

Kafka ZooKeeper—Limitations and alternatives











Kafka ZooKeeper
Apache ZooKeeper™ is a centralized coordination service for distributed workloads. It performs common coordination tasks, such as electing a primary server, managing group membership, providing configuration information, naming, and synchronization at scale. Its main aim is to make distributive systems more straightforward to operate with improved and more reliable change propagation between replicas in the system.
Apache Kafka® is a distributed pub-sub messaging system that runs over multiple servers (brokers). The brokers need to coordinate with each other, and in the early years of Kafka, ZooKeeper provided this coordination. However, it has recently been replaced with another software component called KRaft. This chapter explores Kafka ZooKeeper, its limitations, and related alternatives.
Summary of key Kafka ZooKeeper concepts
Role of ZooKeeper in Kafka
Kafka is designed as a distributed system with multiple brokers that take messages from producers and pass them to consumers. Brokers typically operate in a cluster for increased fault tolerance and availability.
Initially, ZooKeeper helped the brokers in a cluster co-ordinate with each other. For example, it kept track of broker availability status and determined the main broker or controller within the cluster.
Main functions included:
Configuration management
ZooKeeper acted as a centralized repository or definitive source for managing configurations across the cluster. It provided a single source of truth for configuration parameters, ensuring that all brokers in the cluster followed a designated configuration. This includes configuration changes like topic creation or deletion, which were propagated across the cluster via ZooKeeper.
Leader election
In a broker cluster, a leader broker handles all reads and writes while followers replicate the leader’s data. A leader election happens whenever the leader node goes offline, and the new leader is updated immediately. ZooKeeper acted as the single point to maintain the leader's details. Kafka also facilitated task coordination through ZooKeeper.
Access control lists
Kafka stored Access Control Lists (ACLs) for all topics in ZooKeeper, defining permissions for reading and writing on each topic. It also maintained data such as a list of servers.
Lock management
Lock management is essential in a distributed environment like Kafka to prevent concurrent modifications that could lead to data corruption or loss. Locks are maintained so that systems can operate on a shared resource in a mutually exclusive way for distributive synchronization. ZooKeeper manages locks across the cluster and uses them to ensure Kafka’s cluster configuration and topic configurations remain the same for all Kafka brokers in the cluster.
Membership management
ZooKeeper detected and made updates if any broker left or joined the cluster. It also stored comprehensive information about its structure and state.
ZooKeeper concepts
ZooKeeper's data model closely resembles that of a file system. It operates with small data nodes known as znodes, arranged hierarchically within a tree-like structure.
Znode
Znodes are often referred to as data registers since they can store data. Similar to files within a file system's directories, znodes contain child nodes and associated data. Each znode within the ZooKeeper tree is uniquely identified by a path, where the path components are delimited by "/."
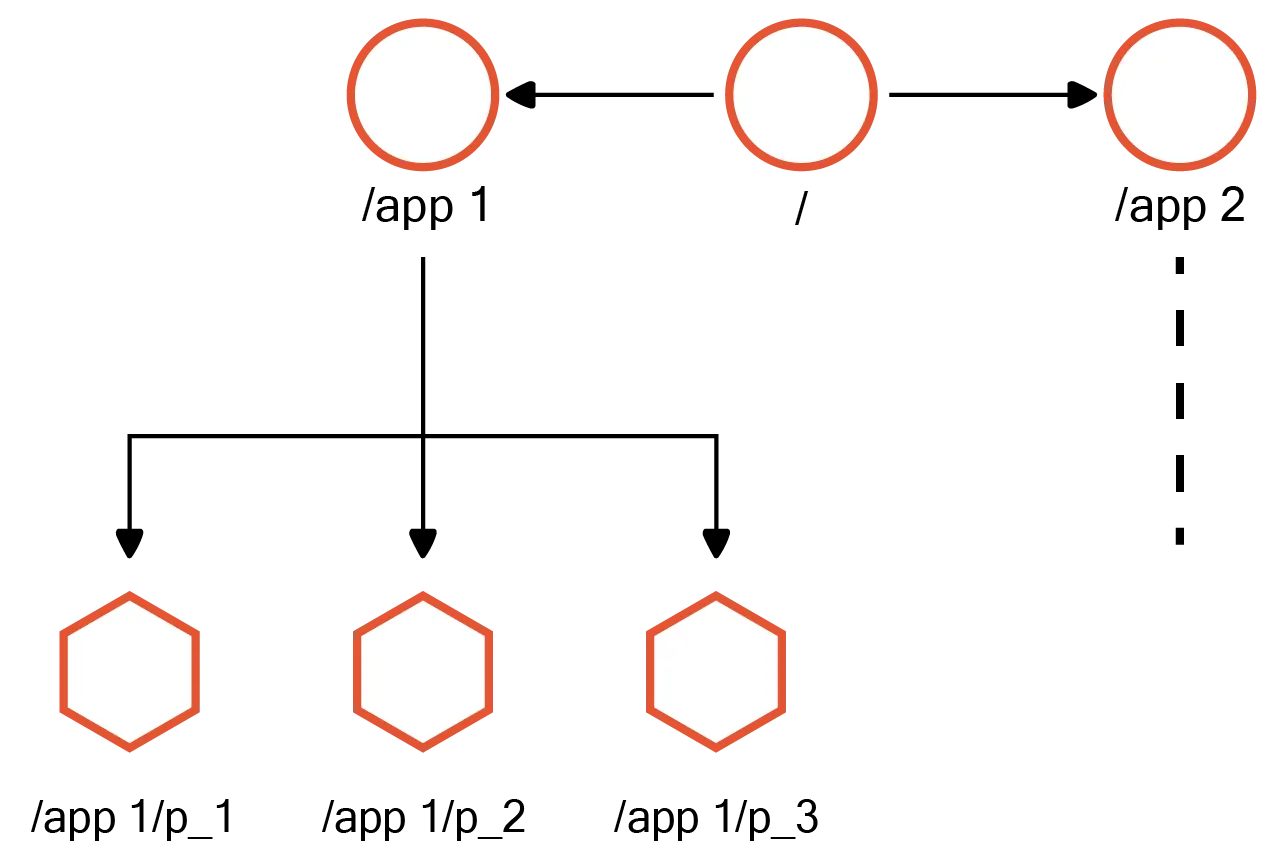
Ensemble
In ZooKeeper, an ensemble refers to a collection of ZooKeeper servers (minimum 3) that collectively coordinate and manage distributed applications. These servers replicate the same data and collaborate to provide fault tolerance and high availability. The ensemble forms the backbone of a ZooKeeper deployment. They ensure the ZooKeeper service remains operational even if any of the individual servers fail or become unreachable.
Session
A session represents a connection maintained between a client and a server. Here, Kafka nodes act as clients, establishing a connection with the ZooKeeper server ensemble. The ZooKeeper server fulfills the client's requests in a first-in, first-out (FIFO) order.
Upon establishing a session, the server assigns a unique session ID to the Kafka client. To maintain the session's validity, the client periodically sends heartbeats. Typically, session timeout values are represented in milliseconds, defining the duration within which no communication from the client results in session expiration.
Watches
Watches serve as mechanisms through which Kafka receives notifications regarding changes within the system. Clients set watches while reading a specific znode. These watches are activated in response to znode data modifications or alterations in the znode's children. The watches are triggered only once upon the occurrence of a relevant change. It is important to note that in case of a session expiration, watches associated with that session are automatically removed.
ZooKeeper Quorum
In public administration, a quorum represents the minimum number of legislators necessary for voting to proceed. In the context of ZooKeeper, it denotes the minimum count of ZooKeeper server nodes that must be operational and accessible for ZooKeeper to function properly. This count also signifies the minimum number of ZooKeeper nodes that must acknowledge storing a Kafka request before acknowledging the data’s successful storage.
In the ZooKeeper cluster, data is written to one ZooKeeper node and replicated across all nodes in the ensemble. However, the process causes delays if Kafka waits for every ZooKeeper node to store data before proceeding. To solve this problem, the system proceeds when the minimum quorum of ZooKeeper nodes replicates the data.
The size of the quorum is defined by the formula Q = 2N+1, where Q defines the number of ZooKeeper server nodes required to form a healthy ensemble, allowing N failure nodes.
For example, if we want to set up a ZooKeeper cluster that can work efficiently if two ZooKeeper server nodes crash, N is 2. So, the ensemble size has to be 5. Thus, as long as 3 ZooKeeper servers have stored the data out of 5, the Kafka request can proceed, with the remaining two servers catching up and eventually storing the data.
Quorums ensure that, despite system delays and failures, any update acknowledged by ZooKeeper is not lost or modified until another request replaces it.
Limitations of Kafka ZooKeeper
Single point of failure
Achieving fault tolerance and ensuring continuous availability in ZooKeeper is tricky as you must run many ZooKeeper server nodes as the same cluster for a minimum quorum. Ensuring the ZooKeeper ensemble works correctly in all possible outage scenarios is costly. Despite the cost, a single point of failure may still occur if most nodes fail concurrently.
Extra overhead
The ZooKeeper cluster is a prerequisite for running the Kafka cluster. Managing a ZooKeeper cluster adds significant operational complexity because administrators have to set up and maintain the ensemble. Configuring parameters, monitoring performance, handling failures, and ensuring security contribute to the complexity. Kafka developers must continuously monitor both systems to sustain health and performance.
Security
Synchronizing ZooKeeper's security model and upgrades with Kafka is a complex task. You must ensure ZooKeeper and Kafka support the same security protocols to secure their connection. This requires careful planning and coordination. By eliminating ZooKeeper, Kafka's security model is streamlined, facilitating simpler management and enhancing overall system efficiency.
KRaft—The Kafka ZooKeeper alternative
KRaft stands for Kafka Raft, a consensus protocol that removed Kafka’s dependency on ZooKeeper. In ZooKeeper, one controller from the Kafka cluster communicates with the leader. If the controller goes down, re-election takes some time, which impacts Kafka performance. In KRaft, the single controller in the broker cluster is replaced by a quorum of controllers to process requests. If any controller becomes unavailable, another can serve the request and manage the operations. This enhances Kafka's ability to withstand sudden failures.
The KRaft quorum controller ensures metadata is accurately replicated across the quorum. It uses an event-sourced storage model to keep the state accurate for recreation. The state is stored in an event log called the metadata topic. It is periodically trimmed with snapshots to prevent it from growing indefinitely.
Other controllers in the quorum follow the active controller by processing the events it records in the log. If a node is temporarily paused, it can quickly catch up on missed events from the log upon re-joining, significantly reducing downtime and improving system recovery time. Unlike ZooKeeper failures, where the complete data needs to be copied, in KRaft, only the missing or lagging events are copied.
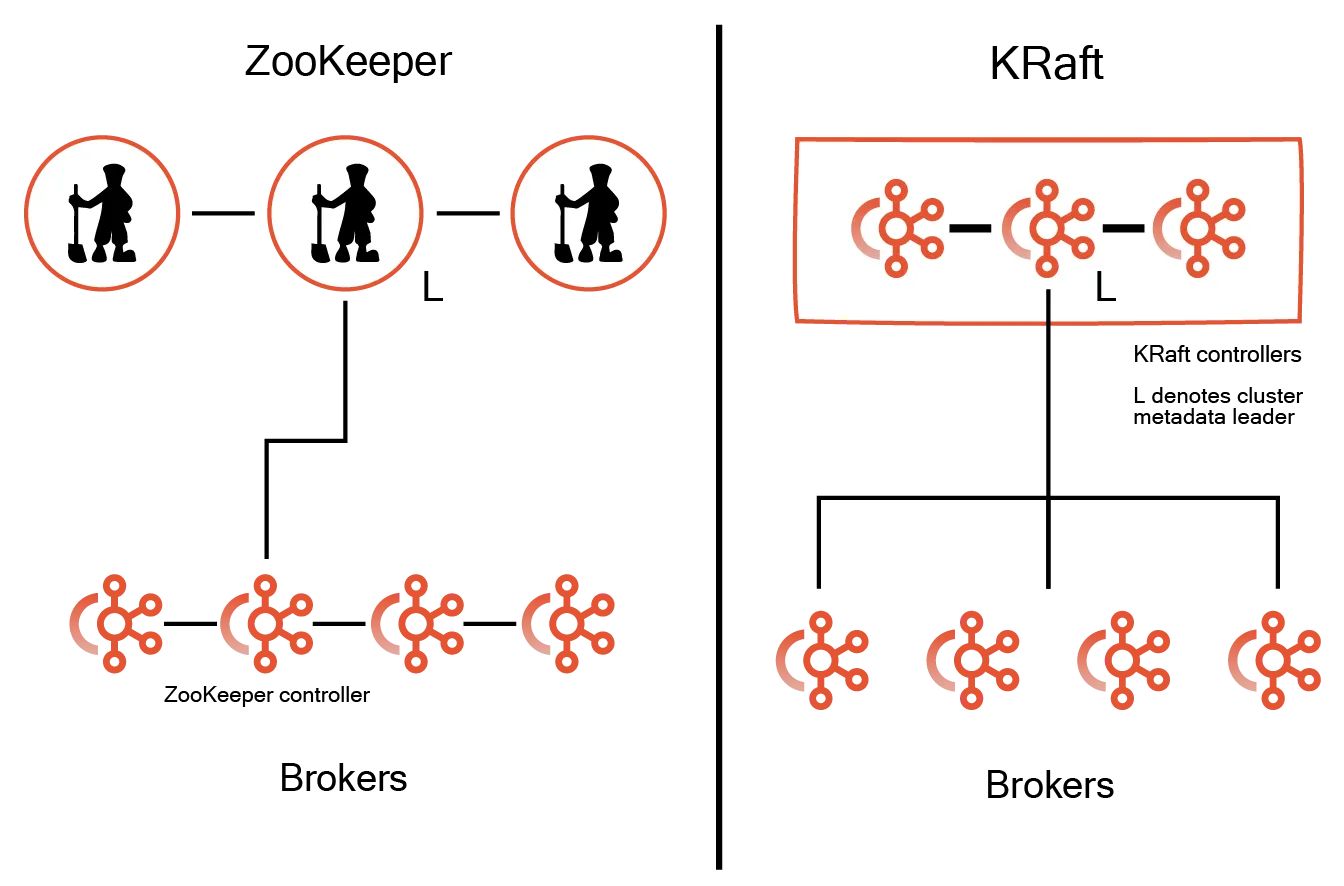
KRaft benefits
KRaft has less operation overhead and does not have a steep learning curve as it uses the same configuration parameters, security mechanisms, and failure scenarios as Kafka’s data plane.
Simplicity
In ZooKeeper, you need to maintain different configuration files for the ZooKeeper cluster and a separate configuration file for the Kafka cluster. In KRaft, a single configuration file manages everything.
Scalability
In KRaft, only the controller quorum has access to the metadata, and all other servers communicate with the controller quorum. This reduces the extra requests to the metadata store, thus allowing Kafka to handle more servers and topics.
Performance
With KRaft there is no need to manage an extra ZooKeeper cluster, this reduces the operation complexity. This streamlines Kafka deployment and maintenance, improving overall system performance by reducing overhead and potential points of failure.
Conclusion
While ZooKeeper was crucial in maintaining coordination and consistency in Kafka, its limitations and single-point-of-failure risks gave way to KRaft. Kafka with KRaft has also become outdated and can no longer meet the high-performance and scalability needs of enterprise-level applications.
Redpanda is a modern, drop-in Kafka alternative designed to handle large-scale data streams efficiently. It’s compatible with Kafka APIs but eliminates Kafka complexity. Redpanda is written in C++ and is lighter than Kafka, which depends on the JVM (Java) to run.
Redpanda offers:
- Cloud-native, cost-effective deployment
- Built-in intelligent cluster and partition management
- Standalone binary without ZooKeeper cluster or KRaft consensus plane.
Moving from older versions of Kafka to Redpanda is straightforward and significantly reduces operational costs, even while boosting performance. Check our blog post on migrating from ZooKeeper to KRaft to help you decide whether it makes more sense to migrate to Redpanda instead.