

Kafka producer—a deep dive











Kafka producer
When processing data using Apache Kafka’s architecture, components connected to Kafka are producers or consumers.
Producers store messages (or events) in Kafka, and consumers read these messages.
An event or message typically contains data representing an action or change that occurred in a system. You can find Kafka with producers and consumers in software that generates messages, integration adapters for other products, and custom event-producing applications.
This chapter explores Kafka producers, including their configuration, what Kafka messages look like, how to test and optimize throughput, and some security options you can use.
Summary of key Kafka producer concepts
We cover the following key concepts in this article:
What is a Kafka producer?
Kafka producers are the client applications that publish messages to Kafka topics using the Kafka producer API.
A Kafka message has the following components:
- A message, which can be anything, is serialized into a byte array.
- A message Key determines the partition to which to write.
- The producer typically assigns a message timestamp (optional).
- A compression type (optional) is used to reduce message size.
- Headers (optional) containing additional metadata.
- The broker adds partition and offset ID on receipt of the message.
The Kafka producer is responsible for creating messages of the appropriate structure and sending them using the Kafka protocol. It has several configuration options to control message creation and delivery.
Connecting your producer to Kafka
Producers initially connect to a Kafka bootstrap server(a subset of Kafka brokers) to discover the list of Kafka broker addresses and the current leaders for each topic partition. This is done by the producer sending a MetaDataRequest to the broker first. Messages include information about the target topic and partition in addition to the actual message.
A producer sends messages directly to the leader broker for the relevant topic partition using a proprietary protocol with TCP as the transport mechanism. This enables message processing to scale while maintaining message order within the partition.
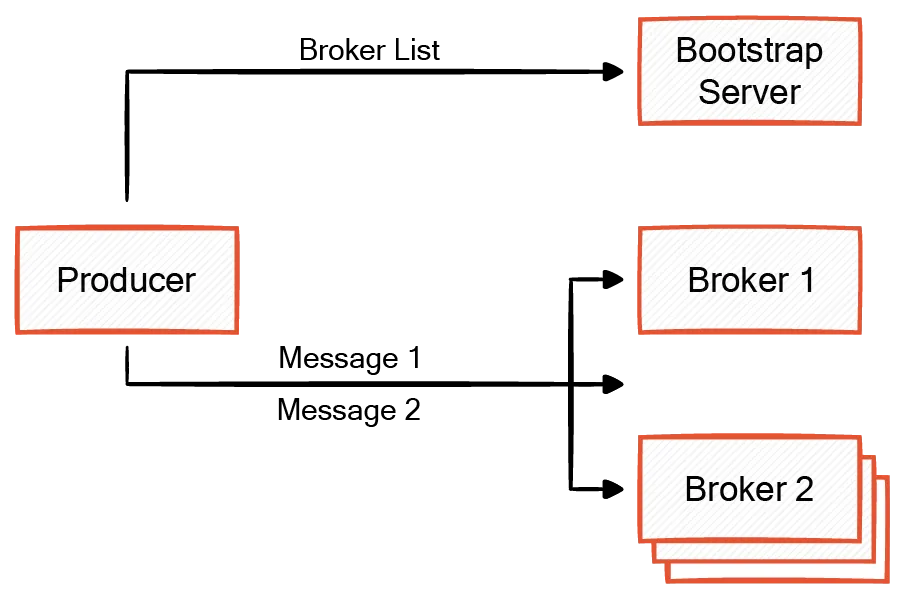
This process all happens under the covers when creating the Kafka producer in a programming language like Python:
from kafka import KafkaProducer
producer = KafkaProducer(bootstrap_servers='localhost:9092')Message serialization in Kafka producer
Kafka is agnostic about message content and does not attempt to know anything more structured than a stream of bytes. Therefore, you must use an appropriate serializer function to convert each message to a byte array before you send it to Kafka.
The following example code creates a producer with a JSON serializer.
producer = KafkaProducer(value_serializer=lambda v: JSON.dumps(v).encode(' utf-8'))Messages from this producer are converted from JSON to byte array format before being sent.
You can then send a message as follows:
producer.send('test-topic', key='key1', value='{"value": "value1"}')You also need to provide Message keys in byte array format. If the keys have a complex structure like JSON, they will similarly require a serializer.
Message keys and partitioning
Kafka increases scalability and performance by writing messages concurrently to multiple partitions, which often involves communicating with partition leaders on different brokers. However, the performance and scalability benefits come at the cost of sacrificing message ordering.
Messages are only guaranteed to be in order within the same partition, so it is essential to ensure that each message has an appropriate message key representing the entity that requires ordered messaging. The key could be, for example, an account number or IoT device ID. The producer partitioner determines the correct partition to send the message to by hashing the message key and mapping it to the designated partition.
If you don't provide a message key, the producer sends messages using a round-robin or sticky partitioning strategy. The round-robin strategy cycles through partitions in order. Sticky partitioning attempts to batch messages to a single partition until a trigger, such as time or batch size, causes a switch to another partition.
You can get the detailed configuration of a topic using:
docker exec -it kafka kafka-topics --describe --topic test-topic --bootstrap-server localhost:9092Durability and error handling
Kafka makes several settings available so producers can balance message durability vs performance.
Acks
The acks setting controls how many brokers must acknowledge receipt of the message before the producer considers it sent.
With acks=all, all partition replicas must have received the message before sending is complete. This number can be reduced to acks=0, so the producer continues sending other messages before Kafka propagates all copies of the current message.
You can set the acks configuration when creating the producer as follows:
producer = KafkaProducer(bootstrap_servers='localhost:19092, acks='all')Some broker-side settings are also relevant to this, including:
replication.factor: The number of replicated copies required for a topicmin.insync.replicas: The minimum number of replicas needed when the acks=all setting is applied.
If the producer cannot write this many copies of the data, it receives an error, thereby preventing data loss but potentially impacting availability.
You can set topic parameters as follows for Kafka:
docker exec -it kafka kafka-configs --bootstrap-server localhost:9092 --entity-type topics --entity-name your-topic-name --alter --add-config min.insync.replicas=2Delivery settings
The producer settings for message delivery are:
retriessetting controls how many attempts the producer makes to send a failed message.retry.backoff.mssetting controls how long it waits before re-attempting the resend.delivery.timeout.mssetting controls the maximum time the producer will wait for an acknowledgment.
You can send messages in batches as transactions by setting a transaction ID and then committing or aborting the transaction after sending messages.
All settings can be applied when creating the producer in the same way as for acks.
Testing your Kafka producer
To create a test environment for your Kafka producer, you can use docker-compose to run Apache ZooKeeper™ and Kafka services. The necessary ports are exposed locally for your producer applications to connect.
- The Zookeeper service is accessible on localhost port 2181. Zookeeper manages the cluster metadata and coordinates distributed processes.
- The Kafka service is accessible on localhost port 9092. This is the port your producer applications will use to connect to the Kafka broker to send messages.
Steps
Ensure you have Docker and Docker Compose installed on your machine, then create the following docker-compose.yaml file:
version: '2'
services:
zookeeper:
image: quay.io/strimzi/kafka:0.39.0-kafka-3.6.1
command: [
"sh", "-c",
"bin/zookeeper-server-start.sh config/zookeeper.properties"
]
ports:
- "2181:2181"
environment:
LOG_DIR: /tmp/logs
kafka:
image: quay.io/strimzi/kafka:0.39.0-kafka-3.6.1
command: [
"sh", "-c",
"bin/kafka-server-start.sh config/server.properties --override listeners=$${KAFKA_LISTENERS} --override advertised.listeners=$${KAFKA_ADVERTISED_LISTENERS} --override zookeeper.connect=$${KAFKA_ZOOKEEPER_CONNECT}"
]
depends_on:
- zookeeper
ports:
- "9092:9092"
environment:
LOG_DIR: "/tmp/logs"
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://localhost:9092
KAFKA_LISTENERS: PLAINTEXT://0.0.0.0:9092
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181Start the services using the command docker-compose up -d
You can then send messages to Kafka using, for example:
echo "hello" | kafka-console-producer.sh --broker-list localhost:9092 --topic test-topicSecurity and performance
Kafka security covers SSL/TLS encryption for data in transit, SASL for authentication, and ACLs for authorized access to topics. Your producer will need the relevant configuration to match the broker encryption settings, and you will need to supply the appropriate credentials to access the relevant topics.
You can measure the performance of your Kafka producer in terms of throughput, latency, and resource utilization. The most significant settings for controlling this are the batch.size and linger.ms settings.
- Batch Size is the maximum size (in bytes) of a batch of messages sent to a partition. Increasing batch size can improve throughput but negatively affect producer memory requirements and latency.
- Linger Time is the maximum amount of time in milliseconds to buffer data before sending a batch of messages to the broker. A higher linger time can result in higher batch size and increased throughput at the cost of higher latency.
Kafka also provides built-in metrics that can give insights into the producer's performance and health, including throughput, latency, buffer availability, and error rates.
print(producer.metrics())Through benchmarking, identifying bottlenecks, and iterative batch and linger settings adjustment, you can optimize the producer for your use case's requirements.
Improving performance
Redpanda is an API-compatible replacement for Kafka that is up to 10x faster, 6x more cost-effective, and significantly easier for developers. It consolidates the Kafka broker, schema registry, and an easy-to-use administration UI, making producer management much more convenient. Replacing Kafka with Redpanda is simple, requires no code changes, and instantly improves the performance and management of your streaming data use cases.
You can also download Redpanda Console, a free Kafka web UI for developers that provides a simple, interactive approach to gaining visibility into your topics and exploring real-time data with time-travel debugging. It is an excellent way to monitor and improve your Kafka producer's performance and makes similar metrics more accessible.
Conclusion
Although the basics of producing messages in Kafka are relatively easy to understand, the inherent complexities of deploying Kafka can make development and testing difficult.
Using Redpanda for the development, testing, and performance tuning of Kafka producers can bring a significant advantage to the developer. It allows rapid configuration of a test environment. You can apply appropriate monitoring, configure the system with proper serialization settings, and achieve optimum performance. To get started with Redpanda, sign up for a free trial.