

Kafka broker—a deep dive











Kafka broker
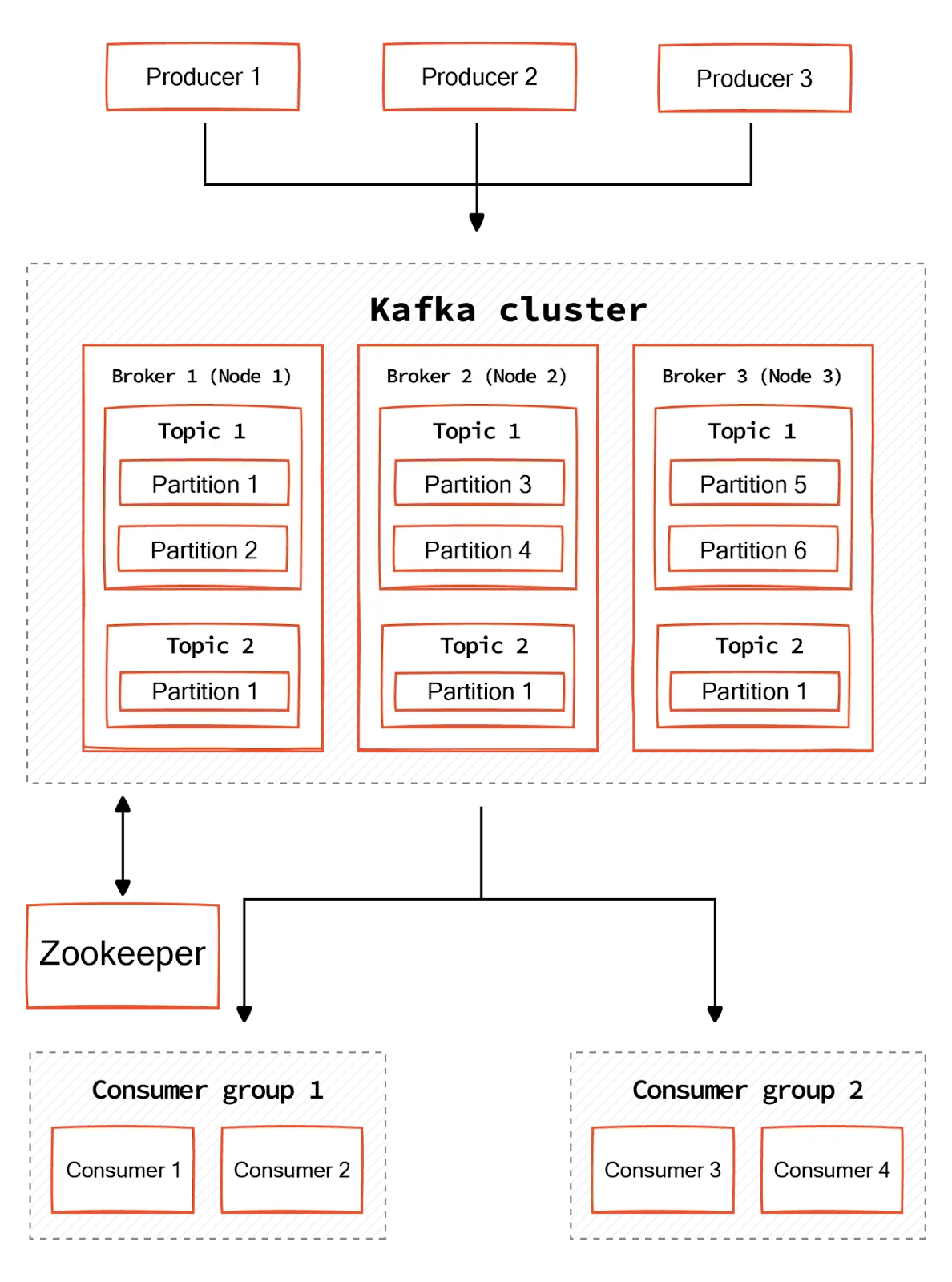
A broker is the core computational node or server of the Apache Kafka® ecosystem. It contains topic partitions (log files) that store messages in an immutable sequence. Producers send messages to Kafka brokers, and the broker stores the data across multiple partitions. Consumers connect to these brokers to fetch data from the topics they subscribe to. Kafa brokers ensure that data is reliably available to consumers despite potential system failures.
This article covers core functions, management basics, and solutions to common Kafka broker challenges.
Summary of key Kafka broker concepts
Core functions of Kafka brokers
Kafka brokers perform core data and metadata management tasks central to Kafka’s operation as a robust, scalable, and fault-tolerant data streaming system.
Message management
When a producer publishes a message to a topic, the broker determines which partition within the topic to place the message based on either the producer's specified key (which determines the partition deterministically) or through a round-robin selection if no key is specified.
Consumers typically operate as a group to read records from the topic partitions. Each consumer in a group reads from exclusive partitions of the topic, and Kafka brokers keep track of which consumer is reading from which partition. This coordination helps effectively distribute the load and ensure that each message is delivered to only one consumer in the group as per the group's consumption policy.
Kafka brokers also track the offsets, which are the positions within the log of each partition, to know which messages have been consumed and which have not. Keeping track of offsets ensures that consumers can resume consuming from where they left off in case of failures or rebalances among consumers in a group.
You can read more about Kafka consumer groups in a different chapter of this guide.
Replication
Multiple brokers get together and operate as a cluster for high availability and scalability. Kafka can replicate each partition across multiple brokers in the cluster. One of the brokers in the cluster acts as the partition leader. The leader for each partition handles all read and write requests for that partition, while follower replicas sync their state to the leader. Upon a leader's failure, one of the followers is automatically elected as the new leader. This means that even if a broker goes down, the data is not lost and can still be served by other brokers with replicas of the same partition.
Metadata management
Brokers also handle significant amounts of metadata, essential for Kafka's functioning. For example, they track the creation of new topics and partitions and manage their respective metadata. This includes maintaining a list of topics, the number of partitions each topic has, and the location of those partitions across the cluster's brokers.
Example of data interaction with Kafka brokers
To bring these concepts to life, consider the following simple code example that demonstrates how a producer sends data to a Kafka broker and how a consumer retrieves data from the broker.
# Producer code example
from kafka import KafkaProducer
producer = KafkaProducer(bootstrap_servers='localhost:9092')
producer.send('my-topic', b'Hello, Kafka!')
producer.flush()
# Consumer code example
from kafka import KafkaConsumer
consumer = KafkaConsumer('my-topic',
bootstrap_servers='localhost:9092',
auto_offset_reset='earliest')
for message in consumer:
print(f"Received message: {message.value.decode('utf-8')}")Kafka broker management within a cluster
An external software component called ZooKeeper was traditionally used to manage broker metadata and coordinate broker states within the cluster. However, it created multiple interactions and dependencies that complicated Kafka system management and scalability.
Recently (since version 3.3), Kafka has transitioned to Zookeeper-less Kafka with KRaft. We cover this topic in detail in our chapter on Kafka Zookeeper and only give an overview below.
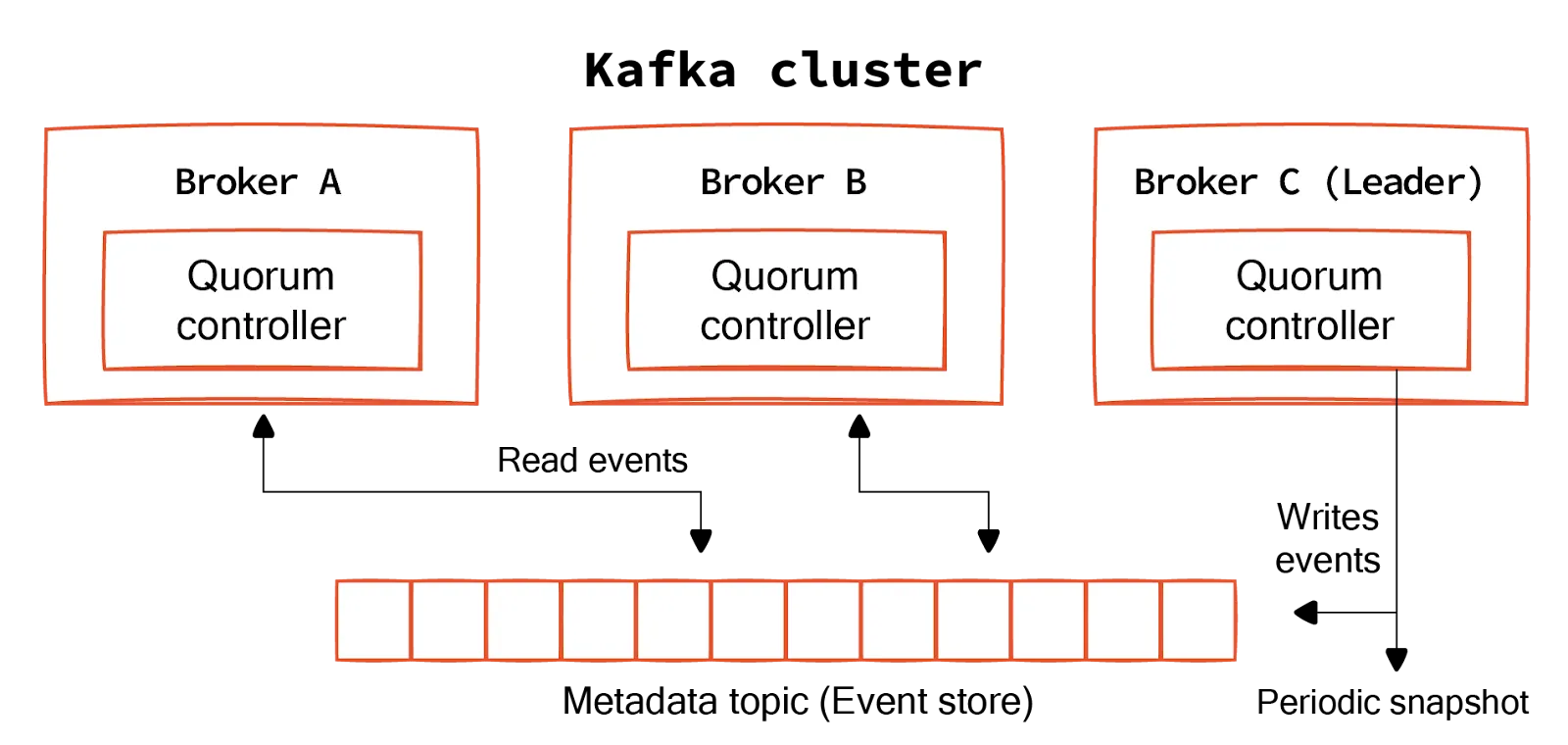
The KRaft protocol allows brokers in a cluster to manage metadata and leader elections by themselves. This consolidation into a single system reduces operational complexity and improves overall system reliability.
Quorum controller
Brokers in a cluster can act as controllers or voters. Controllers manage the cluster metadata and ensure a consistent state across the cluster through a consensus mechanism. These controllers form a quorum—a subset of the Kafka brokers that actively participate in the consensus process to agree on metadata updates.
Metadata log
All metadata changes within a cluster are recorded as a sequence of events in a special Kafka topic known as the Metadata Topic or Event Store. Kafka replicates this log across the controllers, ensuring durability and fault tolerance. Each event in the log represents a metadata operation, such as creating a new topic or modifying an existing one.
Leader election
The quorum controllers use the Raft consensus algorithm to elect a leader among themselves. The leader is responsible for processing all write requests to the metadata and for replicating these changes to the other controllers (followers). The leadership can change during failures, ensuring the cluster remains operational.
The leader broker (Broker C in the diagram above) is responsible for handling all write operations to the metadata topic. It accepts metadata updates, logs them to the metadata topic, and then propagates these changes to other brokers.
The leader also periodically snapshots the metadata state to optimize performance and ensure the metadata topic doesn’t grow indefinitely. These snapshots allow brokers to quickly recover or bootstrap without needing to replay the entire metadata log from the beginning.
Read events
Brokers can read from the metadata topic to stay updated with the latest cluster configuration and metadata state. This ensures that each broker has access to consistent and up-to-date metadata.
Safety
KRaft ensures safety properties to maintain consistency. At most, one leader can be elected in a given period. This prevents multiple leaders from being elected simultaneously, which could lead to conflicting log entries. If two logs contain entries with the same index and term, they are guaranteed to be identical up to that point. This ensures that all committed log entries are identical across brokers. KRaft also supports cluster membership changes, allowing brokers to join or leave the cluster dynamically without compromising safety or consistency.
Kafka broker challenges
Despite these improvements, Kafka broker management comes with its own challenges.
Version control
The transition to KRaft is not without its challenges. For instance, migrating from an older ZooKeeper-based setup to KRaft is complex and requires significant deployment changes. Additionally, as this is a relatively new development, stability and feature parity issues may exist compared to the mature ZooKeeper-based setup.
Configuration
Even when deploying the latest version, configuring Kafka for optimal performance requires an in-depth understanding of its numerous settings and parameters—a daunting task even for experienced users. This includes settings for memory management, file I/O, replication, and consumer group coordination, among others. Achieving the best balance between throughput, latency, and resource utilization requires deep technical expertise and continuous tuning based on usage patterns.
Conclusion
The configuration complexity of Kafka brokers can pose a significant barrier to entry for organizations without the necessary technical expertise. This complexity often leads to higher costs in terms of time and resources spent on training and hiring skilled personnel.
Redpanda is a Kafka-compatible streaming data platform engineered to address Kafka's inherent limitations. Raft is integrated directly into the core of Redpanda, streamlining cluster management and improving stability. In addition:
- Redpanda automates the process of redistributing partitions across different brokers in the cluster, which is particularly useful when clusters are resized.
- By replicating data across different regions, Redpanda ensures that data is accessible even if one location experiences a failure.
- Remote read replicas provide local access points to data, which can significantly reduce latency compared to accessing a central cluster across long distances.
Redpanda thus offers a more user-friendly setup with fewer overheads in configuration and maintenance—lowering the total cost of ownership and operational burden.