

Kafka Partition Strategies: A Comprehensive Tutorial











Kafka partition strategy
Apache Kafka® groups related messages into topics, allowing consumers and producers to categorize messages. At a lower level, topics can be broken down into partitions, which is how a single topic can span across multiple brokers.
This Apache Kafka partition structure plays a key role in system performance, as the choice of Kafka partition assignment strategy and use of an appropriate partition key directly impact how data is distributed and consumed. Kafka lets you choose how producers should publish messages to partitions and how partitions are assigned to consumers. However, there are multiple ways to route messages to different topic partitions. Each strategy comes with its own pros and cons, and learning which strategy is optimal for a certain circumstance differentiates Kafka experts from newbies.
In this article, we’ll show you the major strategies for allocating a topic’s messages to partitions. Then, we’ll give you an in-depth understanding of the theory behind how these message ordering strategies work using simple language and diagrams. Finally, we’ll walk you through different strategies, using real code samples to help you understand the practical implications of each partitioning and data processing approach.
Brief summary of Kafka partition assignment strategies
Partitions increase parallelization and allow Kafka to scale. As we mentioned before, many strategies exist for distributing messages to a topic’s partitions. Before we dive deeper into the background of each strategy, the table below gives a brief overview of each Kafka partition assignment strategy.
A Kafka message is sent by a producer and received by consumers. The strategies differ between the two, so we have two tables below, one summarizing each strategy.
Producer partition strategies
| Strategy | Description |
|---|---|
| Default partitioner | The key hash is used to map messages to partitions. Null key messages are sent to a partition in a round-robin fashion. |
| Round-robin partitioner | Messages are sent to partitions in a round-robin fashion. |
| Uniform sticky partitioner | Messages are sent to a sticky partition (until the batch.size is met or linger.ms time is up) to reduce latency. |
| Custom partitioner | This approach implements the Partitioner interface to override the partition method with some custom logic that defines the key-to-partition routing strategy. |
Consumer assignment strategies
| Strategy | Description |
|---|---|
| Range assignor (default) | (Total number of partitions) / (Number of consumers) partitions are assigned to each consumer. The aim is to have co-localized partitions, i.e., assigning the same partition number of two different topics to the same consumer (P0 of Topic X and P0 of Topic Y to the same consumer). |
| Round-robin assignor | Partitions are picked individually and assigned to consumers (in any rational order, say from first to last). When all the consumers are used up but some partitions still remain unassigned, they are assigned again, starting from the first consumer. The aim is to maximize the number of consumers used. |
| Sticky assignor | This approach works similar to round robin assignor but preserves as many existing assignments as possible when reassignment of partitions occurs. The aim is to reduce or completely avoid partition movement during rebalancing. |
| Custom assignor | Extends the AbstractPartitionAssignor class and overrides the assign method with custom logic. |
[CTA_MODULE]
Producer partitioning strategies
Producers are applications that write data to partitions in Kafka topics. Kafka provides the following partitioning strategies when producing a message.
Default partitioner
As the name suggests, this is the default strategy for producing messages. When the key is null, the record is sent randomly to one of the available partitions of the topic. If a key exists, Kafka hashes the key, and the result is used to map the message to a specific partition. This method helps preserve message ordering by ensuring messages with the same key end up in the same partition. This mapping, however, is consistent only as long as the number of partitions in the topic remains the same: If new partitions are added, new messages with the same key might get written to a different partition than old messages with the same key.

Round robin partitioner
Use this approach when the producer wants to distribute the writes equally among all partitions. This distribution is irrespective of the key’s hash value (or the key being null), so messages with the same key can end up in different partitions.

This Kafka partitioning strategy is useful when the workload becomes skewed by a single key, meaning that many messages are being produced for the same key. Suppose the ordering of messages is immaterial and the default partitioner is used. In that case, imbalanced load results in messages getting queued in partitions and an increased load on a subset of consumers to which those partitions are assigned. The round-robin strategy will result in an even distribution of messages across partitions, helping to improve performance by balancing load across the Kafka cluster.
Uniform sticky partitioner
Currently, when no partition and key are specified, a producer’s default partitioner partitions records in a round-robin fashion. That means that each record in a series of consecutive records will be sent to a different partition until all the partitions are covered, and then the producer starts over again. While this spreads records out evenly among the partitions, it also results in more batches that are smaller in size, leading to more requests and queuing as well as higher latency.

The uniform sticky partitioner was introduced to solve this problem. It has two rules:
- If a partition is specified with the record, that partition is used as it is.
- If no partition is specified, a sticky partition is chosen until the batch is full or linger.ms (the time to wait before sending messages) is up.
“Sticking” to a partition enables larger batches and reduces latency in the system. After sending a batch, the sticky partition changes. Over time, the records are spread out evenly among all the partitions.
The record key is not used as part of the partitioning strategy, so records with the same key are not guaranteed to be sent to the same partition.
Custom partitioner
Sometimes a use case does not fit well with any of the standard partitioners. For example, let’s suppose we want to write transaction log data to Kafka and one of the users (called “CEO”) accounts for more than 40% of all transactions.
If default hash partitioning is used, the “CEO” user’s records will be allocated to the same partition as other users. This would result in one partition being much larger than the rest, leading to brokers running out of space and processing slowing down. An ideal solution is giving the user “CEO” a dedicated partition and then using hash partitioning to map the rest of the users to the remaining partitions. Below is a simple implementation for this use case:
[CTA_MODULE]
Apache Kafka consumers and consumer groups
Consumers are applications that read data from Kafka. Usually, we have multiple producers writing messages to a topic, so a single consumer reading and processing data from the topic might be unable to keep up with the rate of incoming messages and fall further and further behind. To scale consumption from topics, Kafka has a concept called consumer groups. As the name suggests, a consumer group is just a bunch of consumers. When multiple consumers in a consumer group subscribe to the same topic, each consumer receives messages from a different set of partitions in the topic, thus distributing data among themselves.
The only caveat is that one partition can only be assigned to a single consumer. Adding more consumers to a group helps scale consumption. However, if you have more consumers than partitions, some of the consumers will remain idle because there won’t be any partitions left for them to feed on. This idle consumer acts as a failover consumer, allowing it to quickly pick up the slack if an existing consumer fails.
Consumer partition assignment
Just as we can control how to write data to partitions in a topic, Kafka also allows us to decide how consumers read data from these partitions. We can configure the strategy that will be used to assign the partitions among the consumer instances. The property “partition.assignment.strategy” can be used to configure the assignment strategy while setting up a consumer.
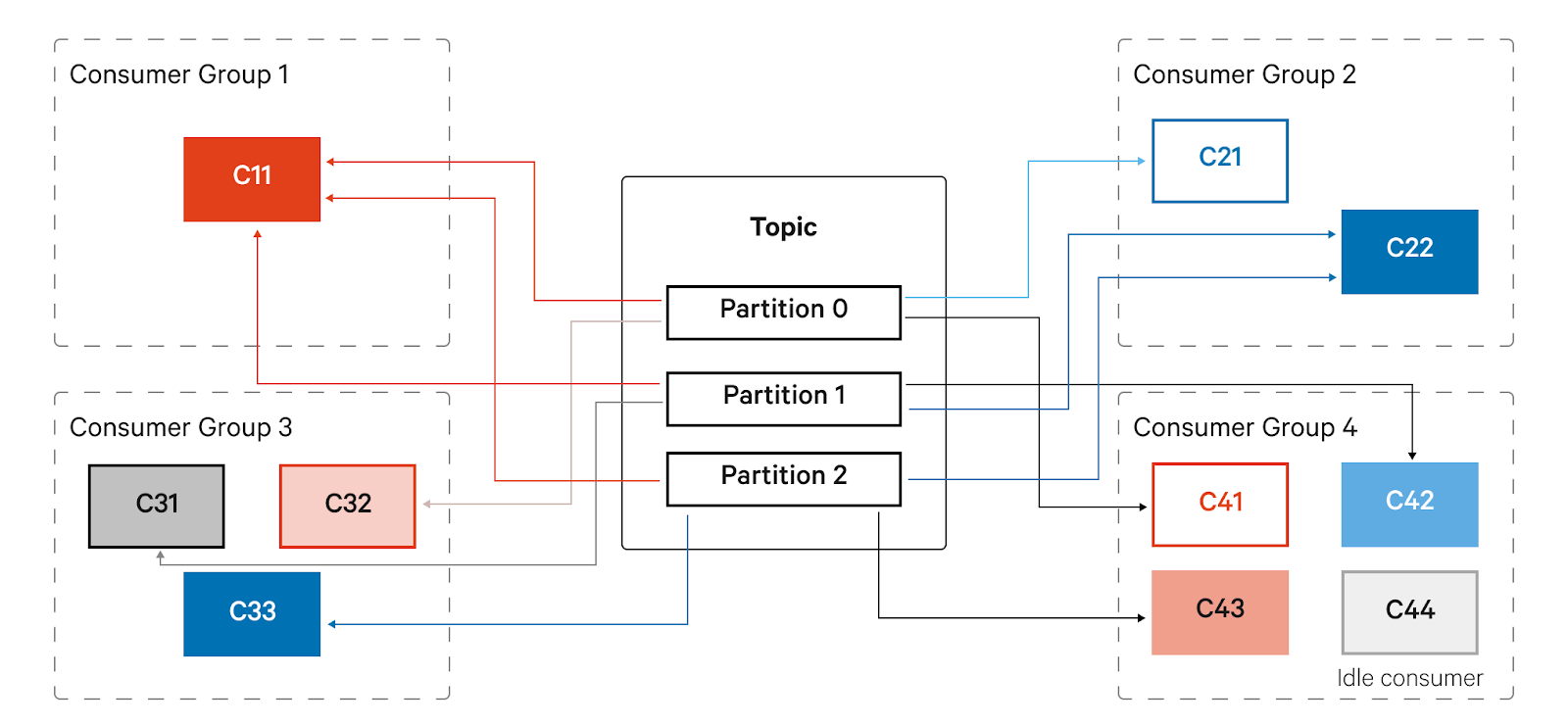
The following are some strategies for consumer partition assignment:
- Range assignor: This is the default strategy and works on a per-topic basis. For each topic, the available partitions are considered in numeric order and the consumers in lexicographic order. The number of partitions is then divided by the consumer count to determine the number of partitions to assign to each consumer. If it does not evenly divide, the first few consumers will have an extra partition.
- Round robin assignor: This takes all the partitions and assigns them to the consumers in a round-robin fashion. The advantage here is that it aims to maximize the number of consumers used. However, due to this, it cannot reduce partition movement in case of rebalancing.
- Sticky assignor: This works pretty similarly to a round-robin assignor but has an added advantage because it preserves as many existing assignments as possible when reassignment of partitions occurs. This helps in saving some of the overhead processing when topic partitions move from one consumer to another during a rebalance (discussed in a later section).
- Custom assignor: It is also possible to write custom logic for an assignor. Below is an example where failover is handled based on a priority assigned to consumers
This custom assigner can then be used while initializing the consumer.
Consumer rebalancing
Consumers can either be added to or removed from a consumer group from time to time. When a new consumer is added, it starts consuming messages from partitions previously assigned to a different consumer. Similarly, when a consumer is removed, its partitions are assigned to another remaining active consumer. This reassignment and moving partition ownership from one consumer to another is called rebalancing. Rebalances are critical as they provide high availability and scalability, allowing users to add and remove consumers safely.
There are two types of rebalances. Which one you use depends on the partition assignment strategy used by the consumers:
- Eager rebalancing: All the consumers stop consuming, give up ownership of their partitions, rejoin the group, and then get new partitions assigned to them. This causes a small window of downtime (consumer unavailability) when there are no consumers in the entire group.
- Cooperative rebalancing: Also called incremental rebalancing, this strategy performs the rebalancing in multiple phases. It involves reassigning a small subset of partitions from one consumer to another, allowing consumers to continue processing messages from partitions that are not reassigned and avoiding total unavailability.
In the normal course of events, rebalances can be undesirable. During a rebalance, consumers stop processing messages for some period of time, which causes a delay in the processing of events from the topic. This can be problematic for use cases that require real-time event processing and cannot afford delays of more than a few seconds.
Kafka provides an interesting way to avoid this rebalancing altogether.
Static group membership
The default consumer rebalancing behavior is that consumer identity in a group is transient. When a consumer leaves the group, its partitions are revoked; when it rejoins, it gets a new member ID, and a new set of partitions is assigned to it.
It is possible to make a consumer a static group member by configuring it with a unique “group.instance.id” property. When it joins a group, a set of partitions is assigned to it according to the partition assignment strategy used. However, it does not automatically leave the group when it restarts or shuts down—it remains a member. On rejoining, it is recognized with its unique static identity and reassigned to the same partitions it consumed without triggering a rebalance.
This is useful for stateful applications where the state is populated by the partitions assigned to the consumer. As this process could be time-consuming, it is not ideal to recreate this initial state or cache every time the consumer restarts.
Choosing the right Apache Kafka partitioning strategy for performance and scalability
We have seen how finding the right partitioning strategy is essential both from the producer and the consumer's point of view. If not configured properly, this can become an issue in the long run. The decision largely depends on the nuances of the use case, the volume of data, etc., and no single method solves every problem.
The default options might work for most cases, but sometimes they are not the right choice. For example, if ordering is not necessary on the producer side, round-robin or uniform sticky strategies perform significantly better. Similarly, on the consumer side, choosing the default range assignor for a use case, as discussed in our transaction log example (skewed load), may lead to unwanted rebalancing and slow processing.
Custom partitioners and assignors are allowed, but they are not straightforward and require in-depth technical understanding to implement properly. Finding the right strategy is a crucial step in reaping the benefits of speed and scalability that Kafka provides.