to the amount of code required to perform the same or equivalent tasks in different programming interfaces. In this context, PyTorch is often praised for its straightforward Pythonic API that resonates with the preferences of the Python community for readability and simplicity. Its interface design is intuitive and allows you to perform quick prototyping and dynamic code adjustments during the model development process. PyTorch's dynamic computation graph largely enables this, Autograd, which can perform immediate error checking while programming and provides an interactive environment for ML development. As a result, this can significantly reduce the time spent on debugging.
From a historical point of view, TensorFlow's API was more verbose and required more lines of code to achieve the same task as PyTorch. One primary reason was TensorFlow's static computation graphs, which required the user to define the entire computational graph before execution —often leading to more boilerplate code and less immediate feedback during development.
However, eager execution became the default mode in TensorFlow 2.0, which resulted in its API becoming more similar to PyTorch. As in the case of PyTorch, eager execution allows operations to be evaluated as they are written, so subsequent versions of the TensorFlow API after 2.0 are much less verbose than before.
The following image depicts the same ML operation programmed in different versions of TensorFlow and PyTorch:
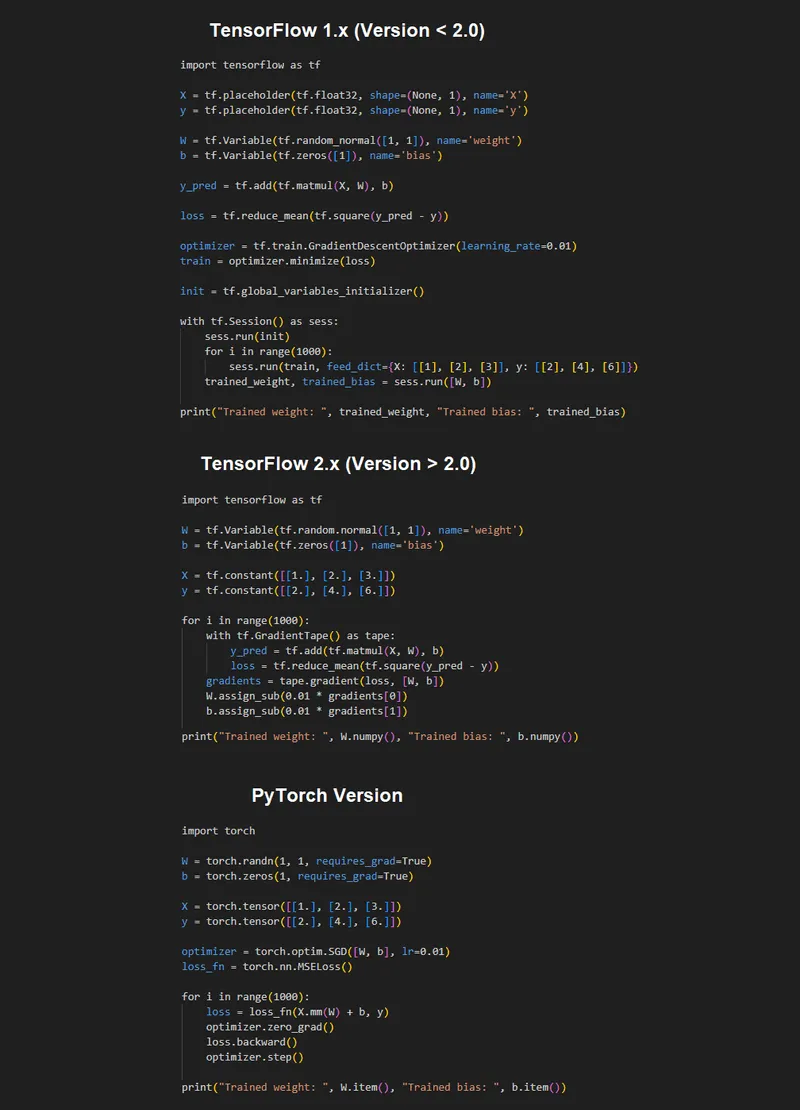
As you can see, TensorFlow 1.x required more boilerplate code than version 2.x and PyTorch to achieve the same result.
In this context, PyTorch is better in research and academic settings, where its less verbose API allows researchers to experiment with new ideas and iterate more quickly. In contrast, TensorFlow encourages its users to conduct thorough planning and provides explicitness in the API, which benefits large-scale production models. For this reason, TensorFlow is better suited for robust, optimized deployment in industrial environments.
PyTorch's user experience is characterized by flexibility and the easy implementation of ML models. This flexibility comes from PyTorch's approach to dynamic computation. In this case, ML models are built and modified interactively, so developers see the results of their code changes immediately without the need to compile the models beforehand. This makes debugging and implementing complex projects requiring frequent adjustments much easier.
TensorFlow has made significant strides towards a better user experience by introducing eager execution in version 2.0 and making dynamic computation the default mode. This shift mirrors PyTorch in allowing code to be executed immediately and creating an interactive coding environment where changes can be made and tested on the fly. Eager execution in TensorFlow simplified the debugging process and lowered the learning curve for newcomers compared to earlier versions of TensorFlow.
Despite these improvements, some users might still find the TensorFlow API more cumbersome and less intuitive than PyTorch. This is particularly true when transitioning from older TensorFlow versions or dealing with legacy code.
A machine learning framework must efficiently handle large data sets, particularly when it comes to training complex models on extensive data. Both TensorFlow and PyTorch provide features built to handle large volumes of data. However, how each framework approaches computation can significantly influence performance in these scenarios.
Despite introducing dynamic computations in version 2.0, TensorFlow still offers the possibility to define static computation graphs, which are predefined sets of operations that TensorFlow executes in a fixed sequence. In particular, a static computation graph allows TensorFlow to know all executions ahead of time and perform multiple optimizations such as operation fusion, memory allocation, and parallel execution.
By optimizing the execution plan ahead of time, TensorFlow can much better manage available resources, thus reducing computational overhead and improving runtime speed. These optimizations are very beneficial when dealing with large volumes of data, which usually require more operations and additional resources. TensorFlow's optimizations ensure that operations are executed in the most efficient way possible, leading to faster processing times and better utilization of hardware resources for large data sets.
On the other hand, PyTorch offers only dynamic computation graphs that are created on the fly during execution time. These dynamic computation graphs are less efficient than TensorFlow's static graphs when scaling to large data sets.
Both frameworks support distributed computing, enabling parallel processing of large volumes of data. However, TensorFlow has much more mature and well-established support for distributed computing, giving it an edge over PyTorch. In the end, while PyTorch offers a competitive solution for handling large data sets, TensorFlow tends to have an edge in performance due to better resource utilization and support for distributed training.
TensorFlow supports multiple programming languages. Its primary language is Python, the most popular language for machine learning and data science. Furthermore, TensorFlow supports other languages, including C++, Java, JavaScript, and Swift. This allows you to integrate machine learning models into different environments, such as high-performance applications, enterprise systems, web development, and Apple's ecosystem.
PyTorch, on the other hand, offers significantly less support for different programming languages. It primarily supports Python and also provides the LibTorch library, a C++ frontend for PyTorch that enables the use of PyTorch models in C++ applications. Other than that, PyTorch does not support any other programming languages.
Due to TensorFlow's broad language support, it's a better choice for developers who might need to integrate ML models into various environments and applications.
Since its release in 2015, TensorFlow has been a dominant player in the machine learning field. In comparison to PyTorch, TensorFlow has a larger and more established community that contributes to its extensive resources, including tutorials, courses and books, and a forum. TensorFlow's efficient processing of large data volumes and its scalable architecture make it a preferred framework for production-grade applications.
Companies like Google, Uber, Waymo, and many others use TensorFlow for complex tasks such as search algorithms, real-time translations, and autonomous driving. In fact, TensorFlow has by far the biggest market share in the production environment at 38 percent, followed by PyTorch with a market share of 23 percent.
Although it's not the most significant player in the production environment, PyTorch has seen a significant rise in popularity in the research community. PyTorch's dynamic computation graph and user-friendly interface for debugging and development have led the framework to dominate the ML implementations for scientific papers in the last four years:

Ratio of different ML frameworks for paper implementation (courtesy of Papers With Code)
Although TensorFlow and PyTorch are both open source, they use different licensing models that can influence their use in practice. PyTorch operates under the BSD 3-Clause License, which permits users to make modifications for proprietary use. In particular, they can integrate PyTorch into closed-source products without disclosing their own source code. Users only need to include the original copyright notice, a list of conditions, and a disclaimer of liability.
On the other hand, TensorFlow uses the Apache License 2.0, which is permissive and allows users to use, modify, and distribute the software freely. The main difference between the two license models is that the Apache License 2.0, unlike the BSD 3-Clause License, includes an explicit grant of patent rights from contributors to users. This gives additional protection against patent litigation for those who use TensorFlow. As a result, TensorFlow might be better for businesses and organizations with concerns regarding potential patent issues and seek additional legal protection against patent litigation.
Businesses and organizations prioritizing flexibility and simplicity in legal requirements prefer PyTorch's licensing model, as they can integrate and modify the software for proprietary use without the complexities associated with patent considerations.
TensorFlow and PyTorch both provide extensive libraries of pre-trained models that can streamline the development and deployment process for machine learning applications.
On the one hand, TensorFlow Hub includes many TensorFlow models across domains such as image, text, and audio processing. The models in this repository are also well-optimized for performance and scalability. TensorFlow Hub also supports features like transfer learning, allowing you to adjust the models to new tasks by retraining them on a specific data set. All of these features make TensorFlow Hub better suited for production environments.
On the other hand, PyTorch Hub favors the research community. Here, PyTorch Hub shines in scenarios where deep customization and continuous model development are needed. This makes PyTorch Hub, in comparison to TensorFlow Hub, particularly well-suited for academic projects where adapting and extending already existing ML models is more common.
TensorFlow and PyTorch both offer support for streaming data applications, which can be further enhanced through integration with Apache Kafka. This integration allows TensorFlow and PyTorch models to receive streaming data and train on it or perform inference in real time or near real time.
TensorFlow's suite of libraries allows it to handle large and continuous data streams. For example, TensorFlow's tf.data module can perform high-throughput data processing and is designed to work with TensorFlow's training and inference pipelines. As it supports complex data transformation operations and can handle data loading and preprocessing, the library is instrumental in streaming scenarios where data needs to be processed in real time or near-real time.
Additionally, with TensorFlow Transform, TensorFlow provides another library to help preprocess streaming data directly within the TensorFlow graph. Furthermore, TensorFlow's Object Detection API allows for the detection of objects in a video stream, which can be applied to surveillance or traffic management systems. This API and others provided by TensorFlow can process live video feeds to identify objects, track movements, or analyze patterns.
Similarly, developers can also use PyTorch in data streaming environments. Its torch.utils.data module offers data loading and preprocessing capabilities to manage large and continuous data streams. This is also supported by the DataLoader class, which enables high-throughput data operations. Additionally, PyTorch's capabilities in handling live video feeds are enhanced by its torchvision library, which includes pre-trained models for object detection that can be applied to scenarios such as surveillance or traffic management.
In a streaming use case, TensorFlow could be handy in production-scale applications that require continuous data processing, such as real-time analytics or live video processing for object detection. On the other hand, PyTorch would be better suited for developing applications that benefit from quick iterations and experimental approaches, such as adaptive streaming algorithms in research settings.
While both frameworks can integrate with Kafka for data streaming, it's worth noting that their capabilities may not be fully optimized for the demands of modern ML. TensorFlow and PyTorch have continually evolved to leverage the latest computing power and data processing advancements. However, since Kafka was built for systems in 2011, it may only inherently support the quickly evolving ecosystem of ML technologies with additional configuration or plugins.
For example, ML models in use cases such as real-time analytics or live video processing need real-time data streaming and processing at a scale and speed that Kafka was not initially designed to support. Furthermore, Kafka's data serialization and deserialization processes might be less efficient for the binary data formats commonly used in ML frameworks.
Redpanda is a proven Kafka replacement that’s leaner, faster, and simpler to operate. Redpanda is built to simplify and accelerate real-time streaming data, which is particularly important in online training scenarios. In online training, ML models are continuously retrained on newly arriving data streams. This allows them to learn from the most recent data, quickly adapt to changes, and improve their predictive accuracy over time. This method of ML model training is particularly useful in dynamic environments where patterns frequently change.
When integrated with PyTorch or TensorFlow, Redpanda provides a more efficient alternative to Kafka, as the platform ensures quicker data throughput and lower latency. This directly benefits online learning scenarios that require low-latency data handling solutions to manage the continuous flow of data to update the models. As a result, Redpanda, PyTorch, or TensorFlow models can almost instantaneously retrain on the newly arriving data streams.
Choosing the right ML framework depends on various factors, which can make it challenging to decide. In a nutshell, PyTorch excels in research and prototyping, whereas TensorFlow works well in production settings.
You also learned how TensorFlow and PyTorch can integrate with Apache Kafka to facilitate real-time data processing. Compared to Kafka, Redpanda can significantly enhance the efficiency of these ML frameworks in streaming use cases by providing faster data throughput and lower latency.
To keep exploring Redpanda and how to easily integrate it with your ML workflows, visit the Redpanda documentation. Additionally, the Redpanda blog is brimming with tutorials to help you get the most out of the platform. If you have questions or want to discuss specific use cases, join the Redpanda Community on Slack!
Enterprise agents need governance infrastructure, not just better models

What AI trends will shape analytics in the coming months?

How we turned opaque agent behavior into governed, provable workflows
Subscribe to our VIP (very important panda) mailing list to pounce on the latest blogs, surprise announcements, and community events!
Opt out anytime.