

Kafka cluster architecture—An in-depth guide for data engineers











Kafka cluster
Kafka clusters are a group of interconnected Kafka brokers that work together to manage the data streams entering and leaving a Kafka system. Each broker operates as an independent process on a distinct machine, communicating with other brokers via a reliable and high-speed network.
So the question is, why use Apache Kafka® clusters, and how do they help?
As user activity increases, so does the need for additional Kafka brokers to cope with the volume and velocity of the incoming data streams. Kafka clusters enable the replication of data partitions across multiple brokers, ensuring high availability even in the case of node failures. Your data pipeline remains robust and responsive to fluctuating demand.
This chapter explores how your organization can set up Kafka clusters to meet your needs. We recommend brushing up on the Kafka broker and Kafka partition chapters, if you haven’t already.
Summary of key Kafka cluster concepts
Kafka cluster architecture
At the very core of the Kafka cluster are its brokers, the fundamental units responsible for storing and managing data streams. Each broker receives a specific data partition, which it stores and serves upon request. The data partition ensures proper distribution and reduces the chances of redundancy. Moreover, as the data increases, more brokers can be added to increase scalability.
Metadata is another essential component in the operation of Kafka clusters. It provides information about topics, brokers, partitions, consumer groups, and their communication. The metadata enables Kafka to make effective decisions regarding the distribution, replication, and consumption of data streams.
Traditionally, metadata was stored separately, but Apache Kafka Raft (KRaft) presents an alternative approach. It simplifies the architecture by integrating metadata coordination directly into the Kafka brokers, eliminating the need for a separate ZooKeeper ensemble. This way, organizations can streamline the architecture, reduce operational overhead, and achieve greater efficiency.
There are two main types of cluster architecture. Let's discuss them individually and then explore their challenges and benefits.
Single Kafka cluster
As the name suggests, it is a single Kafka cluster with centralized management.
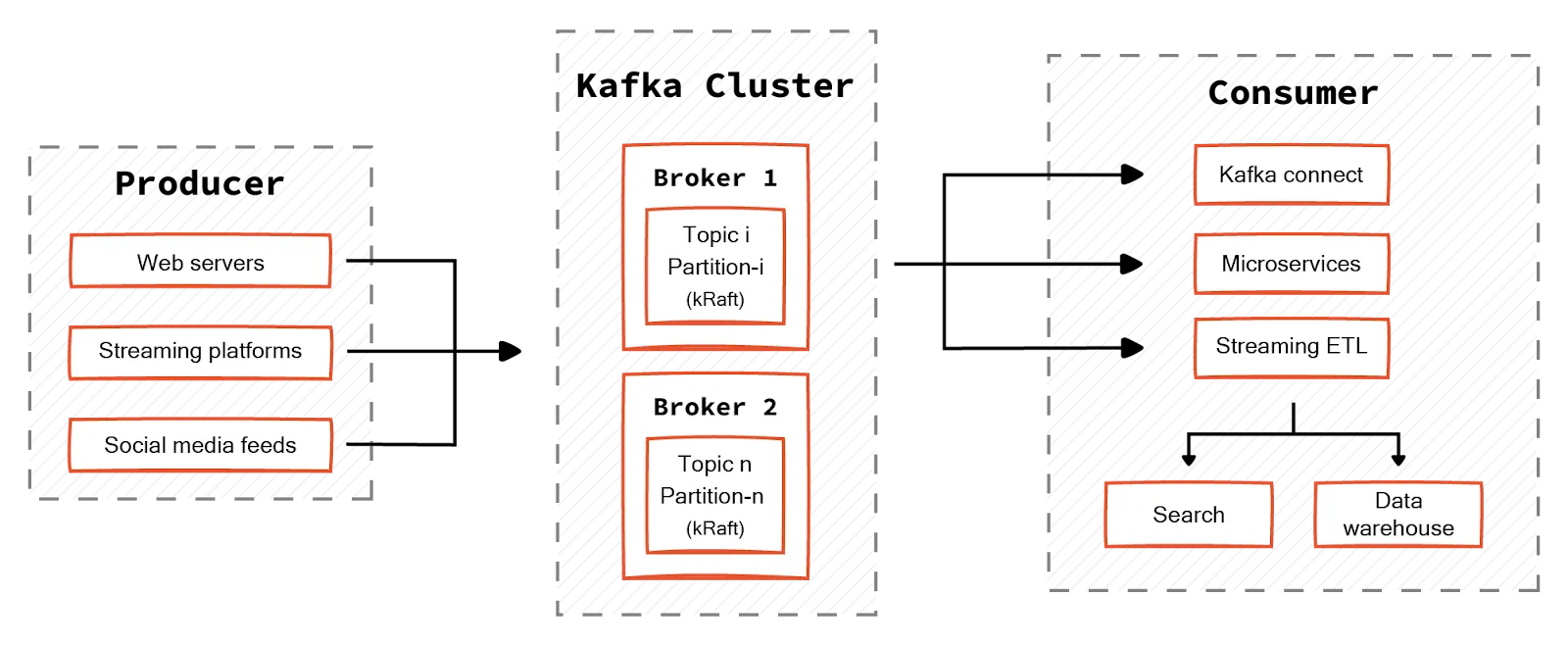
A single Kafka cluster has the same underlying infrastructure as a simpler Kafka setup with identical components and principles. As shown in the above diagram, a single Kafka cluster allows you to deploy all components under a single unit. This includes:
- All the brokers responsible for storing and serving data.
- All the metadata management through the KRaft protocol, and
- The topics partitioned and replicated across these brokers.
Client applications can interact with these brokers to produce and consume messages as required.
Multiple Kafka clusters
A multiple Kafka cluster setup is a decentralized approach involving separate clusters for different workloads. Workload segregation reduces interference between multiple resources and mitigates deadlocks. You can scale each Kafka cluster independently based on workload demands.
There are multiple models for multi-Kafka cluster deployment.
Stretched cluster
A stretched cluster is a single logical cluster stretched over multiple geological locations. Developers distribute replicas of the cluster evenly across the data centers, increasing redundancy and fault tolerance in the face of failure.
Active-active cluster
An active-active cluster is the preferred model, allowing two homogeneous clusters to have bi-directional, asynchronous mirroring. This mirroring is established through a MirrorMaker that uses a Kafka consumer to read messages from the source cluster. This consumer republishes them to the target cluster through an embedded Kafka producer.
This model is the most used as the client application does not have to wait until the mirroring completes across multiple clusters. Although there will be distinct Kafka producers and consumers on each cluster, the data from both clusters will be available on each cluster due to the mirroring process.
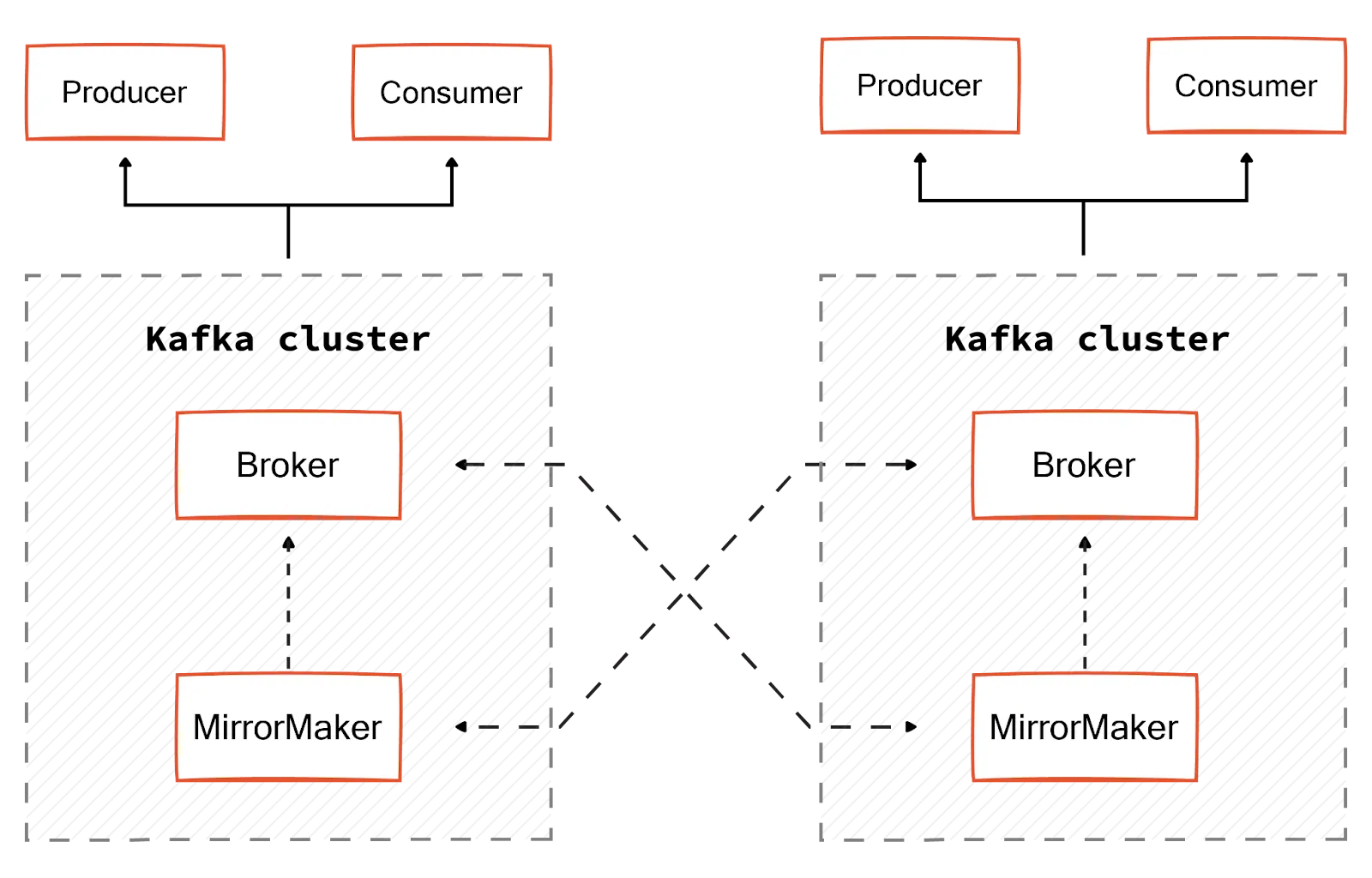
Active-passive cluster
An active-passive cluster allows two clusters to have unidirectional mirroring, i.e., data is replicated from an active to a passive cluster. If an active cluster fails, the client application must switch to the passive cluster. However, if the replication lag is high, the passive cluster can be a few offsets behind the active cluster. So, the client applications may experience inconsistency if the active cluster goes down. It could be the disadvantage here.
Choosing the right Kafka cluster architectures
Choosing between single and multiple Kafka cluster architectures depends on your organization’s needs.
Setup complexity
A single cluster architecture streamlines data management. It acts as a centralized hub for all the incoming and outgoing data, reducing the complexity of data architecture. Fewer complex processes and simpler configurations accelerate the deployment process. It is also relatively easier for newer team members to learn and implement.
Conversely, multiple Kafka clusters can increase complexity in setup, configuration, and maintenance. This is due to inter-cluster mirroring and communication, which adds overheads.
Fault tolerance
Failures can propagate across the entire system in a single Kafka cluster, affecting data availability. Moreover, it is challenging to identify and isolate these faults, resulting in extensive downtime.
Instead, a multi-cluster deployment is preferred for improved fault tolerance as it isolates data streams. Failure in one cluster does not affect the others, and the replication across multiple clusters also prevents data loss. Moreover, automated failover mechanisms for multi-Kafka clusters can reroute data streams to unaffected nodes. We will discuss them in a later section.
Scalability and performance
A single Kafka cluster faces performance bottlenecks due to the lack of workload segregation. Moreover, all the data streams compete for shared resources, which can lead to deadlocks. Hardware constraints ultimately limit scalability. As the cluster grows beyond these limitations, significant upgrades may be required, hindering further expansion.
In contrast, segregating data streams into multiple Kafka clusters enables better isolation of workloads. You can dedicate resources and configurations tailored to specific use cases. Workload segregation reduces interference between multiple resources, improving overall performance and reliability. Organizations can scale each cluster independently according to specific workload requirements. You get granular resource allocation and optimization for optimal performance.
Integrity
Fault tolerance and scalability have to be balanced with data integrity. In a multi-cluster setup, replication can create consistency and synchronization issues. If the replication lag is high, the passive cluster can be a few offsets behind the active cluster. A small mistake in the mirroring process can threaten the data integrity and coherence of the whole system. This is not an issue with a single setup.
Cost
Due to resource duplication and overheads, multicluster costs, such as operational, infrastructure, and software licensing costs, increase. A simplified single architecture is better with less complex data streaming requirements. By efficiently using available resources, you can optimize infrastructure costs and streamline operational expenses.
Deployment and setup of Kafka cluster
Deploying, setting up, and managing Kafka clusters involves getting them up and running smoothly and ensuring they continue to operate effectively. It's like building and maintaining a strong foundation for handling real-time data streams. Let’s explore these concepts one by one.
Comparing Kafka cluster deployment environments
There are three main ways of deploying your Kafka cluster.
On-premise deployments
On-premise deployments involve hosting Kafka clusters on dedicated hardware within the organization's data center. This way, the organization can fully control its hardware resources, network configurations, and security policies. Moreover, it allows organizations to customize their environment to specific requirements.
Companies with data privacy concerns should opt for on-premise deployment for greater security and control. However, on-premise deployments require upfront investment in hardware, infrastructure, maintenance, and troubleshooting.
Cloud-based deployments
You can host your Kafka brokers in the cloud. Cloud-based deployment offers scalability and flexibility, i.e., you can scale resources as needed and pay for them accordingly.
Amazon MSK is a fully managed service that runs Kafka in the cloud. Similarly, Redpanda Cloud is a fully managed, serverless Kafka alternative that provides high-performance, scalable messaging without the operational overhead of managing infrastructure. Redpanda Cloud simplifies deployment and management by offering features such as autoscaling and seamless integration with any cloud-native environment. We are preparing a comprehensive guide on Kafka Cloud where you can learn in-depth tips and tricks for maximizing the benefits of cloud-native Kafka solutions. Stay tuned!
Kubernetes deployments
K8s deployments provide a containerized environment for Kafka clusters to ensure proper resource utilization. You can streamline management across hybrid and multi-cloud environments.
Setting up a Kafka Cluster
Make sure you have the following prerequisites:
- You must have a basic knowledge of distributed systems concepts.
- You must have access to a Unix-like operating system (e.g., Linux or macOS).
The code example below is given in Python, so we assume background knowledge of Python for this guide.
Install Kafka
You will need to download and install the latest version of Kafka. Once installed, extract the downloaded archive and set up environment variables to streamline the execution of Kafka commands. Let’s write some bash commands for this purpose.
tar -xzf kafka_<version>.tgz
export KRAFT_HOME=/path/to/kafka
export PATH=$PATH:$KRAFT_HOME/binCode explanation:
- Untar a compressed Kafka file, essentially extracting its contents.
- Set an environment variable named KRAFT_HOME to the path where Kafka is extracted for easy access to Kafka's files and directories.
- Append Kafka's binary directory to the system's PATH variable so users can run Kafka commands from any location in the terminal without having to specify the full path each time.
Configure Kafka environment
Next, you must launch the Kafka environment by starting Kraft using a provided configuration file. Then, configure Kafka brokers by opening separate terminals with custom settings for each broker.
kraft-server-start.sh config/kraft.properties
kraft-broker-start.sh config/broker1.properties
kraft-broker-start.sh config/broker2.propertiesVerify the Kafka cluster
You must then confirm the operational status of the Kafka cluster by checking the status of brokers and topics.
The command below displays details about the brokers currently active in the Kafka cluster, including their IDs, hostnames, and port numbers. Additionally, it shows information about each broker's supported API versions, such as supported features and compatibility.
kafka-broker-api-versions.sh --bootstrap-server localhost:9092The command below lists all the topics currently available in the Kafka cluster. Each topic will include details such as the topic name, number of partitions, replication factor, and any custom configurations set for the topic.
kafka-topics.sh --list --bootstrap-server localhost:9092Create topics
You can organize data within Kafka using the kafka-topics.sh utility. You can then define the number of partitions and replication factors based on workload requirements.
kafka-topics.sh --create --topic test_topic --bootstrap-server localhost:9092 --replication-factor 3 --partitions 3Set up producers and consumers
Next, you set up Kafka producers to generate events (messages) and send them to designated topics. In our case, its “test_topic”
from kafka import KafkaProducer
from time import sleep
producer = KafkaProducer(bootstrap_servers='localhost:9092')
topic = 'test_topic'
messages = ['This is message 1', 'This is message 2', 'This is message 3']
for message in messages:
producer.send(topic, value=message.encode())
sleep(1)The Kafka consumer below receives the “test_topic”.
from kafka import KafkaConsumer
consumer = KafkaConsumer('test_topic', bootstrap_servers='localhost:9092')
for message in consumer:
print(f"Received message: {message.value.decode()}")You have now successfully set up your own Kafka cluster.
Kafka cluster management
You must configure your Kafka cluster correctly to maintain consistency, health, and performance. Consider using tools like Ansible, Chef, or Puppet for automated cluster provisioning, configuration, and scaling.
Another important factor is to have failover strategies for disaster recovery to ensure that clusters have high availability and that data is secure. Let’s discuss some of them:
Cross-region replication
You should implement cross-region replication of Kafka clusters across multiple geographical locations. This way, the system can easily failover to a secondary location in case of a disaster in the primary location, ensuring data availability and business continuity.
Hot standby clusters
You should also maintain hot standby clusters ready to take over all operations in case of a primary cluster failure. These clusters are synchronized with the primary cluster in real time to minimize data loss during the failure.
Automated monitoring
Consider a scenario of a large e-commerce platform built on Kafka clusters for real-time data processing. A peak in workloads leads to unexpected delays in processing critical orders. However, the operations team proactively monitors and identifies a misconfigured consumer group causing processing delays. They promptly reconfigure the consumer group, thereby resolving the issue and ensuring order processing again.
Monitoring Kafka cluster metrics thus provides you with important information related to the health and performance of your data pipelines. Organizations can preemptively identify and mitigate issues. You should track metrics like:
- Disk I/O, network throughput, and memory utilization of each broker.
- Message throughput, partition lag, and replication status of specific topics within the cluster.
- Consumer lag, offset commit rate, and consumer group activity
Cluster-wide metrics, such as overall throughput, latency, and error rates, also offer a holistic view of the cluster's performance and health.
Regular disaster recovery testing
Like any software testing, regular disaster recovery testing exercises are essential to validate the effectiveness of failover strategies and procedures. To gauge the resilience of your Kafka deployment, you simulate various failover scenarios, including hardware failures, network partitions, and data center outages.
These failover strategies for disaster recovery can allow high availability and fault tolerance in the face of failures.
Kafka cluster challenges
Organizations report performance bottlenecks, frequent outages, and slow MTTR as clusters scale.
Scaling challenges
As your Kafka clusters scale, maintaining data transmission speeds and near-zero downtime requires constant monitoring and low-level reconfiguration. This can create a significant operational burden on your team.
For example, adding a new Kafka broker to a cluster using default settings can slow down your cluster’s overall performance. By default, the broker is set to have only a single partition per topic but consumes RAM. Minimizing partitions preserves server memory but constricts your streaming ceiling. To maximize throughput, the number of partitions should be balanced with the number of consumers accessing it, which can be tens or even hundreds more per broker.
Similarly, for fault tolerance, a new broker by default replicates the partition and topic data from existing brokers. This process can take a long time and use significant compute and network I/O resources as your partitions increase. This can cause a massive temporary slowdown and may also result in lost data due to system bottlenecks.
Optimization challenges
Due to configuration complexity, it is challenging to get your Kafka cluster right in one go. Clusters can also become less optimized over time. For example, more partitions boost topic—consumer throughput but also increase the chances of a broker server failure. If you increase the maximum CPU usage for a broker, you can save on costs, but experience increased end-to-end latency. This can increase the risk of archived data expiring before it is sent.
Solution
Redpanda is a built-in Kafka replacement with a human-friendly CLI and a rich UI that simplifies working with real-time data at scale. It can achieve up to 10x lower latencies and 6x total cost reduction without sacrificing data safety. With Redpanda Serverless, there’s no infrastructure to deploy or systems to configure. You can instantly create clusters at the click of a button and experience predictable performance that scales automatically.
Conclusion
While Kafka was an innovative technology when it first came out, it no longer meets modern organizations' needs. Kafka clusters become resource-intensive to manage at scale and do not meet today's data streaming requirements. Instead of trying to compromise between cost and performance as your Kafka clusters scale, you can choose more flexible and pocket-friendly alternatives like Redpanda.