

Kafka logs—Concepts, configurations and policies











Kafka logs
Apache Kafka® is an open-source distributed streaming platform used to build high-performance streaming applications and data integration pipelines. It's highly durable and available, making it the default choice for developing streaming data applications. At its core, Kafka is an immutable log of messages distributed across multiple servers forming a cluster.
This article is about how Kafka log structure facilitates its reliable architecture and parameters related to Kafka logs that affect its performance. Let's start with the key concepts.
Summary of key concepts in Kafka logs
Kafka’s storage architecture handles data as an ordered log-based structure. Logs are partitioned, and partitions are replicated across multiple brokers to ensure fault tolerance. Developers tweak many parameters related to Kafka logs to balance performance and reliability.
Understanding Kafka storage architecture
Kafka’s working model consists of producers, consumers, topics, and a set of brokers deployed as a cluster.
- Producers are applications that produce messages.
- Consumers are client applications that fetch messages and apply business logic to them.
- Topics are logical groups of messages that belong to a specific use case.
- Kafka brokers are the machines that arrange transactions between producers and consumers.
A topic is broken into multiple partitions among one or more Kafka brokers for fault tolerance. The Kafka broker facilitates writing messages to partitions, serving messages, and replicating partitions. Brokers are purposefully kept simple and don’t execute any message-processing logic.
Kafka’s underlying storage architecture consists of log directories on broker instances organized based on topics and partitions. The partition folders contain log files divided into segments for better maintainability and performance. Segments ensure consumers don’t have to read from large partitions.
The contents of the Kafka partition folder are as below.
|── test-topic-0
├── 00000000000000000000.index
├── 00000000000000000000.log
├── 00000000000000000000.timeindex
├── 00000000000000001007.index
├── 00000000000000001007.log
├── 00000000000000001007.snapshot
├── 00000000000000001007.timeindex
├── leader-epoch-checkpoint[CTA_MODULE]
How Kafka logs work
Kafka designates one segment for a partition as active and writes all subsequent messages to that segment. The position of the message within the partition that must be sent to the consumer in the next read is called an offset. Each log segment has three important files associated with it.
Indexmaintains the mapping between messages and offset of the partition.Timeindexstores the mapping between messages and timestamps.Leader-epoch-checkpointcontains details of all previous leaders till then.
Additionally, the active segment has a snapshot file that stores the producer state information required when a new leader partition is elected. Snapshot file and leader epoch file are used to manage replication. For instance, the replica partitions use them to verify the current leader or elect a new one.
Kafka logs are not kept indefinitely. Kafka closes the log segment when a predetermined size is reached or a time interval has elapsed. Kafka deletes them according to the cleanup policy that is configured. It supports two cleanup policies - Delete and Compact. In the case of the ‘delete’ policy, Kafka deletes messages older than the configured retention time. In the case of the ‘compact’ policy, Kafka deletes all values other than the most recent value.
Configurations for Kafka logs
You can adjust various log settings to improve Kafka performance.
Log segment configurations
Engineers tweak segment parameters to optimize performance. The parameters:
log.segment.bytescontrols the size of the segment at which Kafka begins a new segment.log.roll.msorlog.roll.hourscontrol the time limit, after which Kafka rolls the segment.
The default value for log.segment.bytes is 1GB. The default value for log.roll.hours is seven days.
Kafka rolls the currently active segment and starts a new segment based on the time or size of the segments. If the producer is slow, you reduce the log.segment.bytes to roll the segments faster. In contrast, increasing the log.segment.bytes values help in accommodating more partitions in the same broker instance. A higher segment size results in a lower number of segment files and thereby stays well within the OS’s open file limitation.
Log retention configurations
Engineers set retention configuration parameters according to the durability guarantees required for their use cases. The parameters:
log.retention.bytescontrols the maximum log size that Kafka retains for a predetermined retention period.log.retention.ms, log.retention.minutes orlog.retention.hourscontrols the time up to which Kafka retains messages. The default time is seven days.
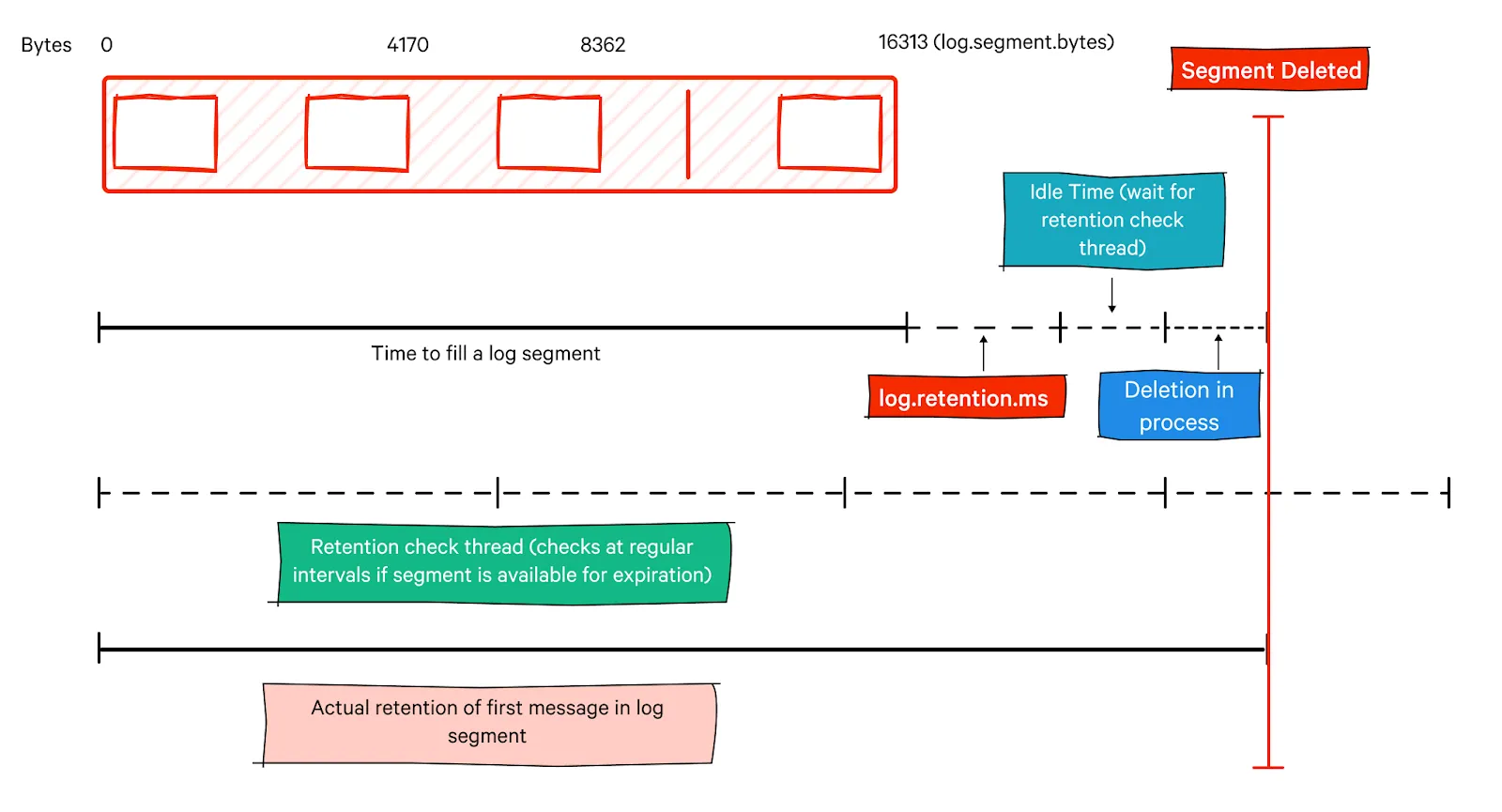
The time-based configuration parameters mentioned here represent the minimum time for Kafka message retention. In many scenarios, Kafka retains the messages for more than the configured time. Since Kafka retention is based on segments and not based on individual messages, the time configurations mentioned here apply to the last record in the segment. The earlier records in the same segment stay for much longer than the retention period, waiting for the segment to be deleted. Even after deletion is confirmed, the actual deletion happens only after a delay specified by the parameter, log.segment.delete.delay.ms.
[CTA_MODULE]
Log cleanup policies
Once the retention period is reached, the cleanup policy comes into the picture. Log cleanup policies determine the criteria for removing data from Kafka commit log to reclaim storage space. The cleanup policies are responsible for managing the retention of messages within individual segments and controlling the deletion process based on certain conditions.
The parameter log.cleanup.policy determines how expired log segments are managed. The allowed values are “delete” by default and “compact.”
It's worth noting that you can set log cleanup policies at the topic level, enabling fine-grained control over data retention strategies. Topics in Kafka can have different cleanup policies based on their specific requirements.
Delete cleanup policy
This is the default policy in Kafka. Under this policy, segments beyond the retention period defined by the topic's configuration are eligible for deletion. When a log segment expires according to the retention policy, it is marked for deletion, and the corresponding disk space is freed up.
The delete cleanup policy operates based on the segment's maximum timestamp. The entire segment is deleted if all the messages in a segment have a timestamp earlier than the retention threshold(log.retention.ms). This policy ensures that Kafka retains data for a specified duration but removes entire segments efficiently rather than deleting individual messages.
Compact cleanup policy
The compact cleanup policy aims to preserve the latest state of each key in the log while discarding older versions. Kafka retains the most recent message for each unique key within a segment and removes older versions of the same key. It is beneficial for scenarios where maintaining a compacted history of key-value pairs is essential, such as retaining a changelog or a materialized view.
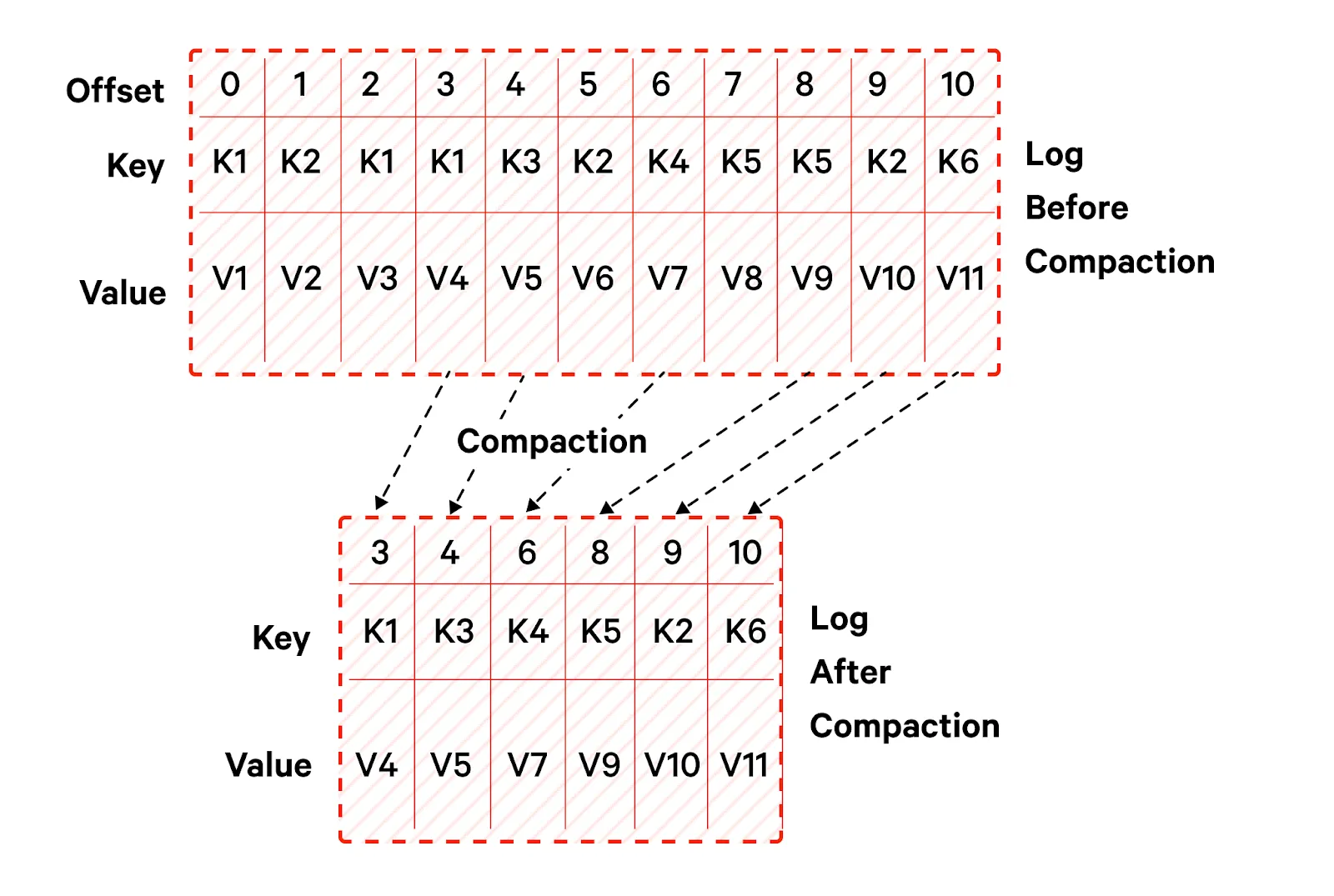
Compaction is based on the key of the messages, and messages with the same key are de-duplicated.
Log cleanup configurations
Developers can control the cleanup behavior using parameters like:
log.cleaner.delete.retention.mscontrols how long the records are retained after they are confirmed for deletion.log.cleaner.min.compaction.lag.msdefines the minimum age of the records that are subject to compaction.log.cleaner.max.compaction.lg.msdefines the maximum age of records that can remain in the system without compaction.
Setting lower values for the parameters helps trigger compaction in the case of producers with lower speeds.
[CTA_MODULE]
Conclusion
Kafka log-based storage structure is the foundation of its reliability and robustness. Kafka stores its log files in folders organized by topics and partitions. The index files help it map messages against offset and timestamps, enabling quick retrieval. The parameters related to segment rolling, log retention, and log compaction help engineers exert granular control over Kafka’s reliability and performance.
[CTA_MODULE]