

Kafka log compaction—Configuration and troubleshooting











Kafka log compaction
Apache Kafka® log compaction is crucial for maintaining optimal performance, storage efficiency, and data consistency in Kafka-based systems. Log compaction ensures that the most current records are always available by periodically removing older, obsolete records. This process helps reduce the storage footprint of the Kafka cluster, mitigates the impact of log growth on performance and resource consumption, and guarantees that consumers consistently access the latest record state.
By managing size, Kafka log compaction plays a vital role in ensuring Kafka-based systems' stability, efficiency, and longevity. This article explores the log compaction process, key parameters you can configure, and ideas to troubleshoot common issues.
Summary of critical concepts in Kafka log compaction
| Section | Key Concepts |
|---|---|
| Kafka log storage and partitioning | Topics, partitions, logs, partitioning, and log segments |
| The need for log compaction | Log size growth, storage, and performance issues, maintaining recent record states |
| The log compaction process | Cleaner threads, log segment scanning, identification of obsolete records, and compacted log segments |
| Configuring log compaction | log.cleaner.enable, log.cleaner.min.cleanable.ratio, min.cleanable.dirty.ratio, and balancing performance |
| Monitoring and troubleshooting log compaction | Metrics, common issues, resolutions, and best practices for a healthy Kafka cluster |
| Conclusion | Importance of log compaction, optimizing log compaction for specific use cases |
Basics of Kafka log storage and partitioning
Kafka logs are not the traditional log files recording system events that you may have used elsewhere. Instead, Kafka logs are an internal data structure that holds immutable messages distributed across servers.
Users can name logs, and the named logs are called topics. Topics are further divided into partitions to enable parallelism and fault tolerance. Kafka assigns different offsets to records in a partition, indicating their log position. The following diagram represents the relationship between topics, partitions, and logs.

How partitioning works in Kafka
Partitioning is a technique that Kafka uses to distribute and parallelize data processing across multiple brokers in the cluster. When a producer writes a message to a topic, Kafka assigns the message to a specific partition based on a partitioning algorithm.
Each partition is replicated across multiple brokers to ensure fault tolerance, and one of the replicas is designated as the leader, while others serve as followers. Consumers read messages from the partitions, with each partition being consumed by a single consumer within a consumer group. A consumer group is a set of consumers working together to process messages from a topic, allowing for parallel processing and load balancing across multiple consumers. This parallelism improves data processing efficiency and ensures peak throughput in Kafka-based systems.
[CTA_MODULE]
The need for Kafka log compaction
Logs play a critical role in Kafka by providing a durable, fault-tolerant storage mechanism. They enable efficient data replication and recovery and serve as the foundation for Kafka's distributed and fault-tolerant architecture. Kafka log compaction addresses the following issues to improve Kafka performance.
Growing log size and storage issues
Log retention in Kafka is determined by two main parameters:
- retention.bytes - the maximum size of a log before old messages are removed
- retention.ms - the maximum time messages are stored before they are removed.
As Kafka continuously processes and stores messages, the size of logs grows over time. This growth can lead to storage issues, especially in cases where large amounts of data are being processed and the retention period is long. The growing log size eventually consumes all available storage resources if not managed effectively, leading to system instability or failure.
Resource consumption and performance issues
In addition to storage concerns, uncontrolled log growth negatively impacts a Kafka cluster's performance and resource consumption. As logs grow, it takes longer for consumers to read messages, affecting the overall data processing throughput. Additionally, larger logs require more system resources (such as memory and I/O) to maintain and manage, which strains the available resources in the cluster.
Ensuring the most recent state of records
In some Kafka use cases, the most recent state of a record is more important than preserving the entire history of changes. For example, in a system tracking user profiles, having the latest user information is more critical than retaining all previous profile updates. Therefore, log compaction ensures that the most current state of records is maintained by periodically removing older, obsolete records.
The Kafka log compaction process
In Kafka, log compaction is a background process that cleans logs by removing older records with the same key as newer ones. By doing so, the log retains only the most recent state of each record, reducing the storage footprint and ensuring the availability of the latest data. The following diagram illustrates the process.
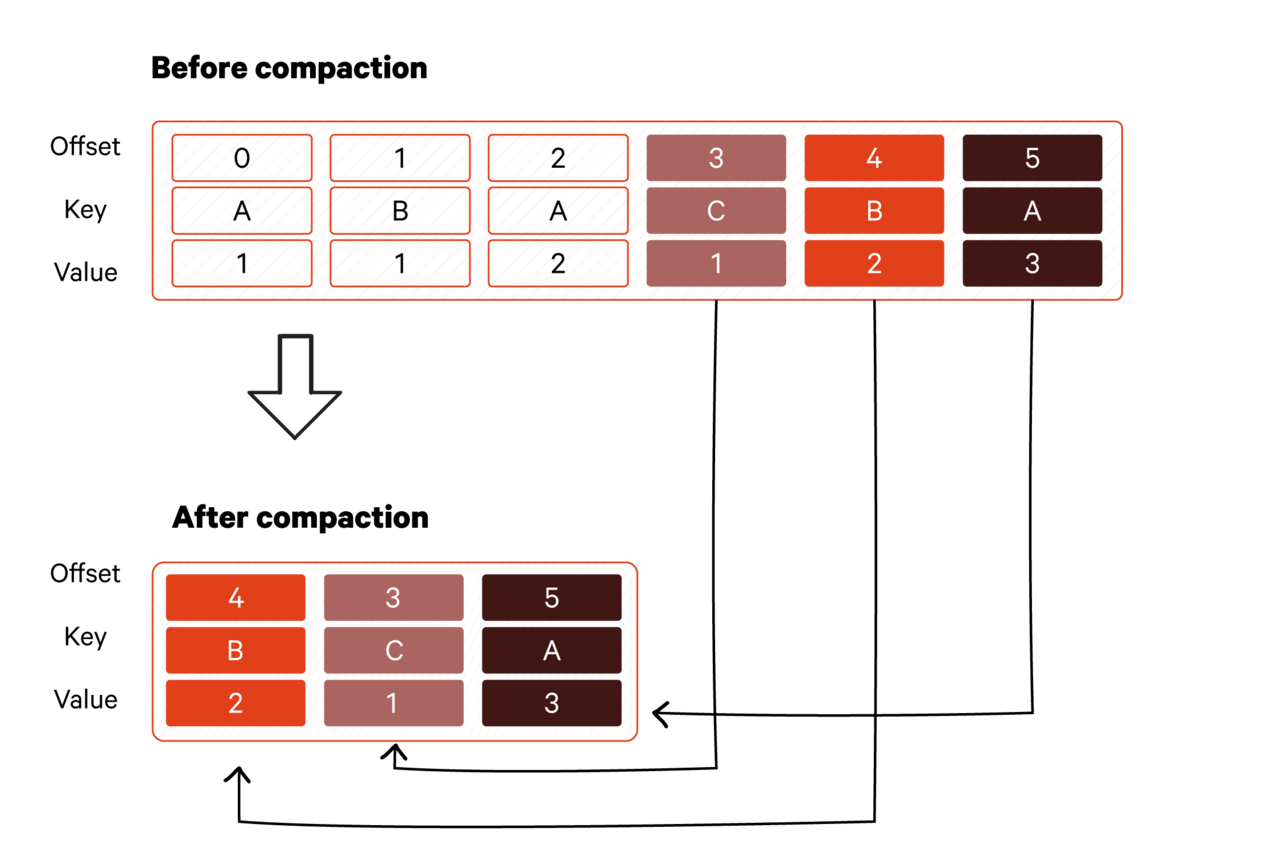
Log compaction is performed by cleaner threads running on Kafka brokers. These cleaner threads are responsible for scanning log segments, identifying obsolete records, and creating compacted segments without outdated records.
The flowchart explains the log cleaner's role in the Kafka log compaction process.

Configuring Kafka log compaction
To enable and customize the log compaction process in Apache Kafka, you need to configure the following parameters:
- log.cleanup.policy: This parameter determines the cleanup policy for log segments. To enable log compaction, this parameter should be set to ’compact’. The value ‘delete’ means that older log segments will be deleted after the specified retention period, while ’compact’ means that the log will be compacted. You can also use ‘compact, delete’ to do both.
- log.cleaner.enable: Set to 'true' to allow the log cleaner process.
- log.cleaner.min.cleanable.ratio: Determines the minimum ratio of "dirty" (uncleaned) bytes to total bytes in a log segment before it becomes a candidate for compaction.
- log.cleaner.backoff.ms: Specifies the delay between consecutive log cleaning attempts.
- min.cleanable.dirty.ratio: Controls the minimum percentage of dirty records in a log before it is considered for compaction.
- log.cleaner.delete.retention.ms: This controls the maximum amount of time that deleted record metadata is retained by the log cleaner. This allows consumers to access the final state of a record before it is permanently removed.
Balancing log compaction frequency and performance
Configuring log compaction involves finding the right balance between the frequency of log compaction and the impact on Kafka cluster performance. For example, aggressively compacting logs increases resource consumption and negatively affects performance. On the other hand, infrequent compaction results in larger logs and suboptimal storage utilization. Adjusting the configuration parameters above helps find the right balance for your use case.
Recommended settings for various use cases
The optimal Kafka log compaction settings depend on your specific use case and requirements. For example:
- In systems where the most current state of records is of utmost importance, you may want to configure a lower min.cleanable.dirty.ratio and log.cleaner.min.cleanable.ratio to trigger log compaction more frequently.
- In scenarios with less stringent storage requirements or less frequent updates to records, you may opt for higher values for min.cleanable.dirty.ratio and log.cleaner.min.cleanable.ratio to reduce the impact of log compaction on system performance.
[CTA_MODULE]
Monitoring and troubleshooting Kafka log compaction
To effectively manage and optimize log compaction, you should monitor key Kafka metrics, such as:
- Log cleaner I/O ratio
- Log cleaner backlog
- Log cleaner working time
These metrics provide insights into the efficiency of the log compaction process and help you detect potential issues before they impact system performance.
Common challenges
Some common log compaction issues include:
Slow compaction process
This may be due to insufficient resources allocated to the cleaner threads or improper configuration. Adjusting cleaner thread count or tweaking configuration parameters improve Kafka log compaction speed.
Excessive dirty segments
This may indicate that the log cleaner needs to be running or keeping up with the incoming data rate. Ensure that log cleaner is enabled, and consider adjusting the configuration parameters to trigger compaction more frequently.
Best practices for maintaining a healthy Kafka cluster
To maintain a healthy Kafka cluster with optimal log compaction performance, consider the following best practices:
- Regularly monitor key metrics related to log compaction for early detection of potential issues.
- Adjust log compaction configurations to suit your use case requirements and resource constraints.
- Ensure your Kafka cluster has adequate resources (memory, CPU, I/O) to efficiently handle the log compaction process.
[CTA_MODULE]
Conclusion
Kafka log compaction is a critical mechanism for managing log growth, ensuring optimal storage utilization, and maintaining the most recent state of records in Kafka-based systems. It helps to guarantee the stability, efficiency, and longevity of your Kafka systems by mitigating the impact of log growth on performance and resource consumption.
Optimizing log compaction for your specific use case involves balancing compaction frequency, resource consumption, and storage efficiency. By monitoring key metrics, configuring compaction settings appropriately, and following best practices for Kafka cluster maintenance, you can ensure your Kafka-based systems perform optimally and meet the demands of your specific use case.
[CTA_MODULE]