

Kafka consumer group—a deep dive











Kafka consumer group
Apache Kafka® is an open-source, publish-subscribe messaging system that scales through distribution and partitioning. It focuses on persistent messaging and message replication to prevent data loss. It provides solutions to the challenges of consuming real-time and batch data volumes.
As covered in Chapter 1 of this guide, you can categorize Kafka messages into topics. A topic is like a folder in Kafka that stores messages in the order they are produced. In a system that uses Kafka, producers write messages to Kafka topics, and consumers read messages from topics.
This chapter explores Kafka consumers and consumer groups and examines their functioning, coordination, and benefits.
Summary of key Kafka consumer group concepts
What are Kafka consumer groups?
Kafka consumers can work as part of a consumer group, where one or more consumers consume from the same topic. They read a single message stream without interfering with each other. But why are consumer groups necessary?
Need for consumer groups
Scalability is an essential aspect of Kafka’s design. To facilitate scale, Kafka topics can have multiple producers write events and multiple consumers subscribe to those events.
Consider a client application reading messages from a Kafka topic. The application creates a consumer object, subscribes to the appropriate topic, and starts receiving messages. It validates the messages and then stores them.
However, if multiple producers write messages to the topic at an accelerated rate, the consumer object cannot process them fast enough. The client application cannot cope with the increased rate of incoming messages. It becomes necessary to scale topic consumption by introducing additional consumers, which is where consumer groups come in.
A consumer group allows multiple consumers to read from the same topic, dividing the partitions between them. The messages are distributed among the consumer group members so that only one consumer consumes each message. This distributed arrangement of data is crucial for scalability, enabling consumers to read from numerous events concurrently.
How does a Kafka consumer group work?
Kafka topics are subdivided into ordered partitions. Whenever a producer writes a new event to a topic, it is appended to the end of a partition. Members of the same consumer group receive messages from a different subset of topic partitions.
In fact, each partition is consumed by exactly one consumer within the group. The consumer group manages the distribution of messages or partitions among the consumers by self-balancing the partitions. Let’s explore different scenarios to understand this further.
More partitions than consumers
When the number of partitions in a Kafka topic is less than the number of consumers in the consumer group, then all the partitions are self-balanced among the consumers. Each consumer gets a subset of the partitions, ensuring that the partitions distribute evenly among them.
For example, there is a web application that handles user requests and logs them to a Kafka topic with four partitions and a consumer group with two consumers to process the request. Then, each consumer gets two different partitions. This way, no single consumer has to handle all the requests, and the system is highly available.
Partitions equal to consumers
When the number of partitions in a Kafka topic equals the number of consumers in a consumer group, then every consumer gets one partition.

For example, let's say there is an e-commerce platform with consumers grouped by region. The Kafka topic is partitioned into four partitions corresponding to these regions. In this setup, each consumer is assigned to a single partition and consumes all orders or requests from a specific region. Self-balancing is unnecessary, and message processing is more efficient.
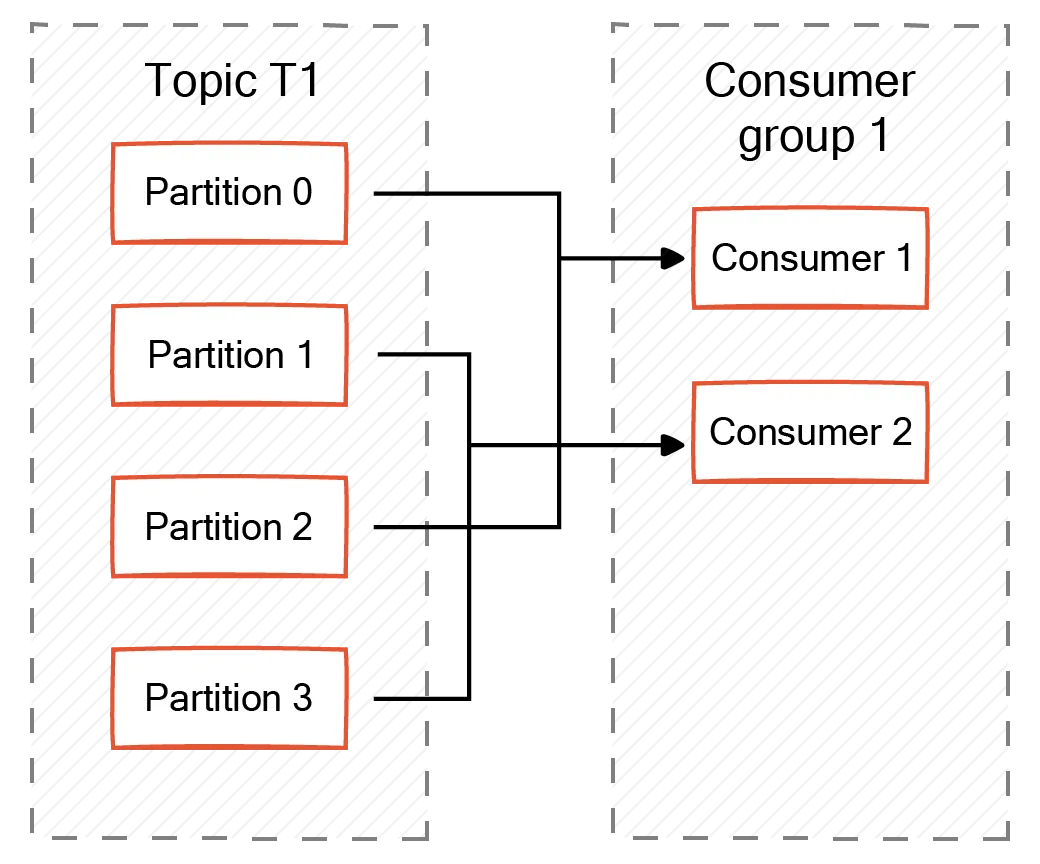
Partitions less than consumers
When the number of partitions in a Kafka topic is less than the number of consumers in a consumer group, a consumer always sits idle and consumes no messages. The idle consumer stays on standby and might be of help in case one of the consumers with partitions assigned fails. It is important to note that if a consumer fails, an available consumer automatically gets the partition, and there are no idle consumers.

For example, consider a company that provides customer support services and has five agents (consumers) grouped into a consumer group. A Kafka topic handles the incoming requests or calls. The topic has four partitions. Since the number of partitions is less than the number of consumers, there would be one agent who would be idle. This idle agent handles incoming requests only if an active agent experiences a failure or becomes unavailable. The customers won't experience any service disruption. The standby agent seamlessly takes over, resolving the customer's request immediately.
Multiple consumer groups
There might be more than one consumer group that consumes the same Kafka topic. Within a consumer group, each consumer consumes only from a single partition. In the case of multiple groups, several consumers can read messages from the same partition as long as they are from different groups.
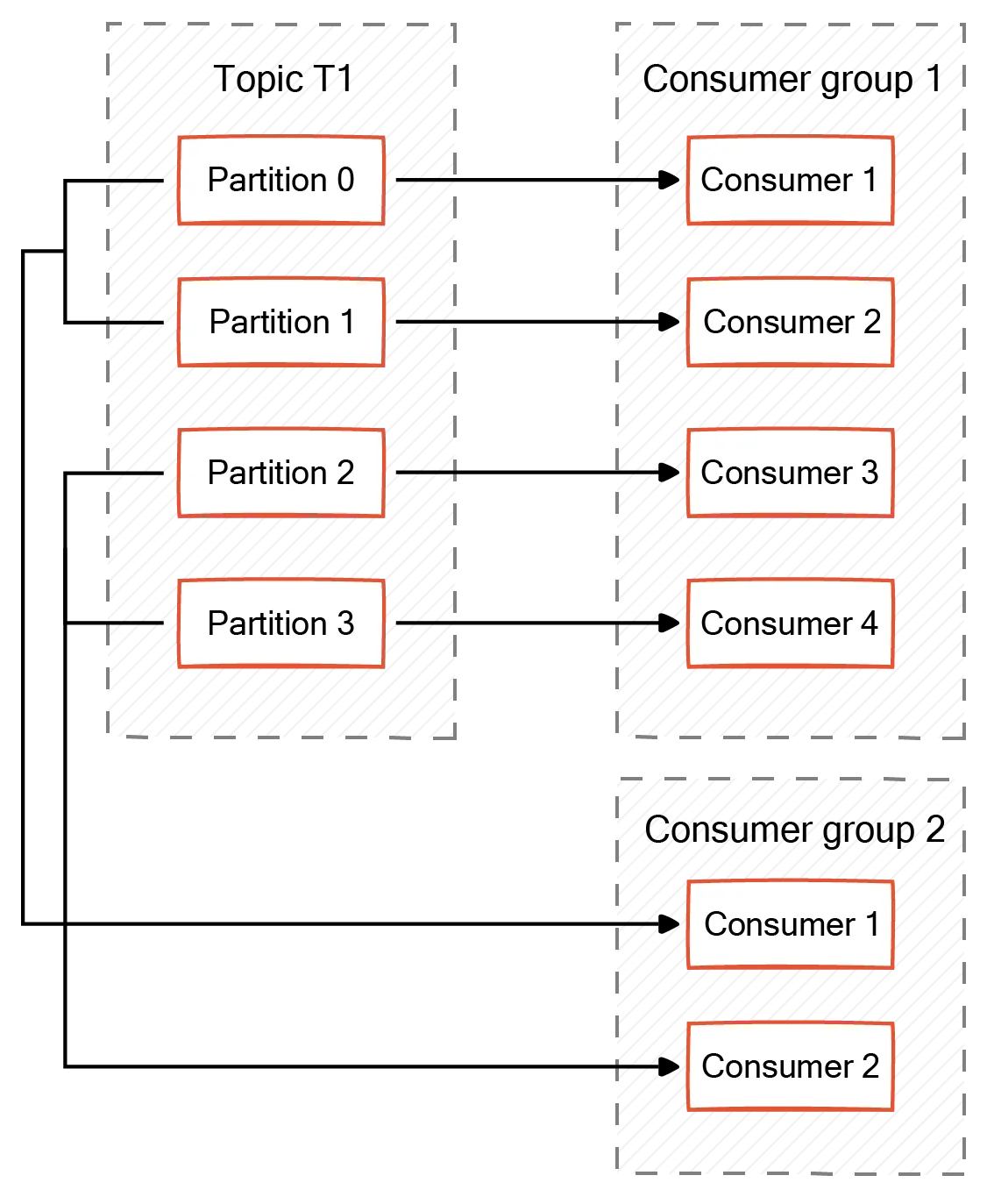
For example, let's say there is a social media platform that maintains a Kafka topic for a data stream that is partitioned based on posts and comments. Now, there are two consumer groups, one for real-time analytics and another to store data for historical analysis. Both groups can assign members to the same topic and consume messages from the same partitions. This facilitates resource optimization and ensures that both groups function autonomously without disrupting each other's operations.
How are partitions assigned within Kafka consumer groups?
A group coordinator facilitates the equal distribution of partitions among consumer group members even when there are changes in group membership. The group coordinator is part of the Kafka broker or Kafka server. It achieves partition assignment by utilizing an internal Kafka topic to maintain and manage group metadata.
Group coordinator functions
The group coordinator performs the following functions.
Assigning partitions
When a consumer joins or leaves a group, the group coordinator reassigns partitions among the remaining consumers using a rebalancing algorithm.
Heartbeat mechanism
The group coordinator monitors consumer status by receiving periodic signals from them called heartbeats. As long as the consumer sends heartbeats regularly, it is assumed to be online.
Suppose a consumer fails to send a heartbeat within a specified timeout period. In that case, the group coordinator marks it as inactive and triggers a rebalance to reassign its partitions to other active consumers in the group. You can learn more about managing Kafka consumer delays in our guide on Kafka consumer lag.
Tracking message consumption
The group coordinator keeps track of the messages that the consumer group has consumed. A native feature, the "consumer offset," is the distinctive identifier for every message the group consumes. The group coordinator stores consumer offsets in an internal topic called __consumer_offsets.
If a consumer restarts or experiences temporary failure, it requests the group coordinator to retrieve its last committed offset and resume consumption from that point. The consumer group thus maintains a consistent view of the data and avoids processing duplicate messages.
Partition assignment strategy
The group coordinator uses a partition assignment strategy to assign partitions to consumers in the Kafka consumer group. The PartitionAssignor class acts as the decision-maker within the Kafka architecture. It takes information about consumers and their subscribed topics as input and then outputs a mapping that assigns specific partitions (message segments) to each consumer within the group.
Kafka has the following assignment strategies.
Range
In the Range partition, each consumer is allocated consecutive partitions from each topic it subscribes to. This means the first partition is assigned to the first consumer, the second to the second consumer, and so on. An uneven number of partitions in each topic can result in consumers becoming idle.
For instance, consider two consumers C1 and C2, subscribed to two topics, T1 and T2, with two partitions each. C1 is assigned partition one and C2 is assigned partition two from both topics.
Round robin
In round robin, all the partitions from all subscribed topics are taken and assigned to the consumers sequentially, one at a time. This results in fewer idle consumers. For instance, if there are two consumers, C1 and C2, and three partitions, then C1 is assigned to partition 0, C2 is assigned to partition 1, and the last remaining partition is assigned back to C1 as the round robin cycle repeats.

Creating Kafka consumer groups
The following code snippet shows how to create a KafkaConsumer and assign a consumer group using the group.id Kafka property.
Properties props = new Properties();
props.put("bootstrap.servers", "broker1:9092,broker2:9092");
props.put("group.id", "CountryCounter");
props.put("key.deserializer","org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer","org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(props);In the code above, the properties have the following purpose.
bootstrap.servers—One or more Kafka brokers to connect on the startup.group.id—A name that’s used to join a consumer group.key.deserializer—Needed for deserialization of the key.value.deserializer—Needed for deserialization of the value.
Best practices with Kafka consumer groups
Consumers should always consume what they can process efficiently. When the amount consumed surpasses what the consumer can handle, it comes to a standstill and is subsequently removed from the consumer group. That is why it is significant to consume into fixed-size buffers.
Some more tips:
- Use distributed consumer groups to facilitate horizontal scalability and resilience to faults.
- Keep track of the consumer group's performance using Kafka's integrated metrics or external monitoring tools.
- Maintain one consumer group per topic to prevent conflicts in consumer group memberships.
You can also use Redpanda Console, a Kafka web UI for developers to streamline the management of your Kafka consumer groups. Among many other functions, you can also easily monitor consumers and consumer lag and edit consumer group offsets.
Conclusion
Whether there are more, the same number, or fewer partitions than consumers, Kafka's flexibility allows developers to customize their approach as needed. The versatility of partition assignment strategies improves its ability to handle various types of workloads.
However, it is essential to note that in a time of high-performance, high-throughput, and low-latency applications, Kafka is no longer the streaming data superpower it once was. Companies now need a platform that supports real-time, mission-critical workloads without breaking the bank (or their ops team).
This is why more companies are choosing Redpanda, a source-available (BSL), Kafka-compatible streaming data platform designed to be lighter, faster, and simpler to operate. Redpanda consumer groups behave just like Kafka consumer groups but are much easier to configure and manage.
Want to take Redpanda for a free spin? Sign up here.