

Kafka topics—a deep dive











Kafka topics
Apache Kafka® is a streaming data platform known for its high throughput, scalability, and fault-tolerant nature.
A topic is the fundamental organization unit for events or messages within Kafka. Each topic has a unique name and is a logical group of messages that represent a specific business objective. Topics are divided into partitions to enable parallelism.
This chapter explains how Kafka topics work, as well as various topic-level configurations that one can use to optimize Kafka performance.
Summary of key concepts in Kafka topics
What are Kafka topics?
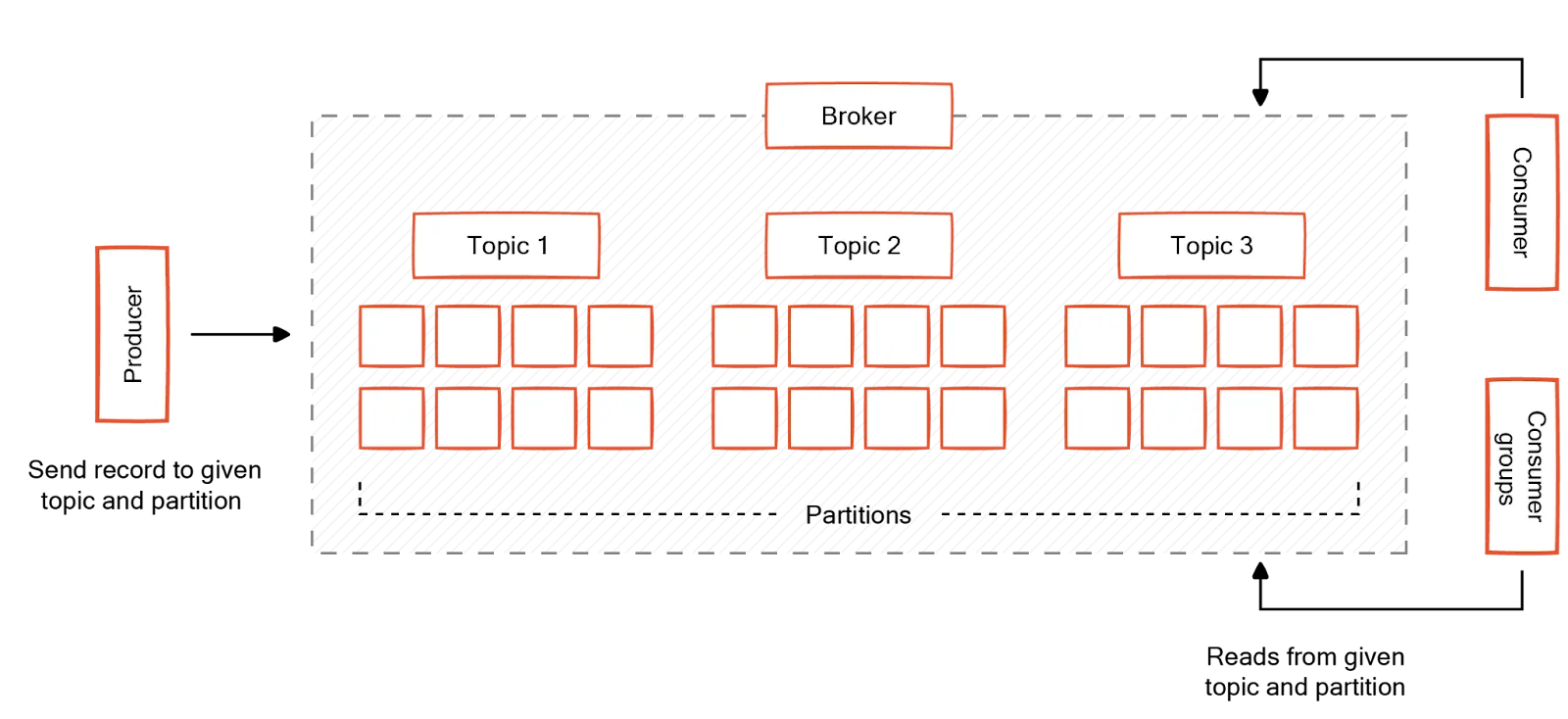
Kafka’s architecture has three components: producers, consumers, and the broker.
Data, represented as messages, flows from producers to consumers via Kafka topics stored in the brokers. Topics serve as logical channels for organizing and distributing the data flow.
Topics are divided into multiple partitions. Partitions contain a subset of messages in a topic in an immutable sequence, ordered by time. Kafka ensures fault tolerance by replicating partitions across multiple brokers—the nodes in a Kafka cluster. If a broker hosting a partition fails, Kafka can automatically failover to a replica hosted on another broker, ensuring data availability and continuity of service.
Topic partitions enable horizontal scalability by distributing the consumer workload across multiple brokers in a cluster. Partitions enable multiple consumers to process data from the same topic. This means that when the data volume or the expected throughput increases, one can add more partitions and spread the load across additional brokers, scaling out the system to handle higher loads.
How Kafka topics work
In Kafka, topics work as a commit log. You can think of a topic as a log file that temporarily stores messages as they move from producers to consumers. It contains an ordered sequence of messages. Producers append messages at one end of the log, and consumers read messages from the other. The entire process is explained in detail in our guide on Kafka logs. We give an overview below.
Overview
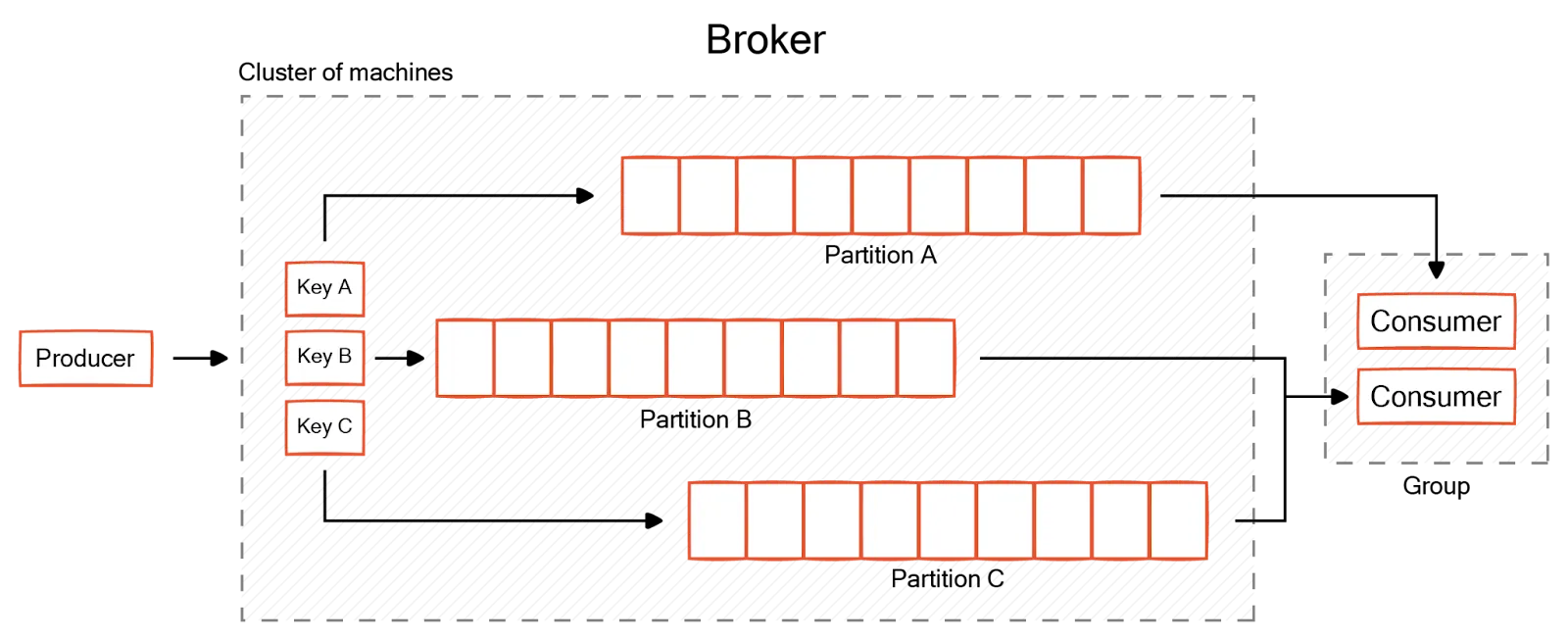
Producers create messages and write to topics. Kafka’s partition mapper decides the partition to which each message goes. All messages with the same key go to the same partition. Based on configurations, producers can adopt a fire-and-forget approach or wait for an acknowledgment from the Kafka broker to receive messages successfully.
Kafka producers will retry sending messages in case of certain errors. The parameter ‘retries’ controls the number of times the producer attempts to retry the message if it receives an error. The attribute ‘delivery.timeout.ms’ controls the time the producer retries before declaring the message a failure.
Consumers subscribe to one or more topics. Unlike the other pub/sub implementations, Kafka doesn’t push messages to consumers. Instead, consumers have to pull messages off Kafka topic partitions.
A consumer connects to a subscribed topic partition in a broker and reads the messages in the order in which they were written. Kafka supports single and multiple-topic subscriptions so that consumers can read messages from different topics concurrently.
Kafka groups the consumers into consumer groups to aid scaling. All consumers in the group subscribe to the same topic. Kafka's consumer group coordination mechanism ensures the subscribed topic partitions are evenly distributed among consumers. It facilitates dynamic redistribution (or rebalancing) when consumers join or leave the group.
Consumers fetch messages only from the partitions they are assigned to. Each topic partition can be consumed by only one consumer within the group. This ensures sequential message processing and ordering guarantees within a partition.
Topic partition offsets
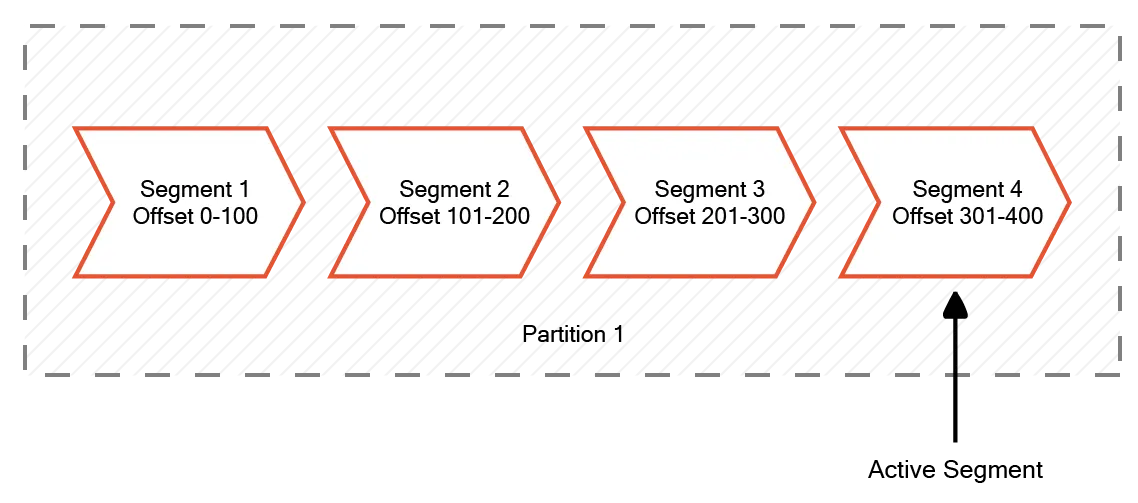
Topic partitions are the fundamental storage element of Kafka. Inside the partitions, Kafka uses offsets to keep track of messages. Offsets represent the order of a message from the beginning of a partition. Offsets help Kafka ensure message ordering and establish delivery guarantees.
Inside the partitions, Kafka divides the data into segments. A segment represents a file in Kafka’s directory structure. Only one segment is active at a time, and Kafka writes the latest data to this segment.
One can control the point at which Kafka commits a segment and begins another segment through two configuration parameters:
log.segment.bytescontrols the maximum size beyond which the segment is committed.log.segment.mscontrols the maximum time Kafka will keep a segment open.
Replication
Kafka partitions are replicated across multiple servers for high message durability. The replication factor is configurable at the topic level. Each topic partition has a leader partition and a set of replicas. All writes will go through the leader partition. Kafka keeps the replica partitions in sync so that any of them can take over when the leader fails.
If the ‘acks’ parameter is set to 0, Kafka adopts the fire-and-forget approach. If it is set to 1, the producer waits for the acknowledgment of the partition leader. The default value for this parameter is ‘all.’
In this case, the producer waits for all the in-sync partition replicas to confirm reception. This increases durability but comes at the cost of some performance. Kafka replication thus allows developers to customize the balance between durability and throughput.
Schema management
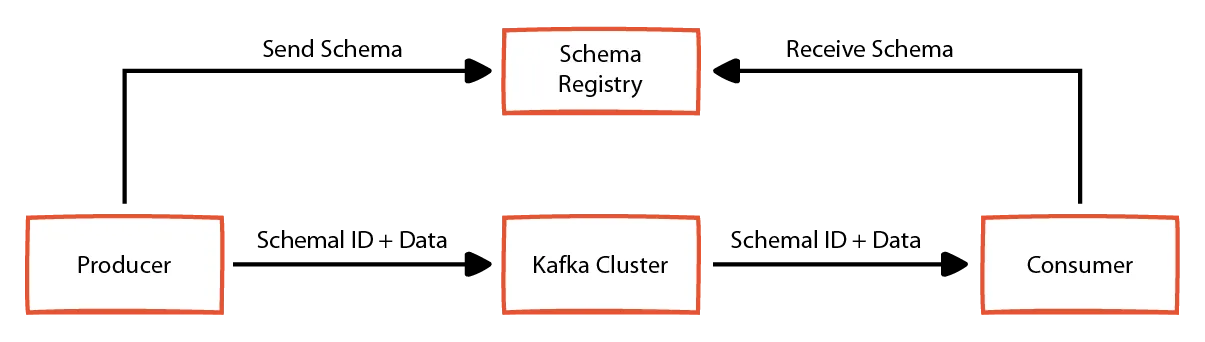
Schema management in Kafka involves establishing standards in the data flow from producers to consumers. Since there is no coordination between producers and consumers in Kafka, it is difficult to establish standards regarding data format within the data. This is where schema management helps.
Kafka manages schema through its schema registry component. For use cases where adhering to specific formats is important, you can use a schema registry to enforce a common format.
Data stays as bytes within the topics. Kafka producers use serializers to convert complex business objects to bytes. Similarly, Kafka consumers use deserializers to convert the fetched bytes to original business objects. A schema registry helps store the schema of these business objects and automatically validates them whenever new messages come.
Compression
Kafka supports compressing data stored in topics to optimize storage. It supports automatically compressing data at the topic level or accepting compressed producer data. One can control the compression behavior using the parameter ‘compression.type’.
In cases where the producer is responsible for compression, this parameter takes the value ‘producer.’ This means compressed data from the producer stays in the same state in topics.
Developers can set it to one of the supported algorithms at the topic level: gzip, snappy, lz4, or zstd. If you configure a different algorithm at the topic level, Kafka recompresses the data using the configured compression algorithm.
Metadata management
Kafka metadata includes information about topics, their partitions, in-sync replicas, and other configurations. Kafka supports two methods for metadata management: an external service called Apache ZooKeeper™ or an internal metadata topic in KRaft configuration mode. It is advisable to use KRaft mode for newer clusters since it is more modern and eliminates many bottlenecks related to Kafka performance.
In KRaft mode, Kafka maintains a metadata log with a quorum of controllers. A leader controller handles all broker requests. The metadata topic is handled like other topics —with partitions, replicas, and offsets.
Setting up and configuring Kafka topics
Kafka provides several utility scripts to set up and manage topics. This section uses two scripts, ‘kafka-topics.sh’ and ‘kafka-configs.sh’, to manage Kafka topics.
To create a new Kafka topic, execute the below command in the CLI.
bin/kafka-topics.sh --bootstrap-server <server_url> --create --topic test-topic --partitions 1 --replication-factor 3 The above command creates a new topic named ‘test-topic’ with a replication factor of 3 and a single partition. One can use the ‘kafka-topics.sh’ to alter any configurations related to an existing Kafka topic.
bin/kafka-configs.sh --bootstrap-server <server_url> --entity-type topics --entity-name test-topic --alter --add-config log.segment.bytes=32000The above command alters the ‘log.segment.bytes’ parameter for an existing topic named ‘test-topic.’
Best practices in Kafka topics
Kafka provides several configuration parameters to optimize its performance according to use cases. The following section details best practices around some of the topic-level configuration parameters.
Optimize the number of partitions
Number of partitions in a topic is a key factor that affects the performance of your cluster. Since a partition is assigned only one consumer at a time, the number of partitions is always kept at par or higher to prevent idle consumers. Since partitions are the basic element of parallelism in Kafka, you determine their number to finish processing the incoming messages in a reasonable time.
As a best practice, add a small buffer percentage to your required number to cover any bursts. You also need to consider any custom key-based partitioning strategy that is in use.
For example, if you use a partition key that can result in a high data volume in a few partitions, the overall topic gets skewed, and the consumers cannot keep up. Having thousands of partitions is also a bad idea since it increases the overhead in the cluster and reduces performance.
Keep in-sync replication below the replication factor
Kafka replicates the partitions to different servers to guard against failures. Depending upon the configuration, producers can wait until all replicas confirm receipt of messages before moving to the next item. While this improves durability, it can lead to a drop in throughput.
Kafka allows configuring the number of in-sync replicas at the topic level through the configuration parameter ‘min.insync.replicas’. Setting this to a value slightly less than the replication factor is often preferred to balance durability and performance.
Use the same compression algorithm for producers and their topic
The ideal scenario for using compression in Kafka is to use the same compression algorithm in both producer and topic. While Kafka allows configuring separate compression algorithms for topics, this causes additional overhead because messages need to be recompressed. Set the topic ‘compression.type’ parameter to the value ‘producer.’ Kafka automatically uses the same compression algorithm that the producer uses.
Typically ‘lz4’ compression provides the best performance, and ‘gzip’ has a better compression ratio. That said, each use case is unique and may require independent evaluation to arrive at the best method.
Turn off automatic validation if not strictly necessary
If the schema registry is turned on, Kafka can automatically validate the messages' schema and raise errors. This helps establish governance standards but is not necessary in all use cases. Having this option enabled may introduce some overhead and can affect throughput. This effect may be higher in cases where compression is enabled because Kafka needs to decompress messages to validate schema.
But if your use case requires schema evolution, none of these arguments are strong enough to avoid schema validation. In that case, keep automatic validation turned on.
Conclusion
Kafka topics help logically group messages based on business objectives. They group messages into logical channels, and operational parameters can be configured specific to the kind of messages being dealt with. Kafka splits topics into partitions to aid parallelism.
On disk, Kafka stores partitions split into several segments, with only one acting as the active segment. To get the best of Kafka, one must carefully tune topic-level parameters to balance throughput and durability.
While Kafka is open source and mature technology, it requires careful configuration and tuning for modern-day use cases. Your teams may have to monitor and reconfigure Kafka topics and partition configurations frequently to suit your use case. This can cause many challenges and bottlenecks as systems scale.
If you’re looking for an alternative that is easier to deploy with seamless scalability and lightning-fast performance, consider Redpanda. Redpanda intelligently redistributes data partitions and cluster leadership so your admins don't have to. To learn more about what it can take off your plate, check Redpanda’s capabilities.