

Streaming ETL—Tutorial & use cases











Streaming ETL
ETL (Extract, Transform, and Load) has been synonymous with Data Engineering and fundamentals for several decades. As a concept, it has been present since the late 70s and early 80s and has been widely used in the data ecosystem. It is typically a three-step process:
- Extract raw data (in various formats like CSV, JSON, TXT, etc) from different sources such as a database, files, and message queues.
- Transform the data using formatting, cleaning, normalization, and other techniques to convert it to a useful form for analysis and reporting.
- Load the data store, generally a warehouse or a columnar database.
In traditional data environments, this was done on a schedule in monolithic batches in a "batch ETL" process. Normally, batches ran daily, which made report data a day or so old. However, many modern businesses cannot wait days (or even hours) for batch processing. They need to respond to data in near real-time.
Thus the practice of streaming ETL emerged, making data immediately available to consumers, and has gradually become the dominant approach. This article will explore streaming ETL in detail: how it differs from the traditional batch ETL, the common use cases, and how we can use Kafka to set up a streaming ETL pipeline.
Summary of key streaming ETL concepts
Streaming ETL is evolving as more businesses identify value in using it to solve requirements where near real-time data is of great significance. The table below highlights a few key concepts and advantages contributing to its popularity.
Batch ETL vs. streaming ETL
Batch ETL is typically used when moving data from siloed subsystems (data sources owned by different teams/departments) to a central data warehouse. A delay of a few hours or even a few days is usually acceptable in these cases. In this process, we generally either wait for large volumes of data to accumulate or run it based on business rules (like the end of a day/month/workflow) before executing transformations and aggregations or moving the data to the target destination (the data lake or data warehouse).

Conceptually, a streaming ETL architecture (or real-time ETL architecture) is similar to batch ETL architecture with one major difference. Streaming ETL enables data to be automatically extracted and transformed, then loaded to any destination at the time of event creation. We have data sources that feed data to a stream processing platform. This platform serves as the backbone of ETL applications and many other types of streaming applications and processes. When the process completes, it can do one or more of the following:
- Push data to a target system (potentially a data warehouse).
- Send the result back to the source (with transformations).
- Simultaneously fan out this data to other applications and repositories to consume.
The advantage of a Streaming ETL is clear. There is a constant flow of data from source (raw data) to destination (final consumable data) as the data is created. It can handle millions of events at scale and in real-time, and can be used to populate data lakes or data warehouses, or to publish to a messaging system or data stream. One of the key tenets of stream processing or streaming ETL is that you are mixing stateful and stateless functionality in order to do higher order things.
[CTA_MODULE]
How to build a streaming ETL pipeline with Kafka
Apache Kafka® is a distributed streaming platform core of modern enterprise data architecture. It is usually the go-to choice for building real-time data pipelines and streaming applications. It is a high-throughput, low-latency platform that can handle millions of messages per second.
Kafka is an excellent choice for building a streaming ETL pipeline as it provides a single platform for data integration and processing in real-time at scale. There are several frameworks and APIs in the Kafka ecosystem that make it an ideal choice for building streaming ETL solutions. Over the years, it has matured to include all the essential components required for an end-to-end streaming system.
The tutorial below details how to use Kafka to build a streaming ETL pipeline.
Step 1: Extract data into Kafka
The first step involves getting data into Kafka topics. To facilitate this, Apache Kafka provides a component called Kafka Connect.
Kafka Connect is a free and open-source framework for connecting Kafka with external systems such as databases, key-value stores, search indexes, and file systems, using so-called Connectors. These connectors are ready-to-use components that can help us import data from external systems into Kafka topics and export data from Kafka topics into external systems. There are typically two types of connectors: source connectors and sink connectors.
A source connector collects data from a system like a database, streams tables, or message brokers. A source connector could also collect metrics from application servers into Kafka topics, making the data available for stream processing with low latency.
A sink connector dumps data from Kafka topics into other systems, such as batch systems like Hadoop, indexes such as Elasticsearch, or any database or data warehouse.
These connectors are designed to run as a service and expose REST endpoints for regular operations like creating a new connector, listing existing connectors, deleting a connector, etc.
Step 2: Transform data using Kafka Streams
The Kafka ecosystem has a component called Kafka Streams. It is a data processing and transformation client library within Kafka for building applications and microservices, where the input and output data are stored in Kafka clusters.
Kafka Streams provide rich APIs to perform fast and efficient aggregations and joins at low latency, and can seamlessly handle out-of-order data as well - thus making it a great candidate for the Transform layer of the Streaming ETL paradigm. The stream processor receives one record at a time, processes it, and can produce one or more output records for downstream processors. It can transform messages one at a time, filter them based on some conditions, or perform aggregations on multiple messages.
Below is a sample implementation for a Kafka Streams application that counts the number of words in a stream of text lines:
import org.apache.kafka.common.serialization.Serdes;
import org.apache.kafka.common.utils.Bytes;
import org.apache.kafka.streams.KafkaStreams;
import org.apache.kafka.streams.StreamsBuilder;
import org.apache.kafka.streams.StreamsConfig;
import org.apache.kafka.streams.kstream.KStream;
import org.apache.kafka.streams.kstream.KTable;
import org.apache.kafka.streams.kstream.Materialized;
import org.apache.kafka.streams.kstream.Produced;
import org.apache.kafka.streams.state.KeyValueStore;
import java.util.Arrays;
import java.util.Properties;
public class StreamingWordCountApplication {
public static void main(final String[] args) throws Exception {
Properties props = new Properties();
props.put(StreamsConfig.APPLICATION_ID_CONFIG, "streaming-word-count-app");
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "kafka-broker-1:9092");
props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());
StreamsBuilder builder = new StreamsBuilder();
KStream<String, String> textLines = builder.stream("text_lines");
KTable<String, Long> wordCounts = textLines
.flatMapValues(line -> Arrays.asList(line.toLowerCase().split("\\W+").trim()))
.groupBy((key, word) -> word)
.count(Materialized.<String, Long, KeyValueStore<Bytes, byte[]>>as("words-counts-store"));
wordCounts.toStream().to("words_with_count", Produced.with(Serdes.String(), Serdes.Long()));
KafkaStreams streams = new KafkaStreams(builder.build(), props);
streams.start();
}
}This is a straightforward problem statement, but it is interesting to imagine how enterprises can use operations like map, group, and count provided by the Streams API to implement various complicated stream processing use cases. For example, we can consume a stream of retail product sales data and apply similar logic to get counts of products sold in real time. This data can then be used to offer discounts on low-selling retail items to boost their sales in near real-time.
Step 3: Load data into a destination system
Finally, the data in Kafka topics needs to be put into a target system. This is usually a Data Warehouse or a Data Lake. Sink Connectors can now be configured to stream this data into the warehouse. This data is now available for reporting and analytics.
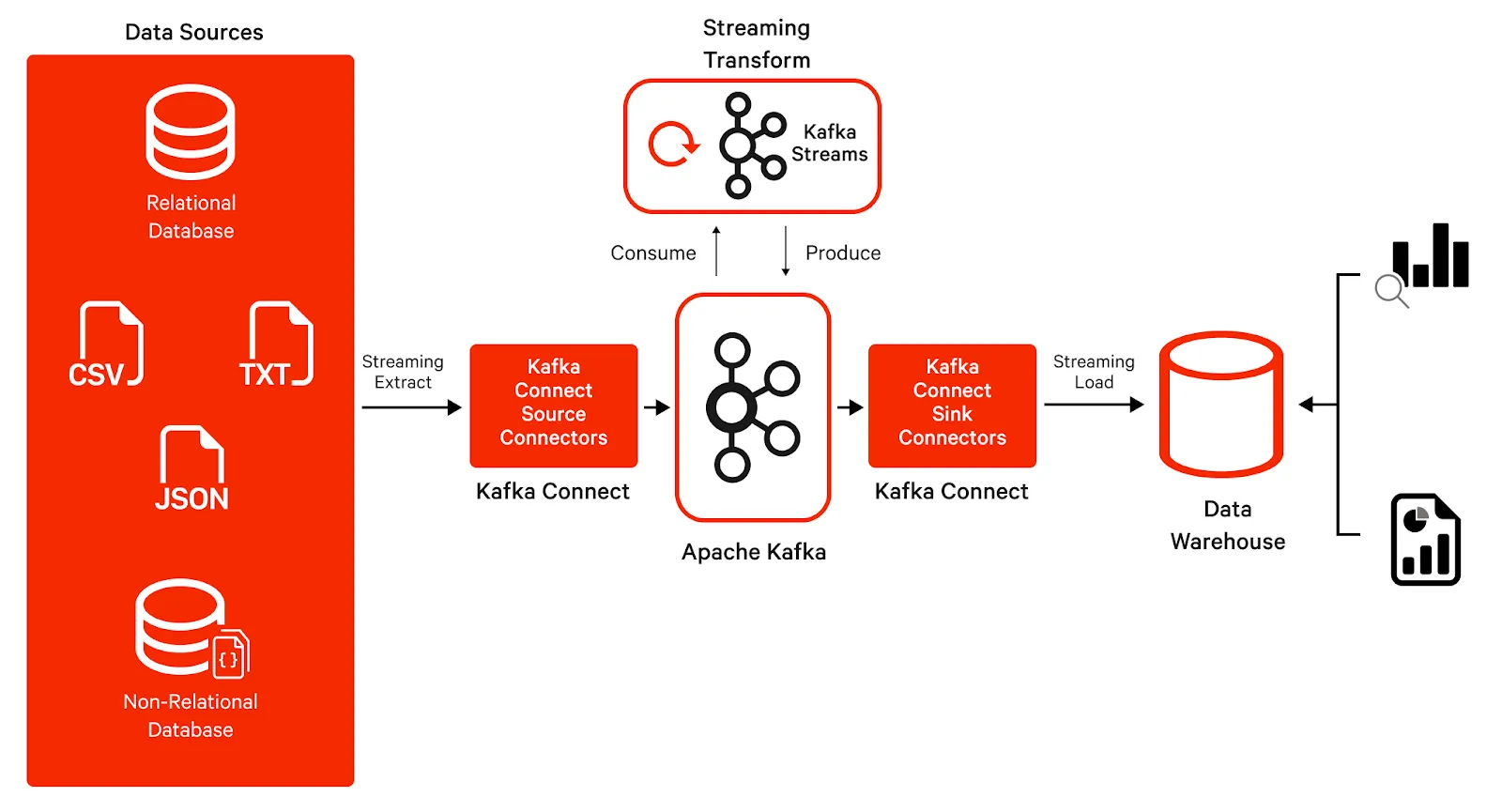
As we can see, building a streaming ETL requires a good knowledge of Kafka as well as some other components of the Kafka ecosystem (Kafka Connect and Kafka Streams).
[CTA_MODULE]
Real-world streaming ETL use cases
Now we will look at some real-world applications for streaming ETL.
Fraud detection in finance
When you use a credit card or carry out an online payment, the transaction data is consumed by the fraud detection application as soon as the payment is made. The application then uses historical trends in your spending habits like the vendor, amount, location, and other data points and applies fraud detection algorithms. This can differentiate a fraudulent activity from a genuine one, and the user can be notified about it in seconds after the transaction so that proper measures can then be taken.
Healthcare wearables
Wearable devices continuously emit data points about an individual's vitals (heartbeat, blood pressure, etc.). Anomalies can be identified and acted upon to potentially help save a person’s life.
Real-time customer interactions
Imagine an e-commerce application. A customer might browse the products and then navigate to a checkout screen. These interactions are sent to a streaming ETL engine for processing and transformation into an actionable format. The data might suggest that the customer is comparison shopping and might be ready to churn. In this scenario, the marketing team can instantly notify their device with a special discount offer for her. This might encourage the user to complete checkout and help increase conversion.
Internet of Things (IoT)
Like wearables, various IoT devices produce thousands of data points in real-time to be used for further processes to run. For example, temperature and humidity sensors for crops, energy monitors, and smart security systems. Streaming ETL makes it possible to gather all these data points in real-time, clean and process them & finally transfer those to a destined data store to drive some value.
Streaming ETL challenges
Streaming ETL undoubtedly solves many modern-day data problems, but running a production-grade streaming pipeline comes with its own set of challenges.
System reliability
Streaming applications that form the transport layer of ETL are always running. These long-running data processing systems must be resilient to failures to avoid any downtime and ensure high availability. Additionally, unforeseen unusual activities (e.g., failures in upstream components, traffic spikes, etc.) must be continuously monitored and resolved to deliver insights in real time.
Late and out-of-order data
Suppose a source data, D1, is produced at time T1 and another data, D2, is produced at time T2 (where T1 < T2). Late or out-of-order data refers to when D1 is consumed (extracted) after D2. This is common in the real world. As a result, aggregations and other complex computations must be continuously (and accurately) revised as new information arrives.
Complex transformations
Data arrives in various formats like CSV, JSON, Avro, etc. This often must be restructured and transformed before being consumed. Such restructuring requires that all the traditional tools from batch processing systems are also available in the streaming clients, but without any latency. Other operations like table lookups, joins, etc., that are relatively simpler in traditional batch ETL transformations might be complicated to implement in the streaming world.
Data quality and correctness
In traditional systems, Data QC (quality check) jobs could run once every day (or some other fixed schedule as per ETL job schedule) to check data quality and correctness. With streaming architecture, data is continuously flowing into target systems, and it presents a new challenge that requires continuous checks for bad data and incorrect reporting.
Conclusion
The industry is shifting towards real-time data. Businesses today are moving fast. Enterprises can derive significant business value by making instant data-backed decisions, and streaming ETL fits the bill for these cases.
Kafka is an excellent tool for building such streaming pipelines. It provides connectors within the Kafka Connect framework to extract data from different sources, the rich Kafka Streams API that performs complex transformations and analysis from within your core applications, and more Kafka connectors to load transformed data to another system.
[CTA_MODULE]