





Deploy agents you can trust with centralized AI governance
You can't scale what you can't trust. A governance layer fixes that.

Get the 101 on real-time streaming data, common use cases, and popular tools to start your journey on the right foot.








Stream processing technologies manage continuously generated events to analyze and process them as they come in. These data streams are then translated into text, logs, images, or other media that you can visualize and make use of. This process allows you to turn the data into useful insights that you can act on, such as blocking a fraudulent credit card transaction after the data has been processed and triggers a notification of suspicious activity.
Streaming data in real time has several valuable use cases. It can be used for real-time analytics, allowing businesses to monitor and analyze data as it's generated for instant insights into ongoing processes, user behavior, or market trends. Streaming data also enables event-driven architectures (EDAs), which react to events or messages generated in real time. Additionally, streaming data technologies can be used to perform real-time or near real-time Extract, Transform, and Load (ETL) and Extract, Load, and Transform (ELT) processes for data integration.
Streaming data refers to continuous, real-time flows of information generated from various sources and processed incrementally as it arrives. Unlike batch processing where data is collected and processed in large chunks, streaming data is processed record-by-record or in small time windows, enabling immediate insights and actions. Sources include IoT sensors, application logs, financial transactions, social media feeds, clickstreams, and mobile devices. Streaming data is characterized by high velocity (rapid generation), high volume (large amounts), variety (different formats), and time-sensitivity (value decreases over time). It powers use cases like real-time analytics, fraud detection, recommendation engines, monitoring systems, and live dashboards. Streaming architectures typically include data producers, streaming platforms (like Redpanda), stream processors, and data consumers. Key challenges include handling out-of-order data, managing state, ensuring exactly-once processing, and scaling to handle variable loads. Technologies like Redpanda provide the infrastructure to reliably capture, store, and distribute streaming data at scale while maintaining low latency and high throughput essential for real-time applications.
Batch processing collects, stores, and then processes data in fixed-size chunks at specified intervals. It's suitable when immediate insights aren't necessary and the focus is on precise, comprehensive analysis of historical data. Stream processing, on the other hand, generates, processes, and analyzes data in real-time or near real-time. This allows organizations to analyze data while it's still fresh, enabling quick reactions to changing circumstances and data-driven decisions.
Data is today’s most valuable currency. Modern applications can have petabytes of data streaming in and out from multiple sources, and the growing need for instant feedback and accurate business insights is pushing organizations to find better ways to process and analyze all of that data in the blink of an eye.
As more industries embrace the advantages of data processing in real time, it’s becoming painfully apparent that the traditional, slow, scheduled way of processing data just isn't going to cut it. Fraud detection is only effective if it’s caught before it gets too far. Customers only care about a product if it’s recommended when they actually need it, not a week later. Retailers need to know how much inventory is actually left so they don’t oversell a product that’s no longer in stock.
The true value of data isn’t just how much of it you can collect, but how quickly it can be turned into usable insights, which is where data streaming steps in. But streaming data can be complex for newcomers, and challenging to implement, manage, and scale for the unprepared.
In this introductory post, we give you the 101 on streaming data. We’ll explain what it is (in plain English), explore the differences between data processing and stream processing, and cover some common challenges, use cases, and tools to start you off on the right foot.
Ready? Let’s start with the basics.
Streaming real-time data is basically data that flows continuously as it’s generated from multiple sources, like sensors, devices, applications, and users. It’s constant and unbounded in nature, with no real beginning or end.
You may also see it described as “event streaming”, where an event is a changed state within a system. For example, an event could be triggered by a customer clicking on a product, or a dip in the stock market. These events can feed into business dashboards and flow into other systems for processing and analytics.

So, what about stream processing? Once you have all that data, you need to actually turn it into useful insights that you can act on. For example, you can only block a fraudulent credit card transaction after the data has been processed and triggers a notification of suspicious activity. But until that data gets processed, you won’t get the notification and can’t actually do anything about it.
Stream processing technologies manage continuously generated events to analyze and process them as they come in. These data streams are then translated into text, logs, images, or other media that you can visualize and make use of. We’ll cover the most popular stream processing technologies later in this post.
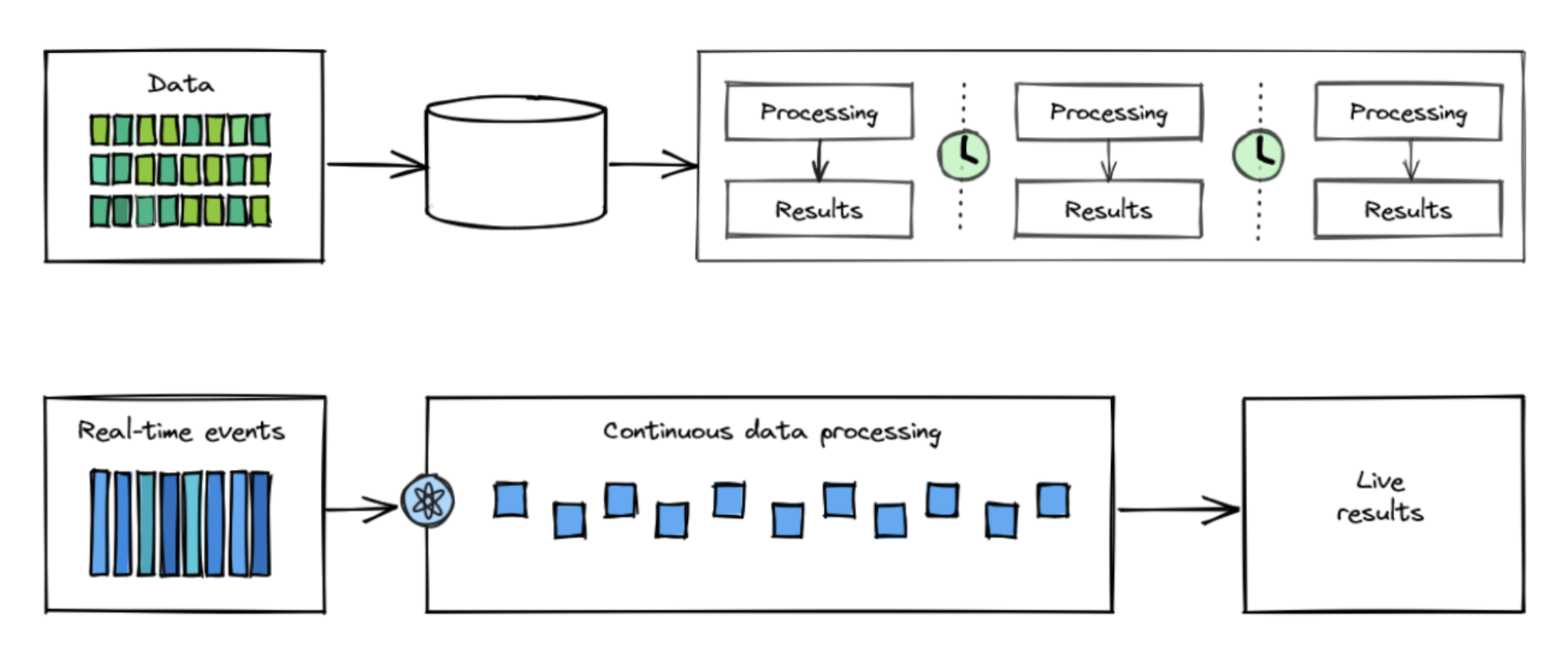
In a nutshell: batch processing collects, stores, and then processes data in fixed-size chunks at specified intervals. In stream processing, data is generated, processed, and analyzed in real-time or near real-time. This allows organizations to analyze data while it’s still fresh so they can react quickly to changing circumstances and make better-informed, data-driven decisions.
Now that you have a general idea of what each processing approach is about. Let’s dig a little deeper so you know when to use them and why.
Think of batch processing as sending physical letters in the mail. Your message goes into the letter, the letter goes in an envelope, and then the postal service delivers your message in one go.
Batch processing is suitable when immediate insights aren’t necessary. The focus is on precise, comprehensive analysis of historical data rather than speed. This makes batch processing great for tasks with set intervals like payroll, billing, or preparing orders for customers.
Say, for example, you run an e-commerce store. Your warehouse workers clock in at 7 AM. Every day at 6.45 AM you want your system to process and print all customer orders. This way, your warehouse workers can start each day with freshly printed packaging slips, packaging labels, and the number of each box size needed for their orders.
Some batch processing can handle this process several times every day, but the latency in batch processing can range from several hours to days. So if you want something faster, you’ll want to go with stream processing.
If batch processing is like sending a letter, stream processing is like messaging in an online chat app—we say what we want in real time without having to wait for the other participants to finish typing their response to our last message.
Data processing is particularly valuable when dealing with time-sensitive data, analytics or when organizations need to respond quickly to changing circumstances. At this point you’ve already seen the terms “real-time and near real-time processing”, but let’s explain them to make sure we’re all on the same page.
Streaming data in real time has a big payoff for businesses. Here are some of the most valuable use cases you should know about.
Real-time analytics with streaming data: Real-time analytics lets businesses monitor and analyze data as it’s generated for instant insights into ongoing processes, user behavior, or market trends. This allows organizations to react quickly to rapidly-changing circumstances. This is particularly useful for monitoring website traffic, tracking social media sentiment, analyzing stock market fluctuations in real time, etc.
Event-driven architectures (EDAs): EDAs are systems that react to events or messages generated in real time. In these systems, data streaming enables seamless communication between components, services, or microservices. EDAs can ensure responsiveness, adaptability, and scalability in modern applications like e-commerce platforms, gaming systems, or IoT ecosystems.
Data integration and ETL/ELT: Extract, Transform, and Load (ETL) and Extract, Load, and Transform (ELT) processes are essential for integrating real-time data from multiple sources and transforming it into a standardized format for further analysis. Streaming data technologies can be used to perform real-time or near real-time ETL/ELT, so only the most up-to-date data is analyzed. This is extremely useful when real-time data from various sources is combined and analyzed quickly for use cases like customer 360-degree views, real-time inventory, or business intelligence applications.
Internet of Things (IoT) applications: Streaming data solutions are crucial in ingesting, processing, and analyzing data from IoT devices. Organizations monitor and control their IoT devices, optimize processes, and detect anomalies through streamed data. Use cases include smart home systems, industrial automation, connected vehicles, and wearable devices.
Stream processing for machine learning (ML): ML models often require large volumes of data for training and validation. Streaming data can be used to update and refine these models in real-time or near real-time. This enables organizations to adapt to changing patterns and trends. The most popular use cases are anomaly detection, sentiment analysis, and recommendation systems since these scenarios can’t wait for batch-processed data.
Once you understand the power of streaming data, there are endless possibilities for building real-time data applications to keep pace with today's data-driven world. But before you jet off, let’s look at some of the challenges and considerations.
Now that you have the lay of the land, let’s get into the tricky part: actually streaming data. Murphy’s Law is forever relevant, so when it comes to streaming, you’ll want to be ahead of any potential issues.
Here are the main factors to keep in mind:
Before you start, you’ll want to make a solid plan to avoid any unpleasant surprises down the road. Here’s what you need to consider:
Scalability and performance: Be sure to consider your system’s ability to handle data volumes and processing loads at peak demand times. You’ll want to choose in advance if you’re building a streaming data system that can scale horizontally (by adding more virtual machines) or vertically (by adding more computing power in a virtual machine). You also need to know the throughput and latency in your system. Your real-time application must have low latency – even at peak hours.
Data partitioning and sharding: To improve the performance and scalability of your streaming data solution, consider partitioning and sharding data across multiple nodes or clusters. In partitioning, you break data into smaller and more manageable pieces. In sharding, you distribute the pieces across multiple databases or servers. This allows you to spread the load across the system and improve performance.
Reliability and fault tolerance: You can safeguard against failures and secure fast recovery with redundancy and checkpointing. Redundancy means replicating data across multiple nodes and clusters. Checkpointing defines the time intervals you want data saved – depending on the value of the data, you might not want all of it to be saved all of the time.
Security and privacy concerns: Being fast, easy, and cheap isn’t all there is. You should also make sure your streaming data system encrypts data (at rest and in transit), uses secure protocols, and has stringent access control mechanisms. In some cases, you also need to consider data sovereignty and comply with data protection regulations, like GDPR.
When you’re looking at implementing streaming data in your organization, you’ll want to build a modern streaming stack by combining analytics components of different vendors, technologies, and platforms. Here’s a diagram showing how those parts work together to ingest, process, and analyze events in real time.
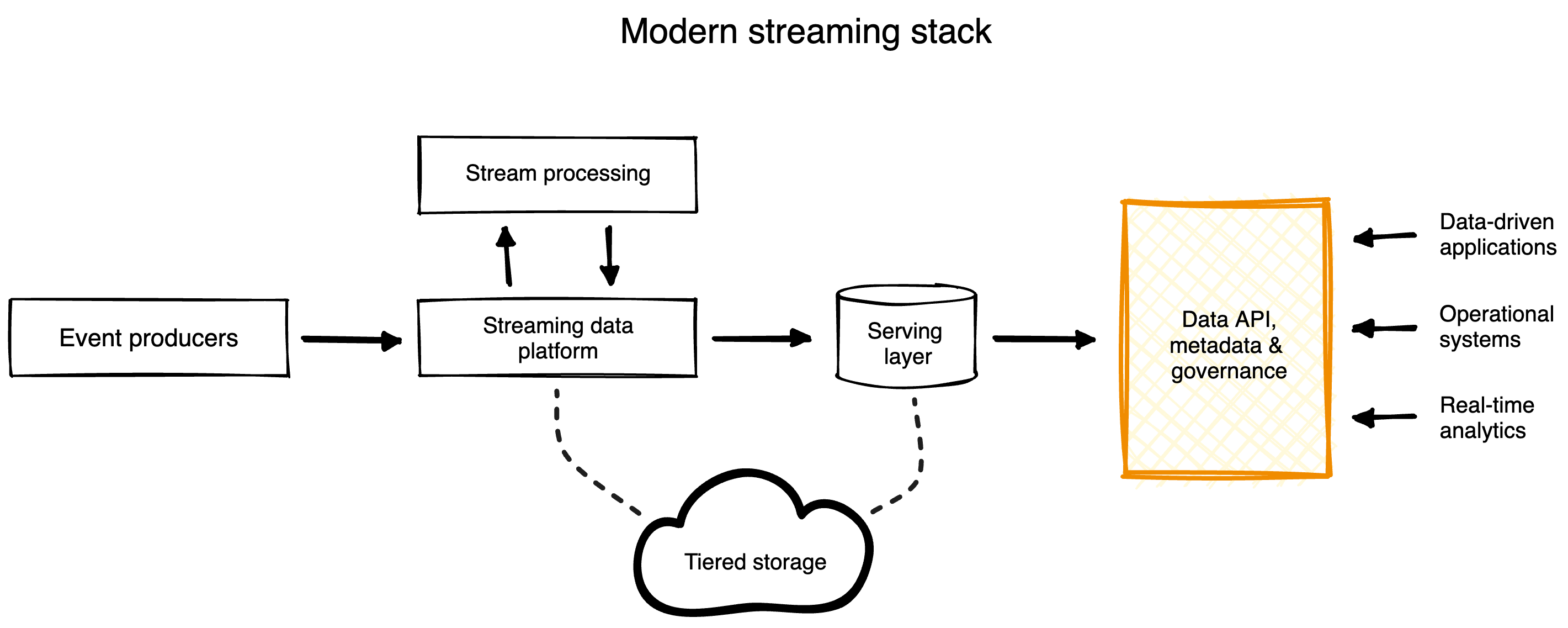
Let’s briefly unbundle the main components. (We’ll go into more detail on the remaining components in our upcoming post: real-time analytics 101).
However, Kafka was designed way back in 2011 to make the best of cheap spinning disks, not to maximize today’s powerful CPUs and network cards. Kafka’s design includes legacy dependencies on the Java Virtual Machine (JVM) and resource-intensive external components, such as ZooKeeper/KRaft and Schema Registry—leaving much of the power of modern infrastructure on the table.
As a result, organizations end up overpaying for computing power in the long run as they struggle to scale complex Kafka clusters. This is why simpler, more cost-efficient, and higher-performing data streaming architecture alternatives are emerging, like Redpanda.
Redpanda is a new breed of data streaming platform that supports real-time, mission-critical workloads without breaking the bank or overburdening ops. It’s built from the ground up with a native Kafka API, which means it acts as a drop-in replacement and works seamlessly with the full ecosystem of tools and integrations built on Kafka.
In short, Redpanda is:
The bottom line is that Redpanda is purpose-built for the present and the future of data streaming. To get started, you can find Redpanda Community Edition on GitHub or try Redpanda Cloud for free. Then go ahead and dive into the Redpanda Blog for examples, step-by-step tutorials, and real-world customer stories.
If you get stuck, have questions about streaming data, or want to chat with our savvy developers and engineers, introduce yourself in the Redpanda Community on Slack!
Congratulations! You now know a whole lot more about streaming data than you did 30 minutes ago. Since you’re all warmed up, here are some handy reads to keep the ball rolling:
You can't scale what you can't trust. A governance layer fixes that.

Your lakehouse mirrors the database, instantly.

What is it, why enterprises need it, and how to evaluate one
Subscribe to our VIP (very important panda) mailing list to pounce on the latest blogs, surprise announcements, and community events!
Opt out anytime.